互联网职位爬虫实现细节
互联网职位爬虫实现细节
本文是对互联网职位爬虫程序的流程进行基本的描述,概述了爬虫程序的运行流程,相关表结构,网页解析规则,反爬策略的应对措施等。
具体实现参考源码:https://github.com/laughoutloud61/jobSpider
开发环境
开发使用的框架:scrapy, scrapy-redis
开发使用的数据库(服务器):Elasticsearch, redis
实现目标
开发分布式爬虫系统,爬取目标网页(拉勾网)详细页面信息的抓取。并将抓取的信息进行清洗,存入Elasticsearch服务器中。
表结构的定义
分析详细页面,确定要爬取的信息
 根据页面信息分析,定义如下爬虫数据结构
根据页面信息分析,定义如下爬虫数据结构
class JobSpiderItem(Item):
id = Field(
input_processor=MapCompose(get_id)
)
job_name = Field()
url = Field()
salary = Field(
input_processor=MapCompose(extract_digital),
output_processor=MapCompose(get_value)
)
city = Field()
work_experience = Field(
input_processor=MapCompose(extract_digital),
output_processor=MapCompose(get_value)
)
education = Field(
input_processor=MapCompose(education_process)
)
skills = Field(
input_processor=MapCompose(extract_word),
output_processor=MapCompose(get_value)
)
tags = Field(
output_processor=MapCompose(get_value)
)
platform = Field()
release_time = Field(
input_processor=MapCompose(extract_time)
)
company_name = Field(
input_processor=MapCompose(str.split)
)
company_url = Field()
服务器的表结构定义如下(使用ORM方式定义生成表)
class JobsType(Document):
"""
定义Jobs的表结构
"""
id = Keyword()
suggest = Completion()
job_name = Text(
analyzer="ik_smart"
)
url = Keyword()
salary = Integer()
city = Keyword()
work_experience = Integer()
education = Keyword()
tags = Keyword()
platform = Keyword()
release_time = Date()
company_name = Keyword()
company_url = Keyword()
class Index:
name = 'job_search_engine'
settings = {
"number_of_shards": 5,
}
class Meta:
doc_type = 'jobs'
爬虫解析规则
解析网页的类继承的是scrapy-redis框架的RedisCrawlSpider类,该类主要试用于全站爬虫,rules属性定义了url的爬取规则,
parse_page方法则定义了职业信息页面的爬取规则。
class LagouSpider(RedisCrawlSpider):
name = 'lagou'
redis_key = 'lagou:start_urls'
allowed_domains = ['lagou.com']
start_urls = ['https://www.lagou.com/']
rules = (
Rule(LinkExtractor(allow=r'zhaopin/', tags=('a', ), attrs=('href', )), follow=True),
Rule(LinkExtractor(allow=r'jobs/\d+.html', tags=('a', ), attrs=('href', )), callback='parse_page', follow=True),
)
def start_requests(self):
for url in self.start_urls:
yield Request(url=url)
def parse_page(self, response):
"""
实现拉勾网职位详细页面的
信息提取
"""
loader = JobSpiderItemLoader(item=JobSpiderItem(), response=response)
loader.add_xpath('job_name', './/div[@class="position-head"]/div/div[@class="position-content-l"]/div/span[@class="name"]/text()')
loader.add_xpath('salary', './/div[@class="position-head"]/div/div[@class="position-content-l"]/dd/p/span[@class="salary"]/text()')
loader.add_xpath('work_experience', './/div[@class="position-head"]/div/div[@class="position-content-l"]/dd/p/span[3]/text()')
loader.add_xpath('education', './/div[@class="position-head"]/div/div[@class="position-content-l"]/dd/p/span[4]/text()')
loader.add_xpath('tags', './/div[@class="position-head"]/div/div[@class="position-content-l"]/dd/ul/li/text()')
loader.add_xpath('release_time', './/div[@class="position-head"]/div/div[@class="position-content-l"]/dd/p[@class="publish_time"]/text()')
loader.add_xpath('release_time', './/div[@class="position-head"]/div/div[@class="position-content-l"]/dd/p[@class="publish_time"]/text()')
loader.add_xpath('city', './/div[@class="content_l fl"]/dl/dd[@class="job-address clearfix"]/div/a[1]/text()')
loader.add_xpath('company_name', './/div[@class="content_r"]/dl/dt/a/div/h2/em/text()')
loader.add_xpath('company_url', './/div[@class="content_r"]/dl/dt/a/@href')
loader.add_xpath('skills', './/div[@class="content_l fl"]/dl/dd[@class="job_bt"]/div/p/text()')
loader.add_value('url', response.url)
loader.add_value('id', response.url)
loader.add_value('platform', "拉勾网")
yield loader.load_item()
爬虫程序流程
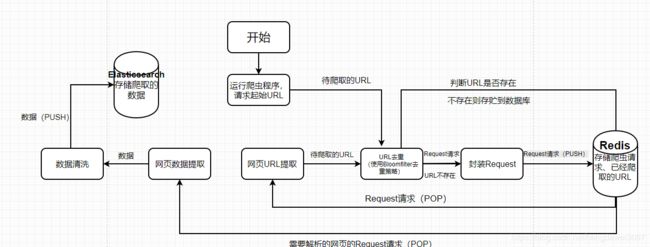
方爬虫策略应对措施
根据对拉勾网的实际分析中,发现网站基本2种反爬策略
- 检测同一ip请求频率,若请求频繁则认定为爬虫程序,在一段时间内将该ip的所有请求重定向
对于这种反爬策略,采取的最有效的方法则是在发送爬虫请求时使用代理ip(ProxyIp类实现细节请参考源码)
class ProxyIpMiddleware(object):
"""
代理ip池
"""
def __init__(self):
self.proxy = ProxyIp()
def process_request(self, request, spider):
request.meta['proxy'] = self.proxy.proxy_ip
request.headers['Proxy-Authorization'] = self.proxy.api_key.get('Proxy-Authorization')
- 检测请求头中的Cookie属性的值
在请求时带上Cookie即可
class RequestHeaderMiddleware(object):
"""
封装Request的headers属性
"""
headers={
'Cookie': '',
'User-Agent': '',
}
def __init__(self, crawler):
super(RequestHeaderMiddleware, self).__init__()
self.useragent = UserAgent(use_cache_server=False)
self.useragent_type = crawler.settings.get('USER_AGENT_TYPE', 'random')
def user_agent():
return getattr(self.useragent, self.useragent_type)
self.headers['User-Agent'] = user_agent()
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
if spider.name == 'lagou':
cookie = 'user_trace_token=20190426112028-fc63781e-09d0-4377-8e2e-f528bf604b59; _ga=GA1.2.749963560.1556248830; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1559621873; LGUID=20190426112035-419a8eb0-67d2-11e9-9d14-5254005c3644; X_HTTP_TOKEN=31bb0800e7a2adec561896955146f691979cb4c961; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1559698165; LGRID=20190605092925-5a9f3412-8731-11e9-a1f4-5254005c3644; _gid=GA1.2.111518419.1559621941; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216b20b636353e5-0a5bb266d9c254-3a684645-2073600-16b20b6363632c%22%2C%22%24device_id%22%3A%2216b20b636353e5-0a5bb266d9c254-3a684645-2073600-16b20b6363632c%22%7D; LG_LOGIN_USER_ID=""; LG_HAS_LOGIN=1; _putrc=""; JSESSIONID=ABAAABAAAIAACBI8C56A3BE8D0C1340D95F3AD04AB6F09D; login=false; unick=""; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_navigation; SEARCH_ID=b56e84a534e945a48770f1716f7a1e3f; LGSID=20190605092005-0cd61358-8730-11e9-aa08-525400f775ce; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F'
# 设置headers
self.headers['Cookie'] = cookie
for key, val in self.headers.items():
request.headers[key] = val