大数据学习笔记-------------------(28)
第28章 HIVEQL
HIVEQL(HIVEQuery Language:Hive查询语言)是一种查询语言,该语言为Hive处理并分析Metastore的结构数据。
28.1查询语句(SELECT ...WHERE)
SELECT语句被用于检索表中的数据。WHERE子句的工作原理类似于条件。它用条件过滤数据并给出一个有限结果。内置的运算符和函数生成一个满足条件的表达式。SELECT查询语法如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT number];28.1.1查询语句实例
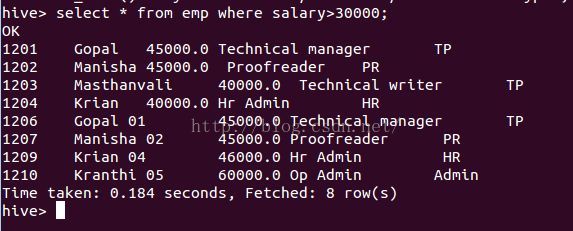
根据emp表,生成一个查询来检索薪资大于30000的用户详细信息。执行如下查询检索薪资大于30000的员工详细信息:SELECT * FROM emp WHEREsalary>30000; 执行语句成功后,会获取如下:
28.1.2JDBC查询语句实例
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLWhere
{
private static String driverName ="org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException
{
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:9000/hive", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM emp WHERE salary>30000;");
System.out.println("Result:");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next())
{
System.out.println(res.getInt(1)+" "+ res.getString(2)+" "+
res.getDouble(3)+" "+ res.getString(4)+" "+ res.getString(5));
}
con.close();
}
} 保存程序到文件HiveQLWhere.java文件中,执行如下语句进行编译和运行程序:
$ javac HiveQLWhere.java
$ java HiveQLWhere
28.2查询语句(SELECT...ORDER BY)
ORDERBY子句被用来检索基于一列且对结果进行升序或将序的详细信息。语法如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[ORDER BY col_list]]
[LIMIT number];28.2.1ORDER BY查询语句实例
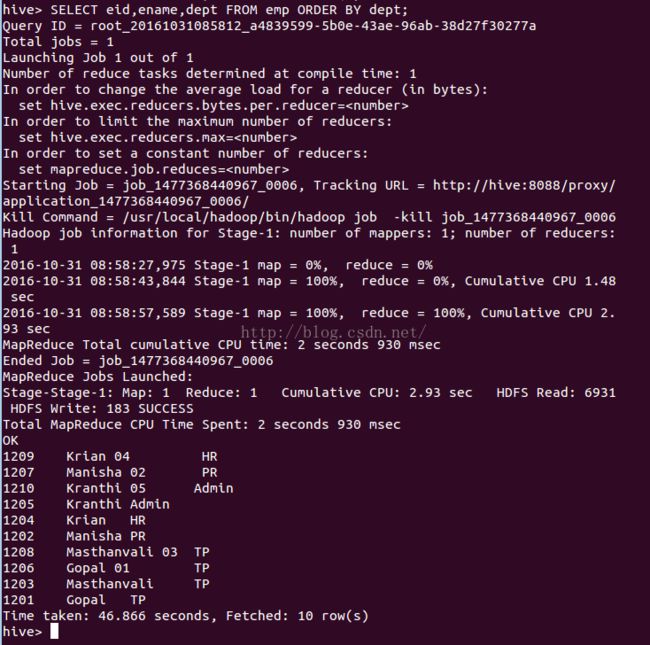
根据emp表,生成一个查询来检索以dept进行排序的用户详细信息。执行如下查询检索员工详细信息:
SELECT eid,ename,dept FROMemp ORDER BY dept;执行语句成功后,会获取如下:
28.2.2JDBC ORDER BY 查询语句实例
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLOrderBy
{
private static String driverName ="org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException
{
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:9000/hive", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM emp ORDER BY DEPT;");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next())
{
System.out.println(res.getInt(1)+" "+ res.getString(2)+" "+
res.getDouble(3)+" "+ res.getString(4)+" "+ res.getString(5));
}
con.close();
}
}保存程序到文件HiveQLOrderBy.java文件中,执行如下语句进行编译和运行程序:
$ javac HiveQLOrderBy.java
$ java HiveQLOrderBy
28.3查询语句(GROUP BY)
GROUP BY子句使用特定的集合对结果集中的所有记录进行分组。 它用于查询一组记录,语法如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[ORDER BY col_list]]
[LIMIT number];28.3.1GROUP BY查询语句实例
根据emp表,生成一个查询来检索以dept进行分组的用户详细信息。执行如下查询检索员工详细信息:
SELECT dept AS Dept,count(*) AS DeptNum FROM emp GROUP BY dept;执行语句成功后,会获取如下:

28.3.2JDBC GROUP BY查询语句实例
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLGroupBy
{
private static String driverName ="org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException
{
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:9000/hive", "", "");
// create statement
Statement stmt = con.createStatement();
//execute statement
Resultset res = stmt.executeQuery("SELECT Dept,count(*)"
+"FROM employee GROUP BY DEPT; "");
System.out.println(" Dept \t count(*)");
while (res.next())
{
System.out.println(res.getString(1)+" "+ res.getInt(2));
}
con.close();
}
} 保存程序到文件HiveQLGroupBy.java文件中,执行如下语句进行编译和运行程序:
$ javac HiveQLGroupBy.java
$ java HiveQLGroupBy
28.4查询语句(JOIN)
JOINS是一个子句,用于通过使用每个表的公共值来组合两个表的特定字段。它用于组合数据库中两个或多个表的记录。它或多或少类似于SQLJOINS。语法:
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference
join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition]28.4.1JOIN查询语句实例
创建一个名为CUSTOMERS的表格,并插入输入,然后验证数据是否插入成功,执行语句和数据如下所示:

创建一个名为ORDERS表,并插入数据,然后验证数据是否插入成功,执行语句如下和查询结果显示如下:

JOIN的类型如下所示:JOIN、LEFT OUTER JOIN、RIGHT OUTER JOIN、FULL OUTER JOIN。
28.4.1.1 JOIN
JOIN子句备用做联合和检索多个表格的记录。JOIN和SQL中的OUTER JOIN的类似。使用表的主键和外键来提高JOIN条件。
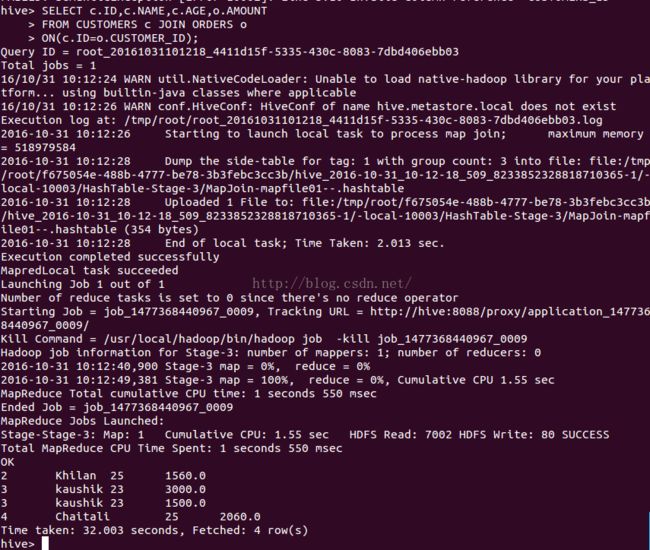
执行查询用来执行CUSTOMER和ORDER 表的JOIN,检索记录如下,执行语句如下:
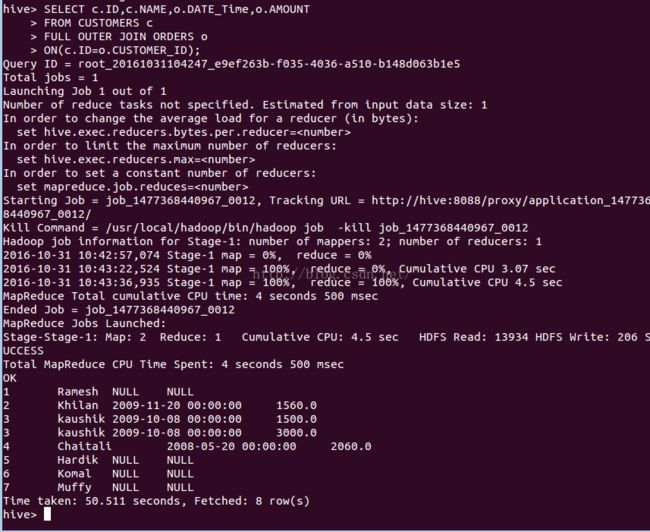
SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
FROM CUSTOMERS c JOIN ORDERS o
ON (c.ID = o.CUSTOMER_ID);执行成功,显示信息如下:
28.4.1.2 左连接(LEFEOUTER JOIN)
HiveQLLEFT OUTER JOIN返回左连接表的所有行,即使右表没有任何匹配。如果ON子句匹配右表中的0(零)记录,则JOIN仍然在结果中返回一行,但在右表的每列中返回NULL。一个左连接(LEFTJOIN)返回左表的所有值,加上右表匹配的值,或如果没有匹配的JOIN谓词,则为NULL。以下查询演示CUSTOMER和ORDER表之间的LEFT OUTER JOIN:
SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
FROM CUSTOMERS c
LEFT OUTER JOIN ORDERS o
ON (c.ID = o.CUSTOMER_ID);
28.4.1.3 右连接(RIGHTOUTER JOIN)
HiveQLRIGHT OUTER JOIN返回右表中的所有行,即使左表中没有匹配项。如果ON子句与左表中的0(零)记录匹配,则JOIN仍返回结果中的一行,但在左表的每列中都为NULL。RIGHTJOIN返回右表中的所有值,加上左表中匹配的值,或者在没有匹配连接谓词的情况下返回NULL。以下查询演示CUSTOMER和ORDER表之间的RIGHTOUTER JOIN。
SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
FROM CUSTOMERS c
RIGHT OUTER JOIN ORDERS o
ON (c.ID = o.CUSTOMER_ID);执行结果如下:

28.4.1.4 全连接(FULLOUTER JOIN)
HiveQLFULL OUTER JOIN组合满足JOIN条件的左侧和右侧外表的记录。 联接表包含来自这两个表的所有记录,或者在任一侧填充NULL值用于缺少匹配。以下查询演示CUSTOMER和ORDERS表之间的FULLOUTER JOIN:
SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
FROM CUSTOMERS c
FULL OUTER JOIN ORDERS o
ON (c.ID = o.CUSTOMER_ID);执行结果如下: