python爬虫实战之模拟正方教务系统登录查询成绩
最近由于某些需要,开始入门Python网络爬虫,想通过一个Python程序来访问正方教务管理系统并且抓取到期末的成绩,由于我并没有深入了解过过其他的编程语言,所以,也比较不出Python和其他语言(如JAVA/PHP)的优缺点,只是因为我会Python,废话不多说,开工。
首先说一下,我们学校教务系统的网址是http://222.24.19.201,我想到的流程是,登入教务系统,然后访问查成绩的网址,将历年成绩抓取下来,这是一个很直观的流程,在程序中要做的就是1.登录, 2.访问 , 3.抓取,4.解析。当然,在这之前,首先要解决一个问题: 验证码。 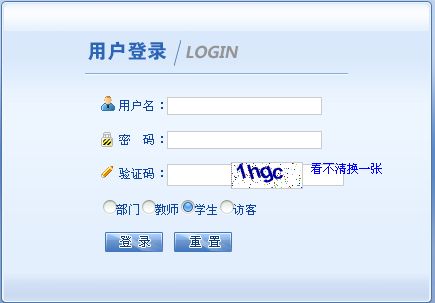
就是这样,验证码!我想到的第一个问题是OCR,可这个对我来说有点太复杂了,有其他的方法嘛,仔细观察, 
我们登录要提交的验证码,帐号密码其实是提交到了http://222.24.19.201/default2.aspx
,可是这并没有什么用,还是验证码,等等,注意到了default后面的2,那岂不是还有0,1,3,4…,抱着试一试的态度,尝试了一下,知道找到http://222.24.19.201/default6.aspx,终于看到了预期的结果。 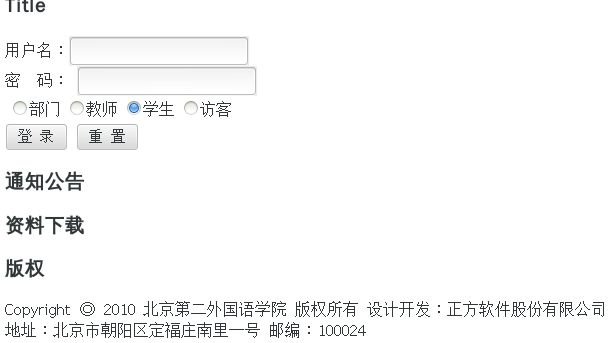
居然是北京第二外国语学院,贵圈真乱!由于我清楚222.24.19.201是邮电学院的IP,所以,我就在用户名和密码上填入了自己的用户名和密码,果不其然,登进去了,所以决定了,就从这个网址下手。 
接下来,就得看浏览器都干了些什么,我用的查看浏览器行为的是一款叫做HttpFox的扩展程序,如果你用的是Windows, 那么Fiddler也是一个不错的选择,这是这款程序的外观
当浏览器访问新的网页的时候,这个程序会跟踪追踪浏览器的行为(POST & GET 不了解的请自行百度)所以我们先来尝试访问一下 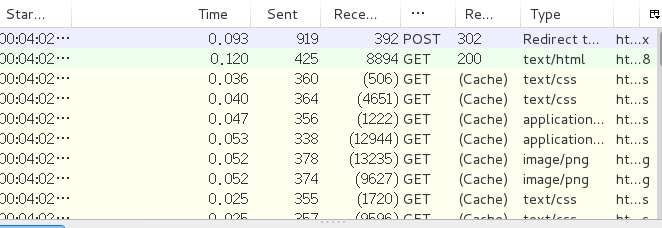
看到了POST, 我想知道我们向浏览器都提交了什么,点击POST, 查看POST DATA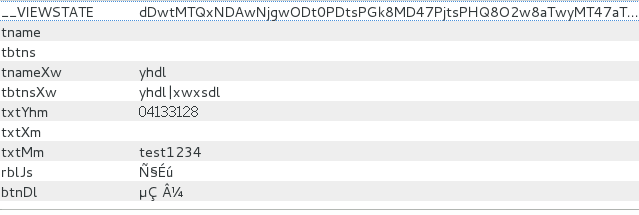
东西真多,我们需要将这些东西通过程序提交给服务器,值的说的是,乱码的一个是”学生” 一个是”登录”, 由于,教务系统的网站所用的编码是gb2312, 而它用utf-8的方式打开,所以,就乱了。。还有一个第一项—__VIEWSTATE这是asp.net框架特有的一个东西,详细用法自行百度,这里一定要加入(P.S 不要尝试登录朕的教务系统,这只是测试密码).
关于登录,我们必须要谈的一个话题是Cookie, 这不只是饼干,还是指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密),所以我们要做的第一件事就是获取这个网站的Cookie。Python提供了一个模块叫做cookielib,我们要构建一个cookie的处理器来存储访问网站所得的cookie
import urllib2
import cookielib
loginURL = 'http://222.24.19.201/default6.aspx'
cookie = cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
myRequest = urllib2.Request(loginURL, postdata,headers)- 1
- 2
- 3
- 4
- 5
- 6
这个步骤过后,cookie我们就获得了cookie, 因为待会要用到,所以我们用字符串可以存储,然后打印出来
for i in cookie:
Cookie = i.name+"="+i.value- 1
- 2
然后我们尝试登录,
page = urllib2.urlopen(loginURL).read()
postdata = urllib.urlencode({
'__VIEWSTATE':getVIEW(page),
'txtYhm':04133128, #std ID
'txtMm':'test1234', #password
'rblJs':'学生',
'btnDl':' 登录'})
headers = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.76 Safari/537.36'
}
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
myRequest = urllib2.Request(loginURL, postdata,headers)
loginPage = opener.open(myRequest).read()
page = unicode(loginPage, 'gb2312').encode("utf-8")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这样,主界面就存储到了page中。
接下来,我们就要开始往查成绩的界面走了, 继续HttpFox 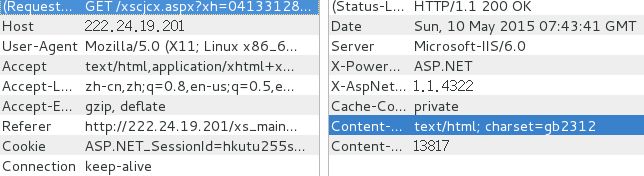
我们会发现查成绩的网址其实是
http://222.24.19.201/xscjcx.aspx?xh=04133128&xm=%CD%F5%BE%A9%B2%A9&gnmkdm=N121605
xm后面是本人名字的编码,其他的我就不做过多解释了,将这个网址放到浏览器中访问,结果出现了神奇的 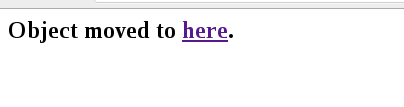
here是个网址,看下源码, 
Nothiing!!!!!醉了,哪里出问题了?百度之,没有准确答复,遂自行解决,这下,我用程序试试看
head = {
'Host':'222.24.19.201',
'Cookie':Cookie,
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.76 Safari/537.36'
}
getdata = urllib.urlencode({
'xh':04133128,
'xm':***,
'gnmkdm': 'N121605'
})
MyRequest= urllib2.Request('http://222.24.19.201/xscjcx.aspx?'+getdata,None, head) #According to this page ,we can get the viewstats
loginPage=unicode(opener.open(MyRequest).read(), 'gb2312').encode("utf-8")
data = urllib.urlencode({
"__VIEWSTATE":getVIEW(loginPage),
"btn_zcj":"历年成绩"
})
MyRequest= urllib2.Request('http://222.24.19.201/xscjcx.aspx?'+getdata,data, head) #Score's page
html = opener.open(MyRequest)
result = unicode(html.read(), 'gb2312').encode("utf-8")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
name栏的*是朕的名字。
打印result,居然变成了登录界面。。。是不是我的hander不全,人家访问的时侯hander request有那么多,抱着试试看的态度,我把他们全加上了所以, hander就成了这样
head = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'no-cache',
'Connection':'keep-alive',
'Content-Type':'application/x-www-form-urlencoded',
'Host':'222.24.19.201',
'Cookie':Cookie,
'Origin':'http://222.24.19.201',
'Pragma':'no-cache',
'Referer':'http://222.24.19.201/xs_main.aspx?xh='+ID,
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.76 Safari/537.36'
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
再次打印,居然登录进去了,果然是hander出了问题,经过了解,错在了一个选项叫做Referer, 这个东西是记录,你是从哪个网页跳转到这个网页的,这也就是为什么会有Object move to here 的原因,具体请百度”Referer”.接下来,我们要对得到的result进行解析,我用的是正则
str = r"<td>(.*)td><td>(.*)td><td>(.*)td><td>(.*)td><td>(.*)td><td>(.*)td><td>(.*)td><td>(.*)td><td>(.*)td><td>(.?)td><td>(.*)td><td>(.*)td><td>(.*)td><td>(.?)td><td>(.?)td>"- 1
正则写的太烂,勉强够用,,
这样我们就可以得到一项成绩,将之存储到一个列表中, 然后将课程名字与列表对应起来,构成一个字典,这样,完成了存储,大功告成!
这是我写的第一个Python网络爬虫程序,难免会有疏漏,请大家多多指出错误,谢谢。
有对源码感兴趣的请戳https://github.com/Penguin502/ScoreSpider。