在树莓派上实现基于VAD的自动语音对话系统
0. 文章目录
- 1. 背景
- 2. 硬件
- 3. 软件
- 3.1 树莓派环境搭建
- 3.2 接口封装
- 3.2.1 语音识别与语音合成
- 3.2.2 文字对话
- 3.3 实时语音活动检测
- 4. 不足
1. 背景
在《基于ESP32的人工智能语音教具》项目中,已经将语音识别、语音合成、文字对话、语音对话及自然语言处理融合到一起,成为一个多功能系统,但在硬件方面采用按钮按下的触发,来进行录制语音并发送,过于机械化。本项目希望采用语音活动检测(Voice Activity Detection,VAD)来进行语音的判断,从而做一个自动语音对话系统。
2. 硬件
在《基于ESP32的人工智能语音教具》项目中采用的是嵌入式系统与云端服务器进行结合,在嵌入式系统上进行的是数据传输的工作,复杂的操作可以在服务器端实现,如搭建自主实现的语音识别功能和实现更智能的对话功能等。
在《在树莓派上实现基于VAD的自动语音对话系统》项目中,由于现有的语音及文字对话系统比较成熟,本项目决定采用现有的API,如灵云的语音识别/语音合成和图灵机器人的文字对话API,重点将在如何实现自动的语音对话系统。这里选用树莓派3B+,具有较强性能,拓展起来方便,且资料丰富。

3. 软件
3.1 树莓派环境搭建
- Raspberry Pi 3B+ 及 配套电源线
- 读卡器 及 Micro SD卡 8G及以上
- 显示屏 及 HDMI线
- USB键盘 及 USB鼠标(无线键鼠也可)
- 安装Win32 DiskImager
- 下载RASPBIAN系统
给树莓派安装RASPBIAN系统,从官网(https://www.raspberrypi.org/downloads/raspbian/)下载,下载ZIP解压成.img文件。

用Win32 DiskImager将.img写入对应Micro SD卡中。
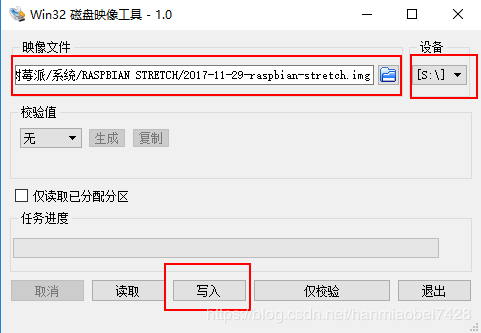
写入成功后,插入HDMI连接显示屏,开机配置WiFi账号密码。在左上角蓝牙标志的边上有网络连接,点击选择无线网络,并输入密码。当出现WIFI标志时,即连接成功,如下图。
![]()
打开terminal软件,在下图所示位置。

使用命令行安装pyaudio库(用于语音处理):
sudo apt-get install portaudio.dev
sudo apt-get install python3-pyaudio
sudo apt-get install pulseaudio
使用webrtcvad库进行语音活动检测,webrtcvad采用的是GMM模型(可参考WebRTC之VAD算法这篇博文):
sudo pip3 install webrtcvad
3.2 接口封装
3.2.1 语音识别与语音合成
选用一个平台的语音识别服务,本项目选用的是灵云(http://www.hcicloud.com/),在开发者平台上注册账号和选择语音识别和语音合成功能。申请成功后,如下图所示。
下面是根据官方开发文档所编写的语音识别类和语音合成类。
语音识别类使用16k.pcm,识别结果为北京科技馆的音频作为测试。
# -*- coding: utf-8 -*-
#ASR
import urllib.parse, urllib.request
import time
import json
import hashlib
class LinyunAsrMode(object):
def __init__(self):
self.appkey = "545d5467"
self.capkey = "asr.cloud.freetalk"
self.audioformat = "pcm16k16bit"
self.developerkey = "4811cb1e437414777250201c0d9b854a"
self.url = "http://api.hcicloud.com:8880/asr/Recognise"
self.nowdate = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
def get_linyun_text(self, voicedata):
#voicedata is binary content,saved in bytes
body = voicedata
x_config = "capkey={0},audioformat={1},identify={2},index={3},addpunc=yes".format(
self.capkey, self.audioformat, self.nowdate, "-1")
x_checksum_content = self.nowdate + self.developerkey
x_checksum = hashlib.md5(x_checksum_content.encode('utf-8')).hexdigest().upper()
x_header = {"x-app-key": self.appkey,
'x-sdk-version': "5.0",
'x-request-date': self.nowdate,
'x-session-key': x_checksum,
"x-task-config": x_config,
"x-udid": "101:1234567890",
"x-result-format": "json",
"content-type": "application/x-www-form-urlencoded"}
req = urllib.request.Request(url = self.url,
data = body,
headers = x_header,
method = 'POST')
result = urllib.request.urlopen(req)
result = result.read().decode('utf-8')
json_data = json.loads(result)
json_ResponseInfo = json_data['ResponseInfo']
json_Result = json_ResponseInfo['Result']
json_Score = json_Result['Score']
if 0 != int(json_Score):
return json_Result['Text']
else:
print(json_ResponseInfo)
return None
# %% main function
if __name__ == '__main__':
f = open("16k.pcm", 'rb')
file_content = f.read()
linyun = LinyunAsrMode()
Asr_result = linyun.get_linyun_text(file_content)
if Asr_result != None:
print(Asr_result)
# -*- coding: utf-8 -*-
#TTS
import time
import hashlib
import urllib.request
import urllib.parse
from pyaudio import PyAudio, paInt16
def writeFile(file, content):
with open(file, 'wb') as f:
f.write(content)
f.close()
class LingyunTtsMode(object):
def __init__(self):
self.developerkey = "4811cb1e437414777250201c0d9b854a"
self.appkey = "545d5467"
self.audioformat = "pcm16k16bit"
self.speed = "5"
self.volume = "10"
self.url ="http://test.api.hcicloud.com:8880/tts/SynthText"
self.nowdate = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
def GetAudioType(self, type):
return{
1:"tts.cloud.xiaokun",
2:"tts.cloud.haobo",
3:"tts.cloud.xixi",
4:"tts.cloud.cartoonjing",
5:"tts.cloud.diaoxiong",
6:"tts.cloud.jiangman",
7:"tts.cloud.liangjiahe",
8:"tts.cloud.shenxu",
9:"tts.cloud.wangjing.v9",
10:"tts.cloud.xiaokun.v9",
11:"tts.cloud.xumengjuan",
12:"tts.cloud.zhaqian",
13:"tts.cloud.zhangnan",
}.get(type, "tts.cloud.wangjing")
'''
# * 为语音合成http通讯方法
# * byteResult这个返回的就是 16K16Bit PCM数据
# * type : 需要合成的文本 整形
# * 第二个参数需要填 合成的声音类型 如女生 男生等
# * 中文女声 ---0
# * 中文女声 ---1
# * 中文男声 ---2
# * 女童声 ---3
# * 卡通女声 ---4
# * 幽默男声 ---5
# * 利落女声 ---6
# * 呆萌女童声 ---7
# * 利落男声 ---8
# * 知性女声 ---9
# * 舒缓女声 ---10
# * 嗲柔女声 ---11
# * 成熟女声 ---12
# * 嘹亮女声 ---13
# * 其他就是默认是 0
# *
# * return : 返回的就是 16K16Bit PCM数据
'''
def lingyun_tts(self, content, type):
body = content.encode('utf8')
capkey = self.GetAudioType(type)
x_config = "capkey={0},audioformat={1},speed={2},volume={3}".format(
capkey, self.audioformat, self.speed, self.volume)
x_checksum_content = self.nowdate + self.developerkey
x_checksum = hashlib.md5(x_checksum_content.encode('utf-8')).hexdigest().upper()
x_header = {"x-app-key": self.appkey,
'x-sdk-version': "5.0",
'x-request-date': self.nowdate,
'x-session-key': x_checksum,
"x-task-config": x_config,
"x-udid": "101:1234567890",
"content-type": "application/x-www-form-urlencoded"}
req = urllib.request.Request(url = self.url,
data = body,
headers = x_header,
method = 'POST')
req = urllib.request.Request(self.url, data = body, headers = x_header)
response = urllib.request.urlopen(req)
body = response.read()
body_s = str(body)
start = body_s.index('') + len('')
body_l = list(body)
sound = bytes(body_l[start:])
return sound
if __name__ == '__main__':
Text = "你叫什么名字呀"
lingyun = LingyunTtsMode()
body = lingyun.lingyun_tts(Text, 11)
p = PyAudio()
stream = p.open(
format = paInt16,
channels = 1,
rate = 16000,
output = True)
stream.write(body)
stream.stop_stream()
stream.close
p.terminate()
3.2.2 文字对话
文字识别使用图灵机器人的API。
# -*- coding: utf-8 -*-
# DLG
import json
from urllib.request import urlopen,Request
from urllib.error import URLError
from urllib.parse import urlencode
class TuringChatMode(object):
"""this mode base on turing robot"""
def __init__(self):
self.turing_url = 'http://openapi.tuling123.com/openapi/api?'
def get_turing_text(self,text):
turing_url_data = dict(
key = '25e9346d64e646c59530f889abb2907d',
info = text,
userid = '28d2444e030a',
)
self.request = Request(self.turing_url + urlencode(turing_url_data))
try:
w_data = urlopen(self.request)
except URLError:
raise IndexError("No internet connection available to transfer txt data")
except:
raise KeyError("Server wouldn't respond (invalid key or quota has been maxed out)")
response_text = w_data.read().decode('utf-8')
json_result = json.loads(response_text)
return json_result['text']
if __name__ == '__main__':
print("Now u can type in something & input q to quit")
turing = TuringChatMode()
while True:
msg = input("\nMaster:")
if msg == 'q':
exit("u r quit the chat !") # 设定输入q,退出聊天。
else:
turing_data = turing.get_turing_text(msg)
print("Robot:",turing_data)
3.3 实时语音活动检测
自动语音对话系统,需要知道什么时候人开始说话,什么时候人结束说话,并将人说话这段语音进行语音识别,再进行文字对话和语音合成,这就需要实时对语音实时进行VAD检测。
这里使用生产者消费者模型, 生产者消费者模型当中有两大类重要的角色,一个是生产者,负责造数据的任务,本项目是录制声音;另一个是消费者,接收造出来的数据进行进一步的操作,本项目中是对录制的声音进行实时VAD检测及后续操作。
为什么要使用生产者消费者模型?
这里引用(python)生产者消费者模型这篇博文的表述:
在并发编程中,如果生产者处理速度很快,而消费者处理速度比较慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个等待的问题,就引入了生产者与消费者模型。让它们之间可以不停的生产和消费。
实时VAD检测及后续操作
在webrtcvad中是对20ms的数据进行vad检测,若检测到语音活动则返回1,否则返回0。但对于vad检测返回的信号,不能简单拿来作为语音段,需要经过一定处理,包括去除抖动和松开/按下判断等。在防抖判断时,若判断此段语音为抖动,则清除这段语音有效标志;在松开/按下判断时,若语音有效标志为1,则储存语音,若语音标志位从1到0变化且0持续不到一定时间(如0.5秒)则继续储存语音,若语音标志位从1到0变化且0持续超过一定时间(如0.5秒)则将之前储存的语音片段进入语音识别过程。
此时暂停和清零生产者的生产,即停止和清零录音,直至语音合成结束后恢复。
4. 不足
1)使用的是python而不是c语言,程序效率可以提高。
2)基于VAD的自动语音对话系统存在着不足,若在嘈杂环境中(信噪比低)会出现误触发的情况,且在与其他人交流的时候,该系统会自动识别为与其对话。这里可以采用基于唤醒词的自动语音对话系统。