微服务架构漫谈
1. 概述
微服务:
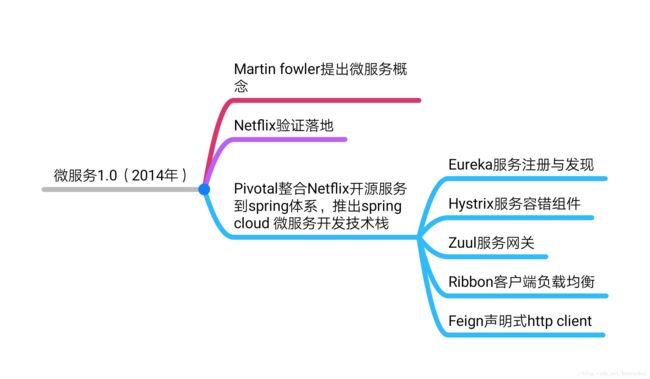
2014 年可以认为是微服务 1.0 的元年,当年有几个标志性事件,一是 Martin Fowler 在其博客上发表了”Microservices”一文,正式提出微服务架构风格;二是 Netflix 微服务架构经过多年大规模生产验证,最终抽象落地形成一整套开源的微服务基础组件,统称 NetflixOSS,Netflix 的成功经验开始被业界认可并推崇;三是 Pivotal 将 NetflixOSS 开源微服务组件集成到其 Spring 体系,推出 Spring Cloud 微服务开发技术栈。
一晃三年过去,微服务技术生态又发生了巨大变化,容器,PaaS,Cloud Native,gRPC,ServiceMesh,Serverless 等新技术新理念你方唱罢我登场,不知不觉我们又来到了微服务 2.0 时代。

2. 架构及技术栈
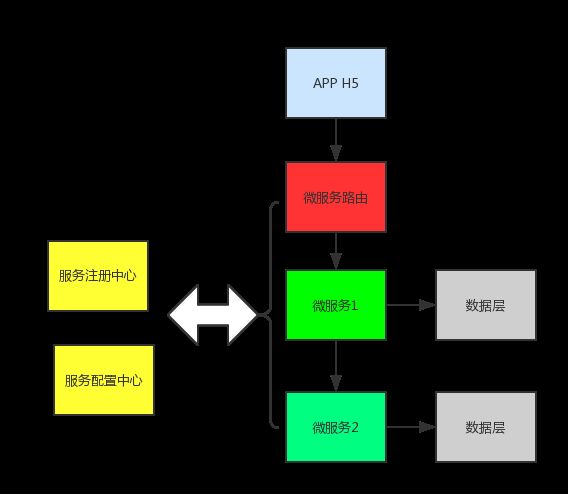
微服务的三种架构模式:
2.1 链式模式
业务需要微服务之间是同步调用关系,服务1调用服务2,在服务2完成后,返回结果给服务1,然后返回gateway,返回请求方。
在实际业务场景中,涉及到交易和订单的业务场景都会用到这种模式。
2.2 聚合模式
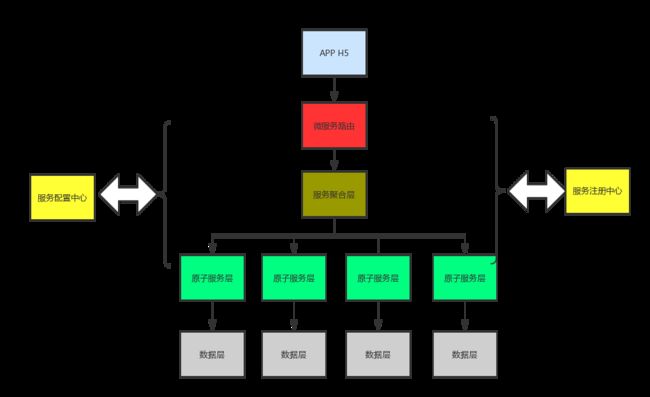
服务之前没有依赖关系,不需要同步调用,各个微服务执行完成后,聚合层进行某些过滤或者合并计算,然后返回gateway,最终返回调用方。
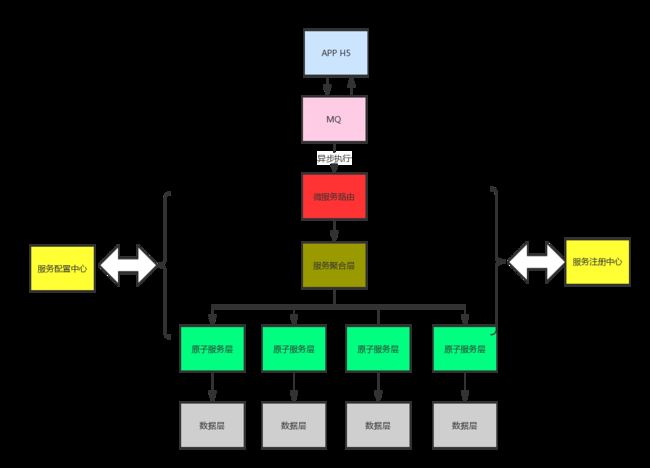
2.3 异步消息模式
无论是链式模式,还是聚合模式,一个请求都需要处理完成后才能返回,如果一个请求不关心返回结果,为了提高系统吞吐量,可以采用异步消息模式,流程图如下:
3.分布式事务
微服务模块比较分散、数据也比较分散,整个系统复杂性非常高,如何进行数据一致性实践?在一个单体模块里面可以做Local Transaction,但是在微服务体系里面就不奏效。虽然难解决,但是不能不解决,不解决的话微服务架构就很难实施。我们知道微服务中做强一致性是非常难的,今天分享的更多的是解决最终一致性。因为在微服务下基于不同的数据库,Local Transaction是不可用的。大家在在分布式事务里面一定听说过两阶段提交和三阶段提交,这种场景其实在微服务架构里面也行不通,原因是因为它本质上是同步的模式,同步的模式之下做数据一致性吞吐量降低的非常多。
我们的业务场景无非是两种:第一种是异步调用,就是一个请求过来就写到消息队列里面就行,这种模式相对简单。今天主要讲下同步调用的场景之下怎么打造数据的最终一致性。既然是同步调用场景,并且不能降低业务系统的吞吐量,那么应该怎么做呢?建立一个异步的分布式事务,业务调用失败后,通过异步方式来补偿业务。我们的想法是能不能在整个业务逻辑层实现分布式事务语义策略?如何实现,无非有两种,第一是在调正常请求的时候要记录业务调用链(调用正常接口的完整参数),第二是异常时沿调用链反向补偿。
异步调用,存入MQ,然后
基于这个思路,我们架构设计上的关键点有三,第一是基于补偿机制,第二是记录调用链,第三是提供幂等补偿接口。架构层面,看下图,右边是聚合器架构设计模式,左边是异步补偿服务。
思路一:
分布式事务是多次提交,比如下订单,需要扣减库存,优惠券扣减等操作,如果下单失败,需要回滚,补充库存以及优惠券。
库存和优惠券,订单服务都是独立的service。
我的设计思路是,多次提交利用缓存保存的flag判断本次事务处理是否完成,比如提交订单,先扣减库存,库存扣减完成后,设置flag为1,然后进行优惠券扣减,同理,成功则设置flag为2,继续提交订单流程。整个流程结束。
如果某个service处理失败,比如库存扣减完成后,设置flag为true,但是优惠券扣减失败,则flag仍未1.
这种思路,每个servie执行逻辑前需要check flag是否是当前servie的step,如果是,说明前面的service执行都成功了,如果不是则,有失败的service。如何回滚呢?我的思路欠缺的时候回滚方式。需要保存成功的service的执行参数,以便于回滚。
思路二:
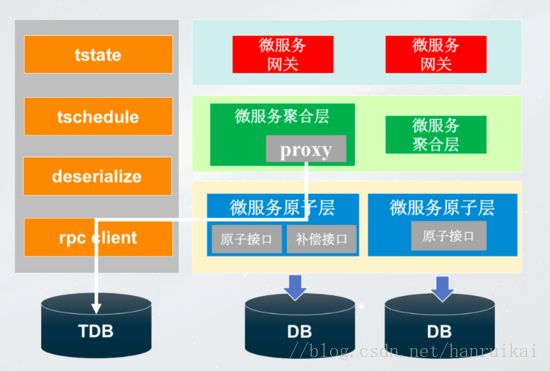
首先需要在聚合层引入一个Proxy。首先基于方法,在方法名加注解标注补偿方法名,比如:- @Compensable(cancelMethod=“cancelRecord”)
另外,聚合层在调用原子层之前,通过代理记录当前调用请求参数。如果业务正常,调用结束后,当前方法的调用记录存档或删除,如果业务异常,查询调用链回滚。
原子层我们做了哪些事情呢?主要是两方面,第一是提供正常的原子接口,其次是提供补偿幂等接口。
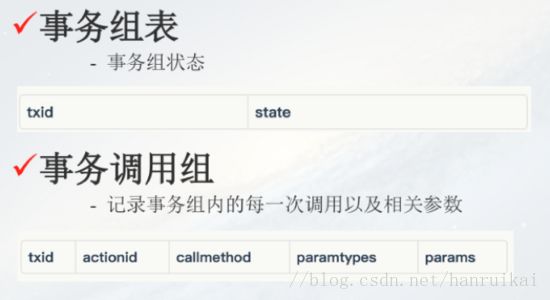
分布式事务关键是两个表(如上图),第一是事务组表,假设A->B->C三个请求是一个事务,首先针对ABC生成一个事务的ID,写在这个表里面,并且会记录这个事务的状态,默认的情况下正常的,执行失败以后我们再把状态由1(正常)变成2(异常);第二个表是事务调用组表,主要记录事务组内的每一次调用以及相关参数,所以调用原子层之前需要记录一下请求参数。如果失败的话我们需要把这个事务的状态由1变成2;第三,一旦状态从1变成2就执行补偿服务。这是我们的补偿逻辑,就是不断地扫描这个事务所处的表,比如一秒钟扫一次事务组表,看一看这个表里面有没有状态为2的,需要执行补偿的服务。这个思路对业务的侵入比较小。
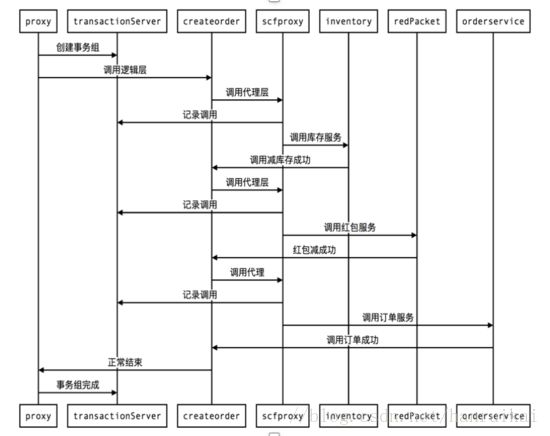
具体看下我们实际的例子,比如二手交易平台里面创建订单事务组的正常流程,从锁库存到减红包再到创建订单,创建事务组完毕之后开始调用业务,首先Proxy记录锁库存调用的参数,之后开始锁库存服务调用,成功后之后又开始减红包和创建订单过程,如果都成功了直接返回。
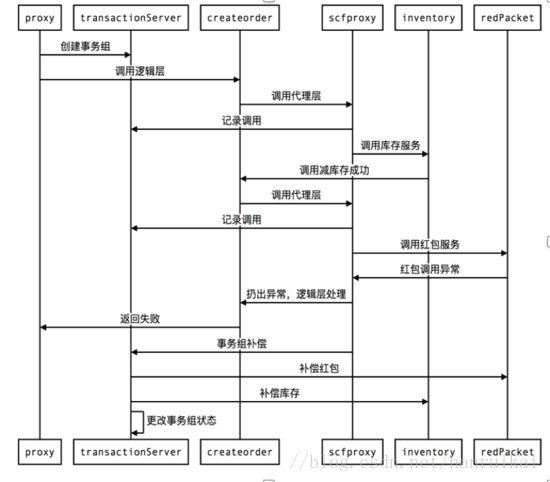
再看一下异常的流程,前面几步都是一样的,只是在调红包服务、Proxy创建红包的时候如果失败了就会抛出异常,业务正常返回,聚合层Proxy需要把事务组的状态由1改成2,这个时候由左边的补偿服务异步地补偿调用
分布式事务引自:
http://www.techweb.com.cn/network/system/2017-07-12/2555992.shtml