TPC-DS测试hadoop 安装步骤
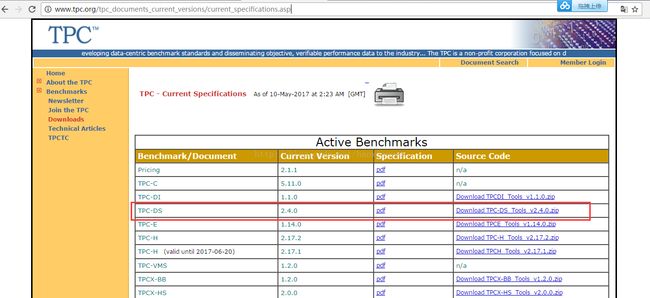
1.TPC-DS下载地址如下
http://www.tpc.org/tpc_documents_current_versions/current_specifications.asp
1. 安装依赖
yum -y install gcc gcc-c++ libstdc++-devel bison byacc flex
2. 安装
unzip a3083c5a-55ae-49bc-8d6f-cc2ab508f898-tpc-ds-tool.zip
cd v2.3.0/tools
make
3. 生成数据
生成10T数据
./dsdgen -scale 10000 -dir /dfs/data
后台生成数据
100G数据生成(可以不同机器同时生产秩序改并行度和child后面的数字,注意并行度你自己调整,例如我这里是10,那么就要保证有10个child才能保证数据后续是完整的。)
nohup ./dsdgen -scale 100 -dir/dfs/data/ -parallel 10 -child 1 >nohup.log 2>&1 &
nohup ./dsdgen -scale 100 -dir/dfs/data/ -parallel 10 -child 2 >nohup.log 2>&1 &
nohup ./dsdgen -scale 100 -dir/dfs/data/ -parallel 10 -child 3 >nohup.log 2>&1 &
nohup ./dsdgen -scale 10000 -dir/dfs/data/ -parallel 20 -child 4 >nohup.log 2>&1 &
nohup ./dsdgen -scale 100 -dir/dfs/data/ -parallel 10 -child 5 >nohup.log 2>&1 &
nohup ./dsdgen -scale 100 -dir/dfs/data/ -parallel 10 -child 6 >nohup.log 2>&1 &
nohup ./dsdgen -scale 100 -dir/dfs/data/ -parallel 10 -child 7 >nohup.log 2>&1 &
nohup ./dsdgen -scale 100 -dir/dfs/data/ -parallel 10 -child 8 >nohup.log 2>&1 &
nohup ./dsdgen -scale 100 -dir/dfs/data/ -parallel 10 -child 9 >nohup.log 2>&1 &
nohup ./dsdgen -scale 100 -dir/dfs/data/ -parallel 10 -child 10 >nohup.log 2>&1 &
1) 将本地数据上传到HDFS
2) 用hadoop-shell命令开始上传数据:
3) nohup hadoop fs -put /dfs/data/* /tpc_ds > nohup.log 2>&1 &
创建hive中的表
git clone https:
//github
.com
/hortonworks/hive-testbench
.git
[root@namenode01 text]# pwd
/root/hive-testbench/ddl-tpcds/text 有创建表语句,自己安装自己更改下
alltables.sql analyze_everything.sql
create database tpc_ds;
create database tpc_ds2;
use tpc_ds;
drop table if exists call_center;
create external table call_center(
cc_call_center_sk bigint
, cc_call_center_id string
, cc_rec_start_date string
, cc_rec_end_date string
, cc_closed_date_sk bigint
, cc_open_date_sk bigint
, cc_name string
, cc_class string
, cc_employees int
, cc_sq_ft int
, cc_hours string
, cc_manager string
, cc_mkt_id int
, cc_mkt_class string
, cc_mkt_desc string
, cc_market_manager string
, cc_division int
, cc_division_name string
, cc_company int
, cc_company_name string
, cc_street_number string
, cc_street_name string
, cc_street_type string
, cc_suite_number string
, cc_city string
, cc_county string
, cc_state string
, cc_zip string
, cc_country string
, cc_gmt_offset double
, cc_tax_percentage double
)
row format delimited fields terminatedby '|'
STORED AS textfile;
还有很多,不一一展现了。加载数据:
LOAD DATA inpath '/tpc_ds/call_center*.dat' INTO TABLEcall_center;
创建Partquet列式数据存储
use tpc_ds2;
create external table call_center(
cc_call_center_sk bigint
, cc_call_center_id string
, cc_rec_start_date string
, cc_rec_end_date string
, cc_closed_date_sk bigint
, cc_open_date_sk bigint
, cc_name string
, cc_class string
, cc_employees int
, cc_sq_ft int
, cc_hours string
, cc_manager string
, cc_mkt_id int
, cc_mkt_class string
, cc_mkt_desc string
, cc_market_manager string
, cc_division int
, cc_division_name string
, cc_company int
, cc_company_name string
, cc_street_number string
, cc_street_name string
, cc_street_type string
, cc_suite_number string
, cc_city string
, cc_county string
, cc_state string
, cc_zip string
, cc_country string
, cc_gmt_offset double
, cc_tax_percentage double
)
row format delimited fields terminatedby '|'
STORED AS PARQUET;加载数据到partquet数据到表里:
INSERT OVERWRITE TABLE call_center SELECT * FROM tpc_ds.call_center;
其他表也类似加载,之后就可以进行性能测试。SQL语句:
select * from
(selecti_manufact_id,sum(ss_sales_price) sum_sales,avg(sum(ss_sales_price)) over(partition by i_manufact_id) avg_quarterly_sales from item,
store_sales, date_dim, store
where ss_item_sk = i_item_sk and
ss_sold_date_sk = d_date_sk and
ss_store_sk = s_store_sk and
d_month_seq in(1212,1212+1,1212+2,1212+3,1212+4,1212+5,1212+6,1212+7,1212+8,1212+9,1212+10,1212+11)and
((i_category in('Books','Children','Electronics') and
i_class in('personal','portable','reference','self-help') and
i_brand in ('scholaramalgamalg#14','scholaramalgamalg #7','exportiunivamalg #9','scholaramalgamalg #9')) or
(i_category in ('Women','Music','Men')and i_class in ('accessories','classical','fragrances','pants') and
i_brand in ('amalgimporto #1','edupackscholar #1','exportiimporto #1','importoamalg #1')))
group by i_manufact_id, d_qoy ) tmp1where case when avg_quarterly_sales > 0 then abs (sum_sales -avg_quarterly_sales)/ avg_quarterly_sales
else null end > 0.1
order by avg_quarterly_sales,sum_sales,
i_manufact_id
limit 100;
2. Linux 缓冲
echo 3 >/proc/sys/vm/drop_caches
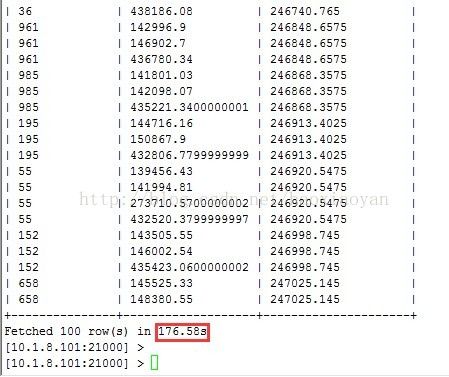
3. 执行时间