全网最详细win10+anaconda+GPU+Tensorflow Object Detection API训练自己数据+新手教程+训练过程问题解决
参考链接:
anaconda安装gpu-tensorflow
tensorflow 在windows 下使用gpu
超详细的目标识别api训练教程
软硬件配置:
- cpu i7-6700hq -2.6GHz
- gpu gtx960M
- 内存8G
- windows10操作系统
- anaconda3,python3.5
- cuda8.0
- cudnn6.0
总效果:
输入一张图片(一个视频流也是一帧一帧图片组成的)——>模型——>输出需要识别物体在图片中的位置,和物体的类别
实现步骤:
配置好基本的软件环境(anaconda3、cuda8.0、cudnn6.0、tensorflow1.4、几个必要的包)-->下载好tensorflow/models-->
图片数据采集-->图片标注(labelImg)-->图片排序等预处理(自己编写一些小程序)-->分为xmls和images文件-->
将处理好的数据放到下载的目标检测api,即models包中-->生成tf_record文件-->训练模型(同时可以评估模型)-->导出模型-->测试模型-->
多试试,看看不同的效果~
前言:
1、关于faster_rcnn的介绍,大家可以看看知乎或者博客上的一些文章,推荐 一文读懂Faster R-CNN
不过,我觉得大概都看不懂,看懂了,改起来也挺麻烦的,其实只需要知道这个接口的优势性能就好了。
2、faster-rcnn分两步,先定位,再分类,而且可以多分类,还不受输入图片大小的限制。这样的网络基本上可以满足很多情况的使用,但是目前知道好像只能用方框进行定位,不能根据物体的实际形状进行完全精确的定位,不知道现在有没有更好的解决方案~
3、faster-rcnn关键点还是快,如果配置高的话,几乎可以本机实时识别,对视频流进行实时识别,这个就比较溜了~当然这个也只是达到了基本的门槛,目前我试过的几次,调用这个模型,消耗的资源还是蛮大的,图片越清晰自然就更大了~
4、ubuntu系统安装cuda总是失败,所以只好转战windows,具体的可以看看我前面的博客
5、这篇博客前后借鉴了好多博主的内容,综合他们的内容,加上自己踩的一些坑,以及一些小技巧,都列出来了。再次感谢~
1、安装anaconda:
目的:anaconda可以建立很多独立的python虚拟环境,可以替你管理很多乱七八糟的包,因为操作过程中,很容易会出现包的版本不兼容,可是卸载更容易出错,怎么办?到时候也许只能重装系统了~所以建议先安装anaconda.
Anaconda3-4.1.1-windows-x64.exe下载链接:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
安装和配置,参考链接:https://www.cnblogs.com/afangxin/p/6992050.html
需要设置国内镜像,输入命令:
# 添加Anaconda的TUNA镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
# TUNA的help中镜像地址加有引号,需要去掉
# 设置搜索时显示通道地址
conda config --set show_channel_urls yes安装完成以后,将prompt快捷键发送到桌面,打开prompt。建立一个虚拟环境,比如 gtf ,并安装需要的包。输入命令:
conda create -n gtf36 jupyter matplotlib pillow lxml python=3.5
经尝试,这种创建会比较卡,得多试几次。最好还是简单的创建环境
conda create -n gtf36 python=3.5然后激活环境:
activate gtf35conda install opencv需要安装的包,有jupyter,matplotlib,pillow,lxml,opencv,Cython
2、安装tensorflow-gpu版本:
1、不推荐:直接安装tensorflow(tf):
pip install --upgrade tensorflow-gpu目前安装的tf基本上自动安装版本都是1.7版本了~
2、如果需要安装其他版本,比如1.4.0版本,则需要离线安装,先下载
https://pypi.python.org/pypi/tensorflow-gpu/1.4.0
然后进入到下载目录,pip install tensorflow_gpu-1.4.0-cp35-cp35m-win_amd64.whl
推荐使用离线安装。
3、安装cuda8.0和cudnn6.0:
参考链接:http://ystyle.top/2017/01/06/tensorflow-zai-windows-xia-shi-yong-gpu/
版本是和tf配套的,如果tf版本过高,比如1.7,则cuda也得升级到9.0。但是听说版本高了会有一些bug。自己没有试过,不知道到底有没有坑~
1、下载软件:
附上国内容易下载的cuda8.0-win链接:
https://developer.nvidia.com/compute/cuda/8.0/prod/local_installers/cuda_8.0.44_win10-exe
或者这个,最好是这个,因为最后成功的就是这个:
https://pan.baidu.com/s/1c2tBiLE
cudnn6.0-win下载地址:
https://pan.baidu.com/s/1ko5kTFj5hTNrGEBpmqgs-A2、安装软件:
刚开始安装两次都是安装到一半就失败了,试过精简版自动安装,以及自定义。
后来查看了一下显卡驱动:计算机,管理,设备管理,看到显卡驱动有一个感叹号,
问题应该在这儿,应该是冲突了,于是我就自动搜索安装了需要的显卡驱动。
安装完毕,自动重启,重启完了之后,
点击第二个链接下载的cuda继续安装,精简版,
目录路径什么都不变,C盘就C盘吧,还能怎么办,,,还好一次性点亮。
如果出现了问题,就可以看看是不是显卡驱动的问题。
接下来把cudnn的东西放到该放的位置。
解压cudnn
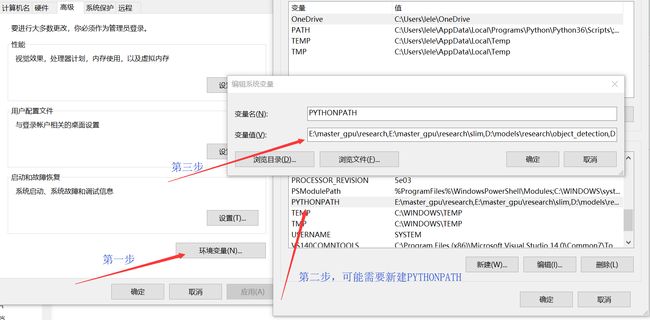
添加bin目录到环境变量PATH,不是PYTHONPATH。至于如何新建环境变量,这个可以自己搜百度经验~
安装好了可以试试,激活环境,输入:python。进入python命令环境,输入如下程序:import tensorflow as tf hello = tf.constant("hello tensorflow") sess = tf.Session() print(sess.run(hello))没有报错,并且显示cuda,那就ok了。
也可以试试nvcc -V,在命令行输入:nvcc -V会显示:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2016 NVIDIA Corporation
Built on Sat_Sep__3_19:05:48_CDT_2016
Cuda compilation tools, release 8.0, V8.0.44
抄的别人的一段话:记住安装完毕以后,一定不要随意升级驱动,不然后续出现驱动与硬件不兼容的问题。
往往出现这样的问题是最不容易排查的,由于CUDA开发的资料相对较少,
很多情况下百度和谷歌也搜不到相应的解决方法。自己也曾经为了一个小问题,搜索了二个星期,
尝试了不同的解决方案,终于在一个角落里,找到了问题所在,所以从事CUDA开发相对的门槛还是比较高的。
4、下载目标检测API:
参考链接:https://www.cnblogs.com/mar-q/p/7579263.html
下载模型https://github.com/tensorflow/models
解压放到需要的目录下,比如E盘根目录。
conda list 查看是否有protobuf,如果有了就不用管了,没有就输入conda install protobuf
5、配置API环境:
参考链接:https://www.cnblogs.com/mar-q/p/7579263.html
先修改一个模型的bug,这个bug是在github中找到解决方案的,在运行train.py程序的时候,会有一个报错:
ValueError: Tried to convert 't' to a tensor and failed. Error: Argument must be a dense tensor: range(0, 3) - got shape [3], but wanted [].
解决方案在这儿:
https://github.com/tensorflow/models/issues/3705#issuecomment-375563179
ps:多利用github和谷歌,百度搜索很多东西是没有的~
即进入models/research/object_detection/utils/learning_schedules.py 在167-169行,有这样的代码
rate_index = tf.reduce_max(tf.where(tf.greater_equal(global_step, boundaries),
range(num_boundaries),
[0] * num_boundaries))
修改成为:
rate_index = tf.reduce_max(tf.where(tf.greater_equal(global_step, boundaries),
list(range(num_boundaries)),
[0] * num_boundaries))如果你之前已经编译过protobufs,修改之后需要再编译一次,如果第一次安装,则跟着下面的步骤继续走。
1、编译Protobuf库,在object_detection同级目录打开终端运行:
cd E:\TensorFlow\GitHub\models\research
protoc object_detection\protos\*.proto --python_out=.没有显示啥,就算是运行成功了,打开protos可以看到里面生成了.py文件
2、在research目录下运行:
python setup.py install3、进入slim目录运行:
python setup.py install要是slim文件下已经有了BUILD,需要先删掉这个,然后再python setup.py install
4、添加环境变量:
添加到PYTHONPATH中,将research和slim目录添加进入环境变量。
返回research目录测试环境是否准备完毕:
python object_detection/builders/model_builder_test.py到这儿为止,基本上没有遇到报错,可以看到tensorflow1.4版本还是比较友好的
接下来就是处理自己的数据,然后进行训练的事儿了:
6、数据处理:
采集所需要识别物体的照片,图片分辨率大小规格都没啥关系,我们调用faster-rcnn算法,对图片大小不敏感。但是为了保证能识别出来,尽量清晰些。
在环境变化不大,识别物体种类不多的情况下,数据量可以在100-300左右,数据量越大越好。但是考虑到是自己标注数据,就必须得取一个自己扛得住的量。如果有大佬会数据合成的话,即标注现有的样本,然后通过图像处理的方式,在标注信息不变的情况下,对图片进行变换,增加样本。
我本来是想试试调节图片对比度、亮度,增加数据样本的,但是还没有找到好的算法,完全模拟出亮度的差异~
好了,假设你拍了300张有效的照片,放入images文件夹。(花了一天时间,学会了使用github上传自己的代码~)
详细的可以看这篇博客——https://blog.csdn.net/hehedadaq/article/details/79879752
所有的代码都在这儿——https://github.com/kaixindelele/tensorflow-models-data_diy.git
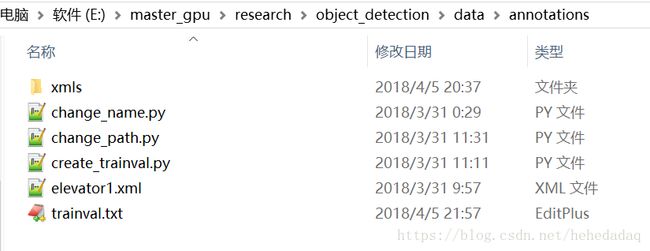
1、进入models/research/object_detection目录,进入data文件夹,创建annotations文件夹、images文件夹,再进入annotations,创建xmls
2、复制图片进入images,复制xml文件进入xmls
3、下载好create_trainval.py和change_name.py到annotations内,如果需要排序和改内容就可以执行这些脚本了
打开prompt,activate gtf ,进入环境,cd到这个目录下,然后执行
python create_trainval.py
4、如果需要合成数据的话,还是需要自己想办法的,要是有大佬做的话,可以艾特一下我
5、基本上数据处理好了,就可以生成tf_record文件了,退出到object_detection目录下,在上面的链接中,下载create_pet_tf_record.py,train.py,test_image.py,elevator_label_map.pbtxt,最后一个可以名字要是改的话,记得改所有需要pbtxt文件的名字,不改名字就方便了,先执行下面的程序吧:
python create_pet_tf_record.py生成的tf_record文件将会在object_detection目录下,370张1920*1080的照片,train部分得有180MB,如果太小,大概就是有问题了。
后面不加路径配置,是因为完全按照我们步骤来的,如果不是的话,那就比较复杂了~
可以看看其他教程,我也没试过

7、修改配置文件:
1、下载断点文件。在faster_rcnn训练过程中,不是从零开始训练的,而是在类似数据集,已经训练好的网络数据的基础上,继续训练,算是一种迁移训练,下载链接:http://download.tensorflow.org/models/object_detection/faster_rcnn_inception_v2_coco_2018_01_28.tar.gz
2、解压后后,把里面的那个文件夹放到object_detection目录下。
3、在object_detection\samples\configs目录下找到对应的.config文件,选择faster_rcnn_inception_v2_coco.config,修改num_classes为你自己的num_classes,这里我训练的只有三个类,改成3。然后修改其中5个路径:
112行 fine_tune_checkpoint: "E:\\master_gpu\\research\\object_detection\\faster_rcnn_inception_v2_coco_2018_01_28\\model.ckpt" 127行 input_path: "E:\\master_gpu\\research\\object_detection\\elevator_train.record" 129行 label_map_path: "E:\\master_gpu\\research\\object_detection\\elevator_label_map.pbtxt" 141行 input_path: "E:\\master_gpu\\research\\object_detection\\elevator_val.record" 143行 label_map_path: "E:\\master_gpu\\research\\object_detection\\elevator_label_map.pbtxt"第一个是上面的断点文件夹,model.ckpt不用变,后面四个都可以看出来了。
其他训练的配置信息可以自己研究一下,可以针对自己的数据集进行调整,但是比如训练步数,调整了会报错,不知道为啥。
8、开始训练:
1、上面都做好了,在object_detection目录下,建立一个training文件夹,用来保存自己训练断点的文件。而训练也就是执行一段命令了:
2、其中--logtostderr 不知道啥意思python train.py --logtostderr --train_dir=E:\\master_gpu\\research\\object_detection\\training --pipeline_config_path=E:\\master_gpu\\research\\object_detection\\faster_rcnn_inception_v2_coco.config
--train_dir=
后面加的是输出check_point的文件夹路径
--pipeline_config_path=
加的是配置文件的路径3、报错解决:
ValueError: Tried to convert 't' to a tensor and failed. Error: Argument must be a dense tensor: range(0, 3) - got shape [3], but wanted [].
解决方案在这儿:https://github.com/tensorflow/models/issues/3705#issuecomment-375563179记得重新编译一下~
就是research和slim两个install,这个上面有~基本上gpu和cpu,以及1.4,1.6的tf都会有这个错误,看github上的描述,是因为python3的问题~
这个问题我们上面已经解决了。
第二个报错
如果没有用我们新的train.py函数,应该会有这样的报错:
报错2:
AttributeError: module 'tensorflow.contrib.data' has no attribute 'parallel_interleave'
这个是因为train.py有问题,
需要用师兄给我的训练文件比源代码多了两个函数,虽然我也不知道这俩函数有啥用~
4、训练过程中,笔记本会很烫,记得散热!
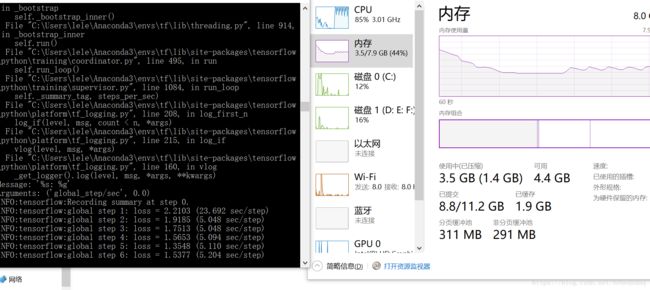
上面的数据量GPU大概需要0.3秒一步,cpu也试过,需要4.5秒一步。
刚开始的效果:
训练了20万步,大概18个小时,每步0.33秒的节奏
INFO:tensorflow:global step 200000: loss = 0.1098 (0.328 sec/step)
INFO:tensorflow:Stopping Training.
INFO:tensorflow:Finished training! Saving model to disk.
这是最后的输出显示。
使用gpu基本上是单独cpu的25倍速。可见如果不用gpu训练的话,肯定会很尴尬的,在loss值上,cpu训练18小时,一万多步,只能达到0.5的loss,而gpu最低和平均分别是0.01和0.1这样可以看出,gpu还是很有趣的。
5、如何停止训练?
在训练过程中如果去复制断点文件,会提示有一些文件无法复制,
虽然你最后发现和训练完的文件都一样,至少肉眼看不出有啥少的,但就是无法导出模型。
如果提前ctrl+c打断训练过程则不一样,这样训练断点文件还是可以导出模型的~
在训练的过程中,就算是让电脑睡眠,也会继续训练,所以千万别把这个本子塞包里带走,会热炸的。。。
9、模型评估:
这是一个失败的评估~
1、在dataset文件夹下新建evaluation文件夹,继续在detection目录下执行:
python eval.py --logtostderr --checkpoint_dir=E:\master_gpu\research\object_detection\training --pipeline_config_path=E:\master_gpu\research\object_detection\faster_rcnn_inception_v2_coco.config --eval_dir=E:\master_gpu\research\object_detection\evaluation
报错:
File"C:\Users\lele\Anaconda3\envs\gtf\lib\site-packages\object_detection-0.1-py3.5.egg\object_detection\metrics\coco_tools.py", line 47, in
from pycocotools import cocoImportError: No module named 'pycocotools'
根据教程下载cocoapi,又会发现unable find vcvarsall.bat,网上说要安装vs2015,安装了也没用~
这个问题的解决方案我还没找到,所以就放弃了evaluation~
不过这个也没关系~还可以挣扎,直接导出训练模型,,,只是无法直观的看出实时的精确度变化曲线,这样也就不知道训练是否过拟合了~
10、导出模型:
1、detection同目录下,其中:
- input_type后面的不用管,
- pipline还是配置文件路径,
- trained_checkpoint_prefix后面是训练过程的断点文件夹trianing。model.ckpt-198938是训练次数,
- output_directory是存放训练模型的文件夹,需要自己建立。
执行:
2、生成我们需要的python export_inference_graph.py --input_type=image_tensor --pipeline_config_path=E:\master_gpu\research\object_detection\faster_rcnn_inception_v2_coco.config --trained_checkpoint_prefix=E:\master_gpu\research\object_detection\training\model.ckpt-198938 --output_directory=E:\master_gpu\research\object_detection\pb
frozen_inference_graph.pb文件
11、调用模型:
1、如果有object_detection_tutorial.py,可以修改一下,但是如果是object_detection_tutorial.ipynb文件,就不好改了,也很难嵌入到需要的程序中;
2、所以下载test_image.py文件,在object_detection目录下,
3、发现,上次好像无法在gpu环境下,使用cpu训练出来的模型~
12、训练可视化-tensorboard:
在输入训练的命令以后,(也就是训练过程中,不是训练结束)我们打开一个新的prompt,进入相同的虚拟环境,进入train.py文件相同的路径,然后输入:
tensorboard --logdir=E:\master_gpu\research\object_detection\training即如下:
(gtf) E:\master_gpu\research\object_detection>tensorboard --logdir=E:\master_gpu\research\object_detection\training这个logdir,后面的是你训练过程中,存放断点数据的目录,一定要写对。
把 http://LAPTOP-D1QQCSFC:6006复制粘贴到谷歌浏览器中,然后就可以看到训练断点的过程了,好像有些浏览器打不开~
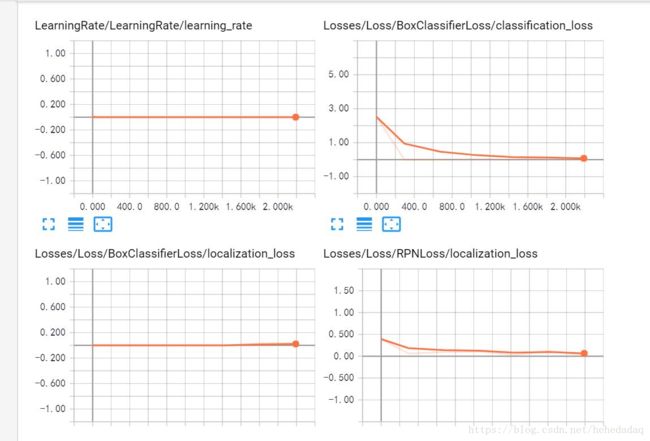
13、训练小技巧:
1、避免过拟合:大家可以看loss曲线,如果降得不太多了,就可以停止了。ctrl+c,不同的训练次数,多试几次,看看哪个效果好。
2、其他的以后想起来了再补充吧
14、2018.09.25更新:关于cuda和cudnn以及TensorFlow-GPU的版本匹配问题:
很明显,这也是一个非常恶心的问题,我已经在三台机子上,遇到了各种各样的bug,最糟心的是原来配好的环境,过了一段时间突然就不能用了!然后就一连串的不匹配!
昨天听室友的指导,直接在anaconda中创建一个新的虚拟环境,然后conda install tensorflow-gpu==1.8.0,换的是中科大的镜像源文件,这里的最新cudatoolkit是9.0,然后cudnn是7.1版本,是配置好的。我看了一下网站上也确实只有8.0和9.0这两个版本。
OK,我在9.0这个cudatoolkit上跑成功了。
给大家看一下效果:第一张加载模型,后面的时间都海星,下面再给大家看看,同样的模型,同样的数据,没有用GPU,调用的时间函数~
2018-09-25 08:38:03.628900: W C:\users\nwani\_bazel_nwani\mmtm6wb6\execroot\org_tensorflow\tensorflow\core\common_runtime\bfc_allocator.cc:219] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.43GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
每张图片运行时间:
6.345527648925781
--------------
每张图片运行时间:
1.3493921756744385
--------------
每张图片运行时间:
1.1449401378631592
--------------
每张图片运行时间:
0.8945975303649902
--------------
每张图片运行时间:
1.0701401233673096
CPU运行时间:
(tf) E:\models\research\object_detection>python test_image.py
2018-09-25 08:40:51.724263: I C:\tf_jenkins\workspace\rel-win\M\windows\PY\35\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
Tensorflow have not found GPU,run on CPU mode!
ok
每张图片运行时间:
6.292181968688965
--------------
每张图片运行时间:
3.382967948913574
--------------
每张图片运行时间:
3.152541399002075
--------------
每张图片运行时间:
3.010951519012451
--------------
每张图片运行时间:
3.1694912910461426可以看到CPU的运行时间基本上是稳定在3秒,而加了GPU,会稳定在1.2秒,感觉有点尴尬,为啥训练的时候GPU的速度会比CPU高一个数量级,而调用的时候只减少了一半?