【前沿技术】浅析搜狗AI主播背后的核心技术
文章首发于微信公众号《有三AI》
【前沿技术】浅析搜狗AI主播背后的核心技术
今天是新专栏《前沿技术》,技术的更新迭代实在是太快了,我将在这个专栏给大家解读学术界/工业界最新的成果背后的技术原理,定位读者为对技术感兴趣的本行和外行。
这一个专栏将具有以下几个特点:
(1) 内容以科普为主,技术细节为辅。因为本专栏是为了让更多的人能够看懂,完成对新奇技术的了解,我不会在这里讲述过多技术细节,细节可以通过其他专栏获得。
(2) 暂定每周一篇,毕竟《有三AI》是技术学习平台,不是新闻信息平台。我们一直追求系统性,不太喜欢讲孤立的知识。
作者&编辑 | 言有三,微信Longlongtogo
今天主题是AI主播
人大二次会议正在召开中,对我们AI从业者来说,最大的技术新闻莫过于“AI主播”又现身了,再一次展现了搜狗的AI落地能力。上面就是声音和外形模仿新华社新媒体中心新闻主播屈萌的AI主播。
那些赞赏的话我们就不说了,下面就来简单剖析下其中的一些核心技术,真的只是简单剖析,笔者没有完整性参与过这类项目。
搜狗的这套系统据说只需要5~7分钟就可以学习到个人的音色,AI主播也只是需要录制一个半小时左右的数据,就实现了人类主播级别的语言流畅的新闻播报。
背后涉及了图像,语音,自然语言处理等技术的融合,下面分别进行简单介绍。
1 图像技术
首先来说一下图像技术,主要涵盖三维重建,表情合成,唇语合成等。
1、三维重建
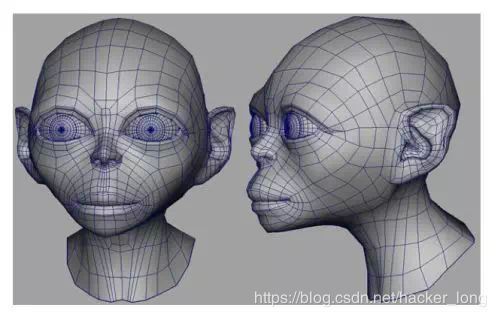
首先要有一个与真人长得一摸一样的AI模型出来,然后才能在这个模型上进行渲染。要建立一个这样的模型,肯定是需要真人主播的主动参与的,目前的图像技术还不可能任意重建一个人的高精度3D模型。对于AI主播这样的应用场景,完全可以利用扫描仪进行真人的三维数据的采集完成建模。
既然说到了三维建模,那么就稍微展开一点讲。
什么是三维重建呢?广义上来说,是建立真实世界的三维模型。随着软硬件的成熟,在电影,游戏,安防,地图等领域,三维重建技术的应用越来越多。目前获取三维模型的方法主要包括三种,手工建模,仪器采集与基于图像的建模。
(1) 手工建模作为最早的三维建模手段,现在仍然是最广泛地在电影,动漫行业中应用。顶顶大名的3DMax就是典型代表,当然了,它需要专业人士来完成。
(2) 由于手工建模耗费大量的人力,三维成像仪器也得到了长期的研究和发展。基于结构光(structured light)和激光扫描技术的三维成像仪是其中的典型代表。这些基于仪器采集的三维模型,精度可达毫米级,是物体的真实三维数据,也正好用来为基于图像的建模方法提供评价数据库。由于仪器的成本太高,一般的用户是用不上了。
(3) 基于图像的建模技术(image based modeling),顾名思义,是指通过若干幅二维图像,来恢复图像或场景的三维结构,这些年得到了广泛的研究。
这里面具有研究意义的就是基于图像的三维重建方法了,由于问题复杂目前集中在人脸图像的三维重建,人脸三维重建方法非常多,有基于一个通用的人脸模型,然后在此基础上进行变形优化,会牵涉到一些模板匹配,插值等技术。有基于立体匹配(各种基于双目,多目立体视觉匹配)的方法,通过照相机模型与配准多幅图像,坐标系转换,获取真实的三维坐标,然后进行渲染。有采用一系列的人脸作为基,将人脸用这些基进行线性组合的方法,即Morphable models方法。
其中,能够融会贯通不同传统方法和深度学习方法的,就是3D Morphable Models系列方法,从传统方法研究到深度学习都用它。
它的思想就是一幅人脸可以由其他许多幅人脸加权相加而来,这些脸都叫“正交基”,学过线性代数的就很容易理解这个正交基的概念。我们所处的三维空间,每一点(x,y,z)实际上都是由三维空间三个方向的基量(1,0,0),(0,1,0),(0,0,1)加权相加所得,只是权重分别为x,y,z。
转换到三维空间,道理也一样。每一个三维的人脸,可以在一个数据库中的所有人脸组成的基向量空间中进行表示,而求解任意三维人脸的模型,实际上等价于求解各个基向量的系数的问题。
最原始的3DMM模型将每一张人脸表示为:
形状向量Shape Vector:S=(X1,Y1,Z1,X2,Y2,Z2,...,Yn,Zn)
纹理向量Texture Vector:T=(R1,G1,B1,R2,G2,B2,...,Rn,Bn)

一张任意的人脸,其等价的描述如下:
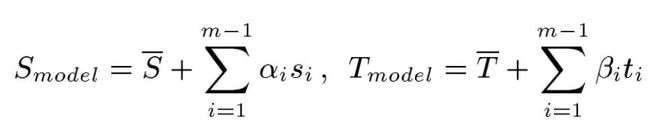
其中第一项Si,Ti是形状和纹理的平均值,而si,ti则都是Si,Ti减去各自平均值后的协方差矩阵的特征向量。 基于3DMM的方法,都是在求解α,β这一些系数,当然现在还会有表情,光照等系数,但是原理都是通用的。简单原理就说到这里,我们以后会专门讲述。
人脸的三维建模有一些独特的特点。
(1) 预处理技术非常多,人脸检测与特征点定位,人脸配准等都是现在研究已经比较成熟的方法。利用现有的人脸识别与分割技术,可以缩小三维人脸重建过程中需要处理的图像区域,而在有了可靠的关键点位置信息的前提下,可以建立稀疏的匹配,大大提升模型处理的速度。
(2) 人脸共性多。正常人脸都是一个鼻子两只眼睛一个嘴巴两只耳朵,从上到下从左到右顺序都不变,所以可以首先建立人脸的参数化模型,实际上这也是很多方法所采用的思路。
人脸三维重建也有一些困难。
(1) 人脸生理结构和几何形状非常复杂,没有简单的数学曲面模型来拟合。
(2) 光照变化大。同一张脸放到不同的光照条件下,获取的图像灰度值可能大不一样的,这些都会影响深度信息的重建。
(3) 特征点和纹理不明显。图像处理最需要的就是明显的特征,而光滑的人脸除了特征关键点,很难在脸部提取稠密的有代表性的角点特征。这个特点,使得那些采用人脸配准然后求取三维坐标的方法面临着巨大的困难。
2、表情合成
前面说到了三维人脸的重建,人脸的整个三维模型可以剥离为表情,形状,纹理等各个维度。这里因为主播是一个限定场景的应用,形状,纹理的变动很小,而表情则是需要进行精确建模的,我们能感受到上面的这个主播在表情方面其实还有很多不逼真的地方。
表情合成,就是建立在上面的人脸重建的基础之上。如果以后谁能发布一个低成本的建立自己的3D形象的应用,那一定是解决了基于图像的三维重建问题,现在还没有。
表情合成采用的思路就是通过调整各个表情基向量的系数。
下面就是苹果的一套表情系数中的一个,表情包括的东西是很多的,眼睛鼻子嘴巴的动作都算,当然对于主播这样严肃的场景,基本上都是嘴唇动作为主。

将各种不同的表情进行叠加,就得到了基本的表情,在iphone X的表情生成功能的背后,就是这样的原理。它不需要非常精确的重建模型,只需要表情的系数比较准确即可。

3、唇语合成
可能有的小伙伴会问,这不是有表情驱动来做嘴唇动作了吗,唇语合成又是做什么的呢?一句话,需要做的更准。

首先要说一下唇语识别,所谓唇语识别,即通过图像识别捕捉人的嘴唇运动,曾经牛津大学人工智能实验室、谷歌 DeepMind 和加拿大高等研究院 (CIFAR) 联合发布了一篇很著名的唇语合成的文章LipNet,被ICLR拒掉的,想必大家还记得,当时怼得火药味十足。到现在唇语识别的技术很显然更进了一步,参考搜狗的知音。
没有唇语合成行不行?前面说了主播这样的应用基本上都是嘴唇动作,而表情合成的结果是针对整个面部的,唇语合成是专门针对嘴唇,而且跟文本内容、语音、发音方式等都有关系,不是一个单一的输入。
对于唇语合成,大家可以多关注一下学术界对奥巴马同志的关照,下面的就是同一段嘴唇动作在不同的视频上的合成,用的是纯语音的输入。

为什么选奥巴马?大家可以思考一下深度学习任务中最重要的是什么。
2 NLP与语音技术
1、语音合成
主播这里只需要单方面输出新闻,所以用到的NLP技术比不上聊天机器人微软小冰等需要的多,因为与语音合成的流程嵌套了,就放在一起说。
AI主播跟真人主播一样,读的都是事先写好的稿子,也就是从文字转换为语音,背后需要的就是语音合成技术(TTS,text to speech),大家平常导航听的志玲姐姐的“准备出发,全程4公里,大约需要15分钟”,就是语音合成技术在我们身边最广泛的应用了。
如果你完全不懂语音合成,要想一个最简单的方案时会是怎样的呢?应该是这样。

比如如下视频就是这么做的。
(去微信公众号观看)
细节说起来,语音合成就是这样的一个流程:
(1) 建立数据集
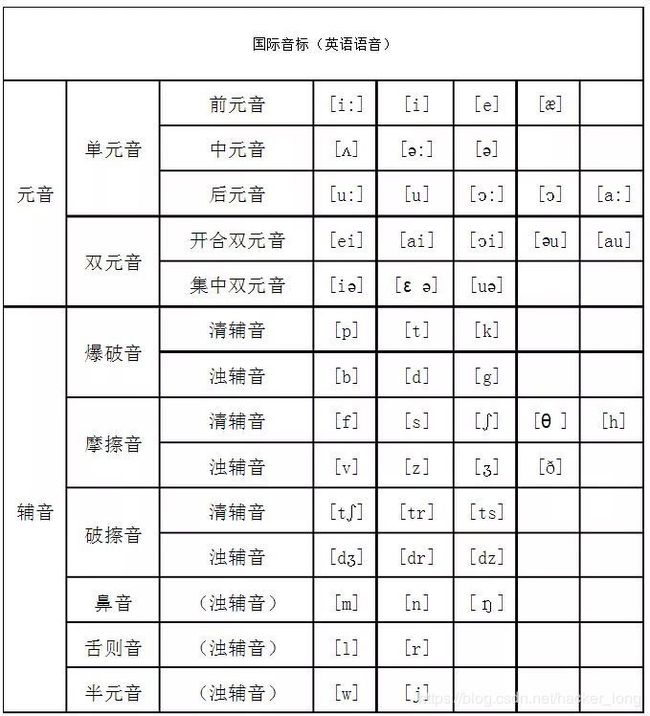
录制一些语音作为语音库,要有成对的词和语音,搜狗的这个AI主播需要录制一个半小时的数据。录制这样的数据,要尽可能的覆盖语言中的元音、辅音、不同的音调,就像图像采数据集的时候要考虑不同的姿态,光照一样。
多提一句因为咱们粉丝多是CV领域的,在图像中的最小单位是像素,在语音中则是音素,音素分为元音和辅音,每一门语言中都需要元音和辅音。
元音是气流通过口腔而不受阻碍发出的音,英语中的a,e,i,o,u是元音字母。辅音也是有声音的,在学习的过程中更难一些,它是由气流在口腔或咽头受到阻碍而发出的,比如f,m等,读书时学习辅音总是有点别扭。
(2) 文本序列转换成音素序列
这一步主要是利用NLP技术对输入文本进行语言学分析,也就是大家熟悉的分词。比如“上海自来水来自海上”,分词之后应该是“上海 自来水 来自 海上”,4个词语。
同时为了让生成的声音更加自然,还要分析文本的节奏、重音,实际情况更加复杂,还有各类数字、缩写、多音字等等,非专业所长就不说了。
(3) 合成声音
声音在时序上表示出来,就是一个波形。
1. 最早期也是最笨的方法,就是从语音库中寻找与第二步得到的音素一致的语音单元,将波形拼接起来变成波形序列。
2. 不过这样的方法对数据集的要求太高了,如果能有一个基本的语音特征库,配上参数权重进行调整,就可以实现更加灵活的合成,这就是第二类方法。将音素实时转换成语音参数,在语音库中进行匹配,再与第一类方法一样拼接生成语音。
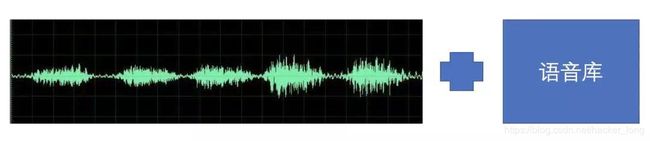
搜狗这个,很大概率用的就是这种方法了。
3. 最后一种方法,就是大家最喜欢的端到端的方法了,最好是直接从输入的文本,输出最后的波形,所有的流程都交给模型。
管它什么任务,深度学习一把出,这就是现在大家的思路了。
有一些比较著名的模型,总结起来如下:
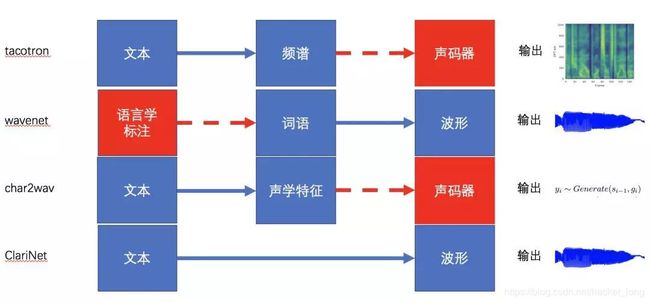
Tacotron从文本出发,输出频谱图,之后再用声码器将语谱图转换成波形。WaveNet则需要语言学特征作为输入,不能直接使用原始文本。Char2Wav直接输入字符进行合成,预测出声学参数,仍然需要声码器vococder。ClariNet则构建了一个从文本到波形、真正的端到端的语音合成模型。另外还有Deep Voice,包含了多个模块,虽然看起来是端到端的模型,不过每个部分分别训练。
语音合成的东西就这么多,另外,在其中还要用到情感迁移技术,实现个性化语音合成。
在这里也多提一句,给新手们扫个盲,就像图像有基本的属性如分辨率,梯度,声音也有三个基本属性。
响度,又称之为声强或音量,直观理解就是声音的大小,用分贝dB衡量。
音高,即声调,用频率来衡量,所谓男高音女高音就是指音高,而不是谁吼出的声音大谁就是高音。
音色,这就是由发声体自身的特质决定了,同样的内容,志玲姐姐说的跟蔡少芬说的肯定感觉不同,同样的音不同的乐器演奏也截然不同,原理上是由谐波频率+高频成分所决定。
3 多模态合成技术
最后一个难点就是如何将声音、唇动、表情在一条时间轴上匹配,保证三者的协调一致、连贯自然。这是一个视频生成的问题,需要用到多模态合成技术。
这是比较新的应用领域了,研究也不少,我们比较熟悉的包括视音频的多模态融合,图片和文本的多模态融合等,比如下图输入无声音的视频和语音进行驱动。
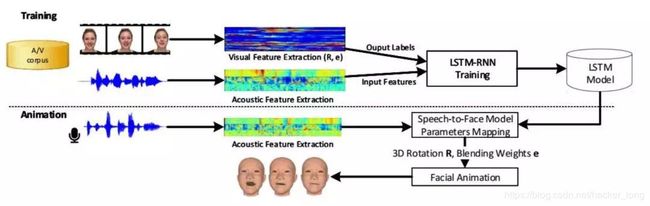
说到多模态合成就得说下多模态融合的分类,根据层级的不同分为对原始数据进行融合、对抽象的特征进行融合和对决策结果进行融合。
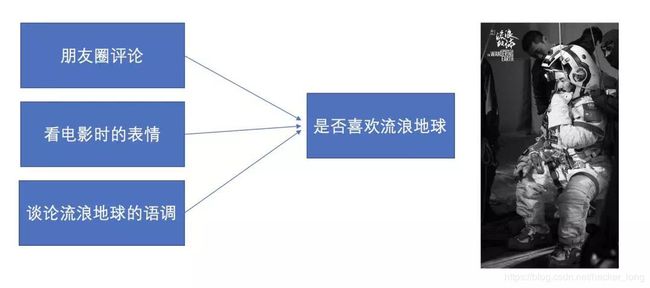
举个例子,如果我们想判断一个人对一部电影的真实情感,可以从它发表的评论,看电影时的表情和谈论该电影时的语调等几个方向一起联合判断,这样会比单独只通过一个维度更加准确。
人工智能如果想走的更远,各个领域技术之间的融合是必须的。这种融合不应该是在各自出高层识别的结果之后,而是应该在原始信号层次就开始融合,目前还是发展早期,懂得不多不瞎说了。
总结
咱公众号准备开通语音方向了,欢迎喜欢分享的朋友前来坐阵,多多益善。
真的很想知道,以后的生活到底会变成什么样子,我们的口号是“三人行必有AI”,预告一下本周日VIP会员见面会活动,限VIP参加或一次付费,不超过8人,我将分享如何学习深度学习等话题,欢迎前来,可加我微信(文章开头有)报名或者点击如下链接报名。


关于什么是VIP会员和季划,请参考。
创业第一天,有三AI扔出了深度学习的150多篇文章和10多个专栏
转载文章请后台联系
侵权必究
感谢各位看官的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注有三公众号 有三AI!
