TensorFlow实战(四)- 使用TensorFlow实现去噪自编码器
一,自编码器简介
1,什么是自编码器
自编码器,顾名思义,即可以使用自身的高阶特征编码自己。
自编码器其实是一种神经网络,它的输入和输出是一致的,它借助稀疏编码的思想,目标是使用稀疏的一些高阶特征重新组合来重构自己。特征如下:
- 期望输入和输出一致。
- 希望使用高阶特征来重构自己,而不只是复制像素点。
如下图所示:
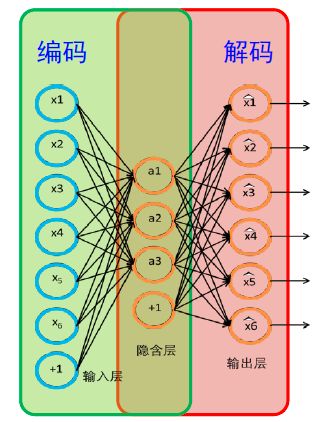
因为自编码器希望使用少量稀疏的高阶特征来重构输入,所有有几种限制:
- 隐含层的节点要小于输入层的节点,相当于一个降维的过程。
- 如果给数据加入噪声,那么就是去噪自编码器,我们将从含噪声的数据中学习出数据的高阶特征。常用噪声有加性高斯噪声(Additive Gaussian Noise)和随机遮挡噪声(Masking Noise)。
如果自编码器的隐含层只有一层,那么其原理类似于主成分分析。
2,应用
自编码器是一种无监督学习,主要应用有:
- 利用自编码器对数据进行降维。
- 可以用来对很深的网络进行无监督的预训练,来找到一个较好的权重初始化值,可以解决梯度消失问题。
例如,Hinton在DBN中的思想就是:先用自编码器的方法进行无监督的预训练,提取到一些有用的特征,从而将神经网络的权重初始化到一个较好的分布,然后再使用标注信息进行监督式的训练,即对权重进行fine-tune
虽然现在无监督式的预训练使用场景比以前少了许多,但因为现实世界中数据最多的还是未标注的数据,因此自编码器仍是非常有用的!
主要有以下几种自编码器,作用各部相同:
- 稀疏自编码器
- 去噪自编码器
- 压缩自编码器
- 栈式自编码器
二,用TensorFlow实现AGN自编码器
前提知识
- 需要使用Scikit-learn中preproces模块中的数据标准化功能。
- 用到xavier initialization参数初始化方法,它的特点是会根据某一层网络的输入、输出节点的数量自动调整最合适的分布。 xavier就是让权重满足均值为0,方差为 2输入节点数+输出节点数 2 输 入 节 点 数 + 输 出 节 点 数 ,分布可以为均匀分布或者高斯分布。
- 激活函数使用softplus,它是平滑版的Relu激活函数。
tensorflow实现
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# xavier initializaton参数初始化方法
def xavier_init(fan_in,fan_out,constant=1):
low = -constant*np.sqrt(6.0/(fan_in+fan_out))
high = constant*np.sqrt(6.0/(fan_in+fan_out))
return tf.random_uniform((fan_in,fan_out),minval=low,maxval=high,dtype=tf.float32)
class AdditiveGaussianNoiseAutoEncoder(object):
def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,
optimizer=tf.train.AdamOptimizer(),scale=0.1):
# 1,定义一些必需的参数
self.n_input = n_input
self.n_hidden = n_hidden
self.transfer = transfer_function
self.scale = tf.placeholder(tf.float32)
self.training_scale = scale
networks_weights = self._initialize_weigths()
self.weights = networks_weights
# 2,定义网络结构
self.x = tf.placeholder(tf.float32,[None,self.n_input])
self.hidden = self.transfer(tf.add(tf.matmul(self.x+scale*tf.random_normal((n_input,)),self.weights['w1']),self.weights['b1']))
self.reconstruction = tf.matmul(self.hidden,self.weights['w2'])+self.weights['b2']
# 3,定义损失函数和优化器
self.cost = 0.5*tf.reduce_sum(tf.pow((self.reconstruction-self.x),2.0))
self.optimizer = optimizer.minimize(self.cost)
# 4,全局参数初始化
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.sess.run(init)
def _initialize_weigths(self):
all_weigths = dict()
all_weigths['w1'] = tf.Variable(xavier_init(self.n_input,self.n_hidden),dtype=tf.float32)
all_weigths['b1'] = tf.Variable(tf.zeros([self.n_hidden],dtype=tf.float32))
all_weigths['w2'] = tf.Variable(tf.zeros([self.n_hidden,self.n_input]),dtype=tf.float32)
all_weigths['b2'] = tf.Variable(tf.zeros([self.n_input],dtype=tf.float32))
return all_weigths
# 单步训练
def partial_fit(self,X):
cost,opt = self.sess.run([self.cost,self.optimizer],feed_dict={self.x:X,self.scale:self.training_scale})
return cost
# 计算cost,用来测试模型效果
def calc_total_cost(self,X):
return self.sess.run(self.cost,feed_dict={self.x:X,self.scale:self.training_scale})
# 编码
def transform(self,X):
return self.sess.run(self.hidden,feed_dict={self.x:X,self.scale:self.training_scale})
# 解码
def generate(self,hidden=None):
if hidden==None:
hidden = np.random.normal(size = self.weigths['b1'])
return self.sess.run(self.reconstruction,feed_dict={self.hiddne:hidden})
# 重构,包括编码和解码两个过程
def reconstruct(self,X):
return self.sess.run(self.reconstruction,feed_dict={self.x:X,self.scale:self.training_scale})
def getWeights(self):
return self.sess.run(self.weights['w1'])
def getBiases(self):
return self.sess.run(self.weights['b1'])
def pltTwo(self):
import matplotlib.pyplot as plt
r = np.random.randint(0, mnist.test.num_examples - 1)
fig = plt.figure()
ax = fig.add_subplot(121)
bx = fig.add_subplot(122)
ax.imshow(mnist.test.images[r:r + 1].reshape(28, 28), cmap='Greys', interpolation='nearest')
bx.imshow(self.reconstruct(mnist.test.images[r:r + 1]).reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.show()
# 数据标准化
def standard_scale(X_train,X_test):
preprocessor = prep.StandardScaler().fit(X_train)
X_train = preprocessor.transform(X_train)
X_test = preprocessor.transform(X_test)
return X_train,X_test
# 获取随机block数据
def get_random_block_form_data(data,batch_size):
start_index = np.random.randint(0,len(data)-batch_size)
return data[start_index:(start_index+batch_size)]
if __name__=='__main__':
# 1,获取数据并标准化
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
X_train,X_test = standard_scale(mnist.train.images,mnist.test.images)
# 2,定义一些训练参数
n_samples = int(mnist.train.num_examples)
training_epochs = 20
batch_size = 128
display_step = 1
# 3,构建去噪自编码器模型,包括网络结构的定义,loss和优化器的定义等
autoencoder = AdditiveGaussianNoiseAutoEncoder(n_input=784,
n_hidden=200,
transfer_function=tf.nn.softplus,
optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
scale=0.01)
# 4,迭代训练
for epoch in range(training_epochs):
avg_cost = 0.0
total_batch = int(n_samples/batch_size)
for i in range(total_batch):
batch_xs = get_random_block_form_data(X_train,batch_size)
cost = autoencoder.partial_fit(batch_xs)
avg_cost += cost/n_samples*batch_size
if epoch % display_step == 0:
print('Epoch: %04d,cost=%.9f' % (epoch+1,avg_cost))
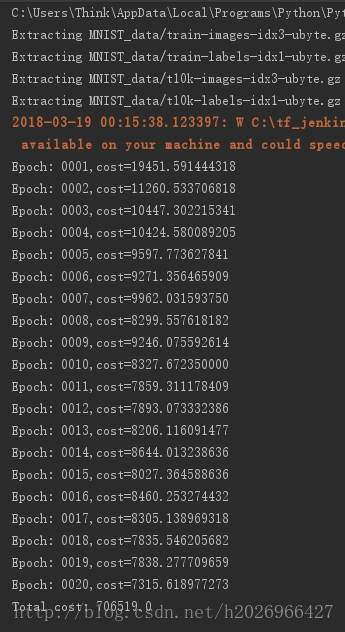
# 5,测试
print('Total cost: '+str(autoencoder.calc_total_cost(X_test)))
# 6,原始图和重构图的对比
autoencoder.pltTwo()运行结果如下图所示:
原始图和重构图的对比:
