TensorFlow 学习笔记
TensorFlow是一个Google开源的深度学习框架。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。以下内容是基于Udacity深度学习课程的学习笔记。
安装TensorFlow
利用Conda来安装TensorFlow,需要安装一个TensorFlow环境和所需要的包。
OSX或Linux
conda create -n tensorflow python=3.5
source activate tensorflow
conda install pandas matplotlib jupyter notebook scipy scikit-learn
conda install -c conda-forge tensorflowWindows
conda create -n tensorflow python=3.5
activate tensorflow
conda install pandas matplotlib jupyter notebook scipy scikit-learn
conda install -c conda-forge tensorflowTensorFlow中的数据
TensorFlow中,数据被封装在一个叫tensor的对象中,tf.constant()用来表示常量;tf.placeholder()用来向TensorFlow传递数据,例如神经网络中的features和labels,可以理解为一个可以用来操作却不能改变其值的变量;tf.Variable()用来表示可以用来改变其中存储数据值的变量,例如神经网络中的权重和偏置,可以使用tf.Variable()进行更新。举几个例子如下:
# A is a 0-dimensional int32 tensor
A = tf.constant(1234)
# B is a 1-dimensional int32 tensor
B = tf.constant([123,456,789])
# C is a 2-dimensional int32 tensor
C = tf.constant([ [123,456,789], [222,333,444] ])
# hello_constant is a 0-dimensional string tensor
hello_constant=tf.constant('Hello World')tf.constant()返回的tensor是一个常量tensor,这个tensor的值不会改变。而如果想使用非常量,就需要tf.placeholder()和feed_dict配合使用。
x = tf.placeholder(tf.string) #括号中的参数为数据的类型
y = tf.placeholder(tf.int32)
z = tf.placeholder(tf.float32)
with tf.Session() as sess:
output = sess.run(x, feed_dict={x: 'Test String', y: 123, z: 45.67})
#feed_dict是一个字典,用于向Session()传递参数值tf.Variable 类创建一个 tensor,其初始值可以被改变,就像普通的 Python 变量一样。该 tensor 把它的状态存在 session 里,所以你必须手动初始化它的状态。你将使用 tf.global_variables_initializer() 函数来初始化所有可变 tensor。
x = tf.Variable(5) #括号中的参数为给定的初值
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)tf.global_variables_initializer() 会返回一个操作,它会从 graph 中初始化所有的 TensorFlow 变量。你可以通过 session 来调用这个操作来初始化所有上面的变量。用 tf.Variable 类可以让我们改变权重和偏差,但还是要选择一个初始值。
TensorFlow中的Session
TensorFlow 的 api 构建在 computational graph 的概念上,它是一种对数学运算过程进行可视化的方法。一个 “TensorFlow Session” 是用来运行图的环境。这个 session 负责分配 GPU(s) 和/或 CPU(s),包括远程计算机的运算
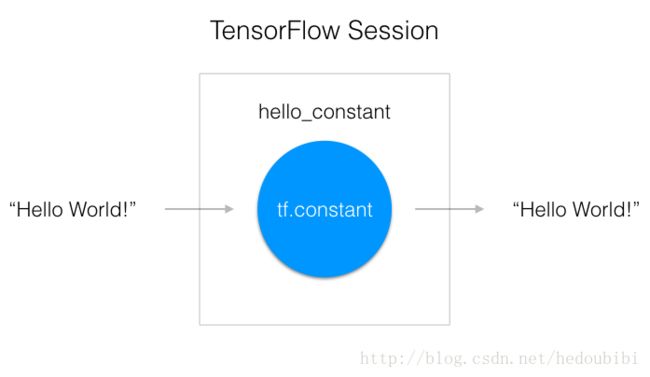
hello_constant=tf.constant('Hello World')
with tf.Session() as sess:
output = sess.run(hello_constant)这段代码用 tf.Session 创建了一个 sess 的 session 实例。然后 sess.run() 函数对 tensor 求值,并返回结果。
TensorFlow中的数学
x = tf.add(5, 2) # 加法
x = tf.subtract(10, 4) # 减法
y = tf.multiply(2, 5) # 乘法
z = tf.divide(4, 2) #除法
Linear = tf.matmul(features, hidden_weights) #矩阵乘法 加减乘除的用法非常简单,注意区分矩阵乘法和普通乘法的区别。除此之外,有些细节需要注意,那就是运算的对象需要满足类型匹配,即参与运算的对象需要有相同的数据类型,像下面例子中的代码就会出错:
tf.subtract(tf.constant(2.0),tf.constant(1)) # Fails with ValueError: Tensor conversion requested dtype float32 for Tensor with dtype int32:有时候为了能够实现类型匹配,需要使用tf。cast()命令来进行数据类型转换:
tf.subtract(tf.cast(tf.constant(2.0), tf.int32), tf.constant(1)) # 这样的话就会输出正确的结果,系统就不会报错但是在使用tf.divide()函数时,遇到一个问题,如下:
import tensorflow as tf
x = tf.constant(10)
y = tf.constant(2)
z = tf.subtract(tf.divide(x,y),tf.cast(tf.constant(1),tf.float64))
with tf.Session() as sess:
output=sess.run(z)
print (output)
print (type(z)) #tf.divide()函数的两个参数下x和y都是tf.int32,但是tf.divide(x,y)的类型却是tf.float64类型。
import tensorflow as tf
x=10
y=2
z = tf.subtract(tf.divide(x,y),tf.cast(tf.constant(1),tf.float32))
with tf.Session() as sess:
output=sess.run(z)
print (output)
print (type(x)) #如果tf.divide()函数的参数变为两个int类型的数据,tf.divide(x,y)的类型却会变成tf.float32类型。
TensorFlow中的线性函数
线性函数应用于深度神经网络中的线性叠加节点。在TensorFlow中已经学过了利用tf.Variable()来创建变量以及如何进行初始化,现在我们将针对具体在深度神经网络中的应用来对权重和偏置进行初始化。
TensorFlow对于深度神经网络中权重的初始化处理
n_features = 120
n_labels = 5
weights = tf.Variable(tf.truncated_normal((n_features, n_labels))) #括号中的内容代表数据的规模tf.truncated_normal() 返回一个 tensor,它的随机值取自一个正态分布,并且它们的取值会在这个正态分布平均值的两个标准差之内。
从正态分布中取随机数来初始化权重是个好习惯。
(1)随机化权重可以避免模型每次训练时候卡在同一个地方;
(2)而且从正态分布中选择权重可以避免任意一个权重与其他权重相比有压倒性的特性,因为正态分布的数据在极大的概率范围内取值是少于两个标准差的。
TensorFlow对于深度神经网络中偏置的初始化处理
n_labels = 5
bias = tf.Variable(tf.zeros(n_labels))因为权重已经被随机化来帮助模型不被卡住,你不需要再把偏差随机化了。让我们简单地把偏差设为 0。
TensorFlow中的激活函数
S型函数
深度神经网络中的非线性函数是我们提高网络层数的重要部分,其目的是将线性空间中的向量映射到非线性空间中以提高深度神经网络的复杂度。
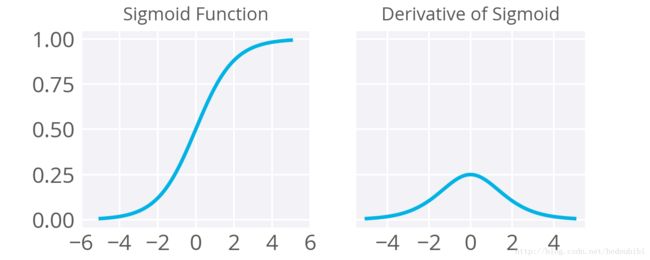
我们通常使用S型函数来作为激活函数,但是S型函数有一个比较明显的缺点是其梯度值的最大值为0.25,且在取值接近-1和1时会变得特别小,因此在进行梯度下降反向传播时会让梯度变的特别小,因此权重更新会变的很小,因此权重需要很长的时间进行训练。所以,S型函数不适合作为隐藏单元上的激活函数。
ReLU函数
近期的大多数深度学习网络都对隐藏层使用修正线性单元 (ReLU),而不是 S 型函数。如果输入小于 0,修正线性单元的输出是 0,原始输出则相反。即如果输入大于 0,则输出等于输入。ReLU函数的数学表达式如下:
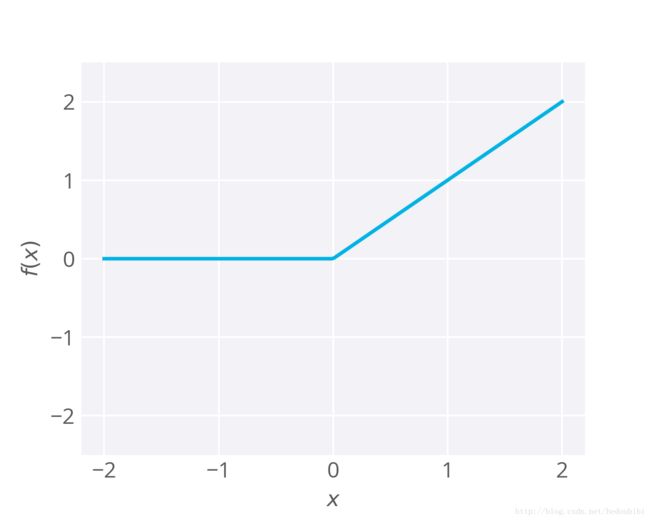
ReLU 激活函数是你可以使用的最简单非线性激活函数。当输入是正数时,导数是 1,所以没有 S 型函数的反向传播中梯度太小导致的梯度消失效果。研究表明,对于大型神经网络来说,ReLU 的训练速度要快很多。TensorFlow 和 TFLearn 等大部分框架使你能够轻松地在隐藏层使用 ReLU,你不需要自己去实现这些 ReLU。
ReLU也存在问题,如有时候一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,会使ReLU神经元始终为 0,即当激活函数值为0时,其梯度值也为0(这个神经元再也不会对任何数据有激活现象了)。这些“无效”的神经元将始终为 0,很多计算在训练中被浪费了。
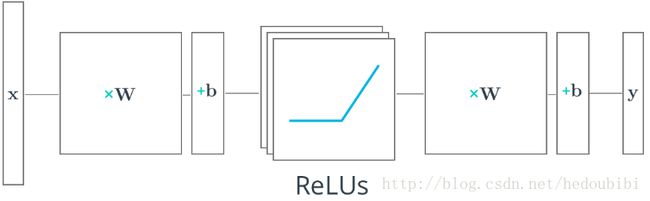
TensorFlow中的Relu函数
TensorFlow 提供了 ReLU 函数 tf.nn.relu(),一般用在隐藏层中,使用方法如下:
# Hidden Layer with ReLU activation function
hidden_layer = tf.add(tf.matmul(features, hidden_weights), hidden_biases)
hidden_layer = tf.nn.relu(hidden_layer)
output = tf.add(tf.matmul(hidden_layer, output_weights), output_biases)利用Relu函数实现一个简单的两层神经网络:
import tensorflow as tf
hidden_layer_weights = [
[0.1, 0.2, 0.4],
[0.4, 0.6, 0.6],
[0.5, 0.9, 0.1],
[0.8, 0.2, 0.8]]
out_weights = [
[0.1, 0.6],
[0.2, 0.1],
[0.7, 0.9]]
weights = [tf.Variable(hidden_layer_weights),tf.Variable(out_weights)]
biases = [tf.Variable(tf.zeros(3)),tf.Variable(tf.zeros(2))]
features = tf.Variable([[1.0, 2.0, 3.0, 4.0], [-1.0, -2.0, -3.0, -4.0], [11.0, 12.0, 13.0, 14.0]])
hidden_layer = tf.nn.relu(tf.add(tf.matmul(features,weights[0]),biases[0]))
output = tf.add(tf.matmul(hidden_layer,weights[1]),biases[1])
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print (sess.run(output))
TensorFlow中的Softmax
Softmax用于处理多元分类状况,具体的理论知识可以参考Ng Andrew的CS229的课件。softmax 函数的输出等于分类概率分布,显示了在某种特征和权重下任何类别为真的概率(后验概率)。通过对所有分类的后验概率求和后取log后求最大值可以用来训练分类模型(最大似然概率)。
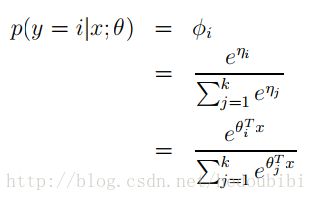

TensorFlow Softmax
当我们用 TensorFlow 来构建一个神经网络时,相应地,它有一个计算 softmax 的函数。
x = tf.nn.softmax([2.0, 1.0, 0.2]) #output = [ 0.65900117 0.24243298 0.09856589]通过判断每个分类对应的概率大小,我们可以判断我们的分类系统会将其归为哪一类。
One-Hot Encoding
One-Hot Encoding的目的是将分类数据的label转换成独热编码向量,以便于数据处理。scikit-learn 的 LabelBinarizer 函数可以很方便地把你的目标(labels)转化成独热编码向量。请看:
import numpy as np
from sklearn import preprocessing
# Example labels 示例 labels
labels = np.array([1,5,3,2,1,4,2,1,3])
# Create the encoder 创建编码器
lb = preprocessing.LabelBinarizer()
# Here the encoder finds the classes and assigns one-hot vectors
# 编码器找到类别并分配 one-hot 向量
lb.fit(labels)
# And finally, transform the labels into one-hot encoded vectors
lb.transform(labels)
>>> array([[1, 0, 0, 0, 0],
[0, 0, 0, 0, 1],
[0, 0, 1, 0, 0],
[0, 1, 0, 0, 0],
[1, 0, 0, 0, 0],
[0, 0, 0, 1, 0],
[0, 1, 0, 0, 0],
[1, 0, 0, 0, 0],
[0, 0, 1, 0, 0]])TensorFlow 中的交叉熵(Cross Entropy)
交叉熵用来判断分类器结果与label的相近程度,通过最小化交叉熵损失函数可以用于训练分类器。
通过Ng Andrew在CS229课程的课件中我们可以知道这个所谓的交叉熵损失函数就是最似然概率函数,具体如下:
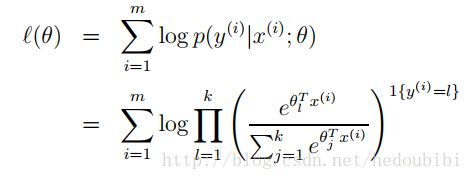
实现交叉熵损失函数需要用到的两个函数如下:
x = tf.reduce_sum([1, 2, 3, 4, 5]) # 15 列表求和下面是已知softmax_data和one_hot_label来求交叉熵的代码:
x = tf.log(100) # 4.60517 求自然对数import tensorflow as tf
softmax_data = [0.7, 0.2, 0.1]
one_hot_data = [1.0, 0.0, 0.0]
softmax = tf.placeholder(tf.float32)
one_hot = tf.placeholder(tf.float32)
# TODO: Print cross entropy from session
entropy=-tf.reduce_sum(tf.multiply(one_hot,tf.log(softmax)))
with tf.Session() as sess:
print (sess.run(entropy, feed_dict={softmax: softmax_data, one_hot: one_hot_data}))
TensorFlow中的Mini-batching
Mini-batching 是一个一次训练数据集的一小部分,而不是整个训练集的技术,用于为随机梯度下降提供随机的小的训练集。Mini-batching 从运算角度来说是低效的,因为你不能在所有样本中计算 loss。但是这点小代价也比根本不能运行模型要划算。方法是在每一次迭代训练之前,对数据进行随机混洗,然后创建 mini-batches,对每一个 mini-batch,用梯度下降训练网络权重。因为这些 batches 是随机的,你其实是在对每个 mini-batch 做梯度下降。
要使用 mini-batching,你首先要把你的数据集分成 batch。不幸的是,有时候不可能把数据完全分割成相同数量的 batch。例如有 1000 个数据点,你想每个 batch 有 128 个数据。但是 1000 无法被 128 整除。你得到的结果是其中 7 个 batch 有 128 个数据点,一个 batch 有 104 个数据点。(7*128 + 1*104 = 1000)。
batch 里面的数据点数量会不同的情况下,你需要利用 TensorFlow 的 tf.placeholder() 函数来接收这些不同的 batch,如下:
features = tf.placeholder(tf.float32, [None, n_input])
labels = tf.placeholder(tf.float32, [None, n_classes])None 维度在这里是一个 batch size 的占位符。在运行时,TensorFlow 会接收任何大于 0 的 batch size。这个设置可以让你把 features 和 labels 给到模型。无论 batch 中包含 128,还是 104 个数据点。
实现batches函数
helper.py
def batches(batch_sizes,features,labels):
assert len(features)==len(labels) #len()返回列表中元素的个数,这里的列表元素为一组feature和一组label
output_batches=[]
sample_size=len(features)
for start_i in range(0,sample_size,batch_size):
# 在[0,sample_size)中以batch_size为步长列举元素
end_i=start_i+batch_size
batch=[features[start_i:end_i],labels[start_i:end_i]]
#列表的切片访问的第二个索引可以超出列表的长度,例如最后一组batch的end_i是超出features的索引的,但仍然是允许的。同时切片访问也是不包含上限的。
output_batches.append(batch)
return ouput_batches迭代(Epochs)
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import numpy as np
from helper import batches # helper function 是自己定义的函数
def print_epoch_stats(epoch_i, sess, last_features, last_labels):
"""
Print cost and validation accuracy of an epoch
"""
current_cost = sess.run(
cost,
feed_dict={features: last_features, labels: last_labels})
valid_accuracy = sess.run(
accuracy,
feed_dict={features: valid_features, labels: valid_labels})
print('Epoch: {:<4} - Cost: {:<8.3} Valid Accuracy: {:<5.3}'.format(
epoch_i,
current_cost,
valid_accuracy))
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
# Import MNIST data
mnist = input_data.read_data_sets('/datasets/ud730/mnist', one_hot=True)
# The features are already scaled and the data is shuffled
train_features = mnist.train.images
valid_features = mnist.validation.images
test_features = mnist.test.images
train_labels = mnist.train.labels.astype(np.float32)
valid_labels = mnist.validation.labels.astype(np.float32)
test_labels = mnist.test.labels.astype(np.float32)
# Features and Labels
features = tf.placeholder(tf.float32, [None, n_input])
labels = tf.placeholder(tf.float32, [None, n_classes])
# Weights & bias
weights = tf.Variable(tf.random_normal([n_input, n_classes]))
bias = tf.Variable(tf.random_normal([n_classes]))
# Logits = xW + b
logits = tf.add(tf.matmul(features, weights), bias)
# Define loss and optimizer
learning_rate = tf.placeholder(tf.float32)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(cost)
# Calculate accuracy
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init = tf.global_variables_initializer()
batch_size = 128
epochs = 10
learn_rate = 0.001
train_batches = batches(batch_size, train_features, train_labels)
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch_i in range(epochs):
# Loop over all batches
for batch_features, batch_labels in train_batches:
train_feed_dict = {
features: batch_features,
labels: batch_labels,
learning_rate: learn_rate}
sess.run(optimizer, feed_dict=train_feed_dict)
# Print cost and validation accuracy of an epoch
print_epoch_stats(epoch_i, sess, batch_features, batch_labels)
# Calculate accuracy for test dataset
test_accuracy = sess.run(
accuracy,
feed_dict={features: test_features, labels: test_labels})
print('Test Accuracy: {}'.format(test_accuracy))TensorFlow中的深度神经网络
利用Tensorflow来构建一个分类器对MNIST中的数字进行分类。
可以使用 TensorFlow 提供的 MNIST 数据集,他把分批和独热码都帮你处理好了。
TensorFlow MNIST
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(".",one_hot=True,reshape=False)Learning Parameters
import tensorflow as tf
learning_rate=0.001
training_epochs=20
batch_size=128
display_step=1
n_input=784
n_classes=10我们要处理的是28*28个像素点的灰度图,因此features的维度为784。
Hidden Layer Parameters
n_hidden_layer=256Weights and Biases
weights ={'hidden_layer':tf.Variable(tf.random_normal([n_input,n_hidden_layer])),'out':tf.Variable(tf.random_normal([n_hidden_layer,n_classes]))}
biases={'hidden_layer': tf.Variable(tf.random_normal([n_hidden_layer])), 'out': tf.Variable(tf.random_normal([n_classes])) } # tf.random_normal作用于list,因此要加中括号
# 从权重和偏置初始化字典的维度可以看出此系统为两层的神经网络Input
x = tf.placeholder("float",[None,28,28,1])
y = tf.placeholder("float",[None,n_classes]) #None 维度在这里是一个 batch size 的占位符。在运行时,TensorFlow 会接收任何大于 0 的 batch size。
x_flat = tf.reshape(x,[-1,n_input]) # -1代表将x变成n_input列,行数随x的原来的元素个数进行调整。MNIST 数据集是由 28px * 28px 单通道图片组成。tf.reshape()函数把 28px * 28px 的矩阵转换成了 784px * 1px 的单行向量 x。
Multilayer Perceptron
layer_1 = tf.add(tf.matmul(x_flat,weights['hidden_layer']),biases['hidden_layer'])
layer_1 = tf.nn.relu(layer_1)
logits = tf.add(tf.matmul(layer_1,weights['out']),biases['out']) #两层感知机Optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_logits(logits=logits,labels=y))
optimizer=tf.train.GrandientDescentOptimizer(learning_rate=learning_rate).minimize(cost) #利用梯度下降的方法最小化交叉熵Session
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(training_epochs):
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_x,batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
sess.run(optimizer,feed_dict={x:batch_x,y:batch_y})
# batch_x和batch_y分别为一个随机batch中的features输入和labels输入TensorFlow 中的 MNIST 库提供了分批接收数据的能力。调用mnist.train.next_batch()函数返回训练数据的一个子集。