见微知著:细粒度图像分析进展
作者简介:魏秀参,南京大学计算机系机器学习与数据挖掘所(LAMDA)博士生,专攻计算机视觉和机器学习。曾在国际顶级期刊和会议发表多篇学术论文,并两次获得国际计算机视觉相关竞赛冠亚军。
责编:何永灿,欢迎人工智能领域技术投稿、约稿、给文章纠错,请发送邮件至[email protected]
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2017年《程序员》
有别于通用图像分析任务,细粒度图像分析的所属类别和粒度更为精细,它不仅能在更细分的类别下对物体进行识别,就连相似度极高的同一物种也能区别开来。本文将分别围绕“细粒度图像分类”和“细粒度图像检索”两大经典图像问题来展开,从而使读者对细粒度图像分析领域有全面的理解。
大家应该都会有这样的经历:逛街时看到路人的萌犬可爱至极,可仅知是“犬”殊不知其具体品种;初春踏青,见那姹紫嫣红丛中笑,却桃杏李傻傻分不清……实际上,类似的问题在实际生活中屡见不鲜。如此问题为何难?究其原因,是普通人未受过针对此类任务的专门训练。倘若踏青时有位资深植物学家相随,不要说桃杏李花,就连差别甚微的青青河边草想必都能分得清白。为了让普通人也能轻松达到“专家水平”,人工智能的研究者们希望借助计算机视觉技术(Computer Vision,CV)来解决这一问题。如上所述的这类任务在CV研究中有个专门的研究方向,即“细粒度图像分析”(Fine-Grained Image Analysis)。
细粒度图像分析任务相对通用图像(General/Generic Images)任务的区别和难点在于其图像所属类别的粒度更为精细。以图1为例,通用图像分类其任务诉求是将“袋鼠”和“狗”这两个物体大类(蓝色框和红色框中物体)分开,可见无论从样貌、形态等方面,二者还是很容易被区分的;而细粒度图像的分类任务则要求对“狗”该类类别下细粒度的子类,即分别为“哈士奇”和“爱斯基摩犬”的图像分辨开来。正因同类别物种的不同子类往往仅在耳朵形状、毛色等细微处存在差异,可谓“差之毫厘,谬以千里”。不止对计算机,对普通人来说,细粒度图像任务的难度和挑战无疑也更为巨大。

在此,本文针对近年来深度学习方面的细粒度图像分析任务,分别从“细粒度图像分类”(Fine-Grained Image Classification)和“细粒度图像检索”(Fine-Grained Image Retrieval)两大经典图像问题进行进展综述,以期读者可以对细粒度图像分析领域提纲挈领地窥得全貌。
细粒度图像分类
诚如刚才提到,细粒度物体的差异仅体现在细微之处。如何有效地对前景对象进行检测,并从中发现重要的局部区域信息,成为了细粒度图像分类算法要解决的关键问题。对细粒度分类模型,可以按照其使用的监督信息的强弱,分为“基于强监督信息的分类模型”和“基于弱监督信息的分类模型”两大类。
基于强监督信息的细粒度图像分类模型
所谓“强监督细粒度图像分类模型”是指:在模型训练时,为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框(Object Bounding Box)和部位标注点(Part Annotation)等额外的人工标注信息,如图2所示。

下面介绍基于强监督信息细粒度分类的几个经典模型。
Part-based R-CNN
相信大家一定对R-CNN不陌生,顾名思义,Part-based R-CNN就是利用R-CNN算法对细粒度图像进行物体级别(例如鸟类)与其局部区域(头、身体等部位)的检测,其总体流程如图3所示。

首先利用Selective Search等算法在细粒度图像中产生物体或物体部位可能出现的候选框(Object Proposal)。之后用类似于R-CNN做物体检测的流程,借助细粒度图像中的Object Bounding Box和Part Annotation可以训练出三个检测模型(Detection Model):一个对应细粒度物体级别检测;一个对应物体头部检测;另一个则对应躯干部位检测。然后,对三个检测模型得到的检测框加上位置几何约束,例如,头部和躯干的大体方位,以及位置偏移不能太离谱等。这样便可得到较理想的物体/部位检测结果(如图3右上)。接下来将得到的图像块(Image Patch)作为输入,分别训练一个CNN,则该CNN可以学习到针对该物体/部位的特征。最终将三者的全连接层特征级联(Concatenate)作为整张细粒度图像的特征表示。显然,这样的特征表示既包含全部特征(即物体级别特征),又包含具有更强判别性的局部特征(即部位特征:头部特征/躯干特征),因此分类精度较理想。但在Part-based R-CNN中,不仅在训练时需要借助Bounding Box和Part Annotation,为了取得满意的分类精度,在测试时甚至还要求测试图像提供Bounding Box。这便限制了Part-based R-CNN在实际场景中的应用。
Pose Normalized CNN
有感于Part-based R-CNN,S. Branson等人提出在用DPM算法得到Part Annotation的预测点后同样可以获得物体级别和部位级别的检测框,如图4所示。与之前工作不同的是,Pose Normalized CNN对部位级别图像块做了姿态对齐操作。此外,由于CNN不同层的特征具有不同的表示特性(如浅层特征表示边缘等信息,深层特征更具高层语义),该工作还提出应针对细粒度图像不同级别的图像块,提取不同层的卷积特征。在图4中,我们针对全局信息,提取FC8特征;基于头部信息则提取最后一层卷积层特征作为特征表示。最终,还是将不同级别特征级联作为整张图像的表示。如此的姿态对齐操作和不同层特征融合方式,使得Pose Normalized CNN在使用同样多标记信息时取得了相比Part-based R-CNN高2%的分类精度。

Mask-CNN
最近,我们也针对细粒度图像分类问题提出了名为Mask-CNN的模型。同上,该模型亦分为两个模块,第一是Part Localization;第二是全局和局部图像块的特征学习。需要指出的是,与前两个工作的不同在于,在Mask-CNN中,我们提出借助FCN学习一个部位分割模型(Part-Based Segmentation Model)。其真实标记是通过Part Annotation得到的头部和躯干部位的最小外接矩形,如图5(c)所示。在FCN中,Part Localization这一问题就转化为一个三分类分割问题,其中,一类为头部、一类为躯干、最后一类则是背景。

FCN训练完毕后,可以对测试集中的细粒度图像进行较精确地part定位,图6展示了一些定位效果图。可以发现,基于FCN的part定位方式可以对大多数细粒度图像进行较好的头部和躯干定位。同时,还能注意到,即使FCN的真实标记是粗糙的矩形框,但其预测结果中针对part稍精细些的轮廓也能较好地得到。在此,我们称预测得到的part分割结果为Part Mask。不过,对于一些复杂背景图像(如图6右下)part定位结果还有待提高。

在得到Part Mask后,可以通过Crop获得对应的图像块。同时,两个Part Mask组合起来刚好可组成一个较完整的Object Mask。同样,基于物体/部位图像块,Mask-CNN训练了三个子网络。
在此需要特别指出的是,在每个子网络中,上一步骤中学到的Part/Object Mask还起到了一个关键作用,即“筛选关键卷积特征描述子”(Selecting Useful Convolutional Descriptor),如图7(c)-(d)。这个模块也是我们首次在细粒度图像分类中提出的。筛选特征描述子的好处在于,可以保留表示前景的描述子,而去除表示背景的卷积描述子的干扰。筛选后,对保留下来的特征描述子进行全局平均和最大池化(Global Average/Max Pooling)操作,后将二者池化后的特征级联作为子网络的特征表示,最后将三个子网特征再次级联作为整张图像的特征表示。

实验表明,基于筛选的Mask-CNN在仅依靠训练时提供的Part Annotation(不需要Bounding Box,同时测试时不需额外监督信息)取得了目前细粒度图像分类最高的分类精度(在经典CUB数据上,基于ResNet的模型对200类不同鸟类分类精度可达87.3%)。此外,借助FCN学习Part Mask来进行Part定位的做法也取得了Part定位的最好结果。
基于弱监督信息的细粒度图像分类模型
虽然上述三种基于强监督信息的分类模型取得了较满意的分类精度,但由于标注信息的获取代价十分昂贵,在一定程度上也局限了这类算法的实际应用。因此,目前细粒度图像分类的一个明显趋势是,希望在模型训练时仅使用图像级别标注信息,而不再使用额外的Part Annotation信息时,也能取得与强监督分类模型可比的分类精度。这便是“基于弱监督信息的细粒度分类模型”。细粒度分类模型思路同强监督分类模型类似,也需要借助全局和局部信息来做细粒度级别的分类。而区别在于,弱监督细粒度分类希望在不借助Part Annotation的情况下,也可以做到较好的局部信息的捕捉。当然,在分类精度方面,目前最好的弱监督分类模型仍与最好的强监督分类模型存在差距(分类准确度相差约1%~2%)。下面介绍三个弱监督细粒度图像分类模型的代表。
- Two Level Attention Model
顾名思义,该模型主要关注两个不同层次的特征,分别是物体级别和部件级别信息。当然,该模型并不需要数据集提供这些标注信息,完全依赖于本身的算法来完成物体和局部区域的检测。其整体流程如图8所示。

该模型主要分为三个阶段。1. 预处理模型:从输入图像中产生大量的候选区域,对这些区域进行过滤,保留包含前景物体的候选区域;2. 物体级模型:训练一个网络实现对对象级图像进行分类;在此需要重点介绍的是,3. 局部级模型。我们来看,在不借助Part Annotation的情况下,该模型怎样做到Part检测。
由于预处理模型选择出来的这些候选区域大小不一,有些可能包含了头部,有些可能只有脚。为了选出这些局部区域,首先利用物体级模型训练的网络来对每一个候选区域提取特征。接下来,对这些特征进行谱聚类,得到K个不同的聚类簇。如此,则每个簇可视为代表一类局部信息,如头部、脚等。这样,每个簇都可以被看做一个区域检测器,从而达到对测试样本局部区域检测的目的。
- Constellations
Constellations方案是利用卷积网络特征本身产生一些关键点,再利用这些关键点来提取局部区域信息。对卷积特征进行可视化分析(如图9所示),发现一些响应比较强烈的区域恰好对应原图中一些潜在的局部区域点。因此,卷积特征还可以被视为一种检测分数,响应值高的区域代表着原图中检测到的局部区域。不过,特征输出的分辨率与原图相差较大,很难对原图中的区域进行精确定位。受到前人工作的启发,我采用的方法是通过计算梯度图来产生区域位置。

具体而言,卷积特征的输出是一个W×H×P维的张量,P表示通道的个数,每一维通道可以表示成一个W×H维的矩阵。通过计算每一维通道P对每一个输入像素的平均梯度值,可以得到与原输入图像大小相同的特征梯度图:
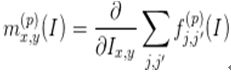
上面公式可以通过反向传播高效地完成计算。这样,每一个通道的输入都可以转换成与原图同样大小的特征梯度图。在特征梯度图中响应比较强烈的区域,即可代表原图中的一个局部区域。于是每一张梯度图中响应最强烈的位置即作为原图中的关键点:
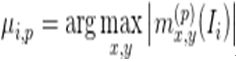
卷积层的输出共有P维通道,可分别对应于P个关键点位置。后续对这些关键点或通过随机选择或通过Ranking来选择出重要的M个。得到关键点后分类就是易事啦。其分类处理流程如图10所示。

- Bilinear CNN
深度学习成功的一个重要精髓,就是将原本分散的处理过程,如特征提取,模型训练等,整合进了一个完整的系统,进行端到端的整体优化训练。不过,在以上所有的工作中,我们所看到的都是将卷积网络当做一个特征提取器,并未从整体上进行考虑。最近,T.-Y. Lin、A.RoyChowdhury等人设计了一种端到端的网络模型Bilinear CNN,在CUB200-2011数据集上取得了弱监督细粒度分类模型的最好分类准确度。
如图11所示,一个Bilinear模型Β由一个四元组组成:Β=(fA,fB,Ρ,C)。其中,fA,fB代表特征提取函数,即图中的网络A、B,P是一个池化函数(Pooling Function), C则是分类函数。
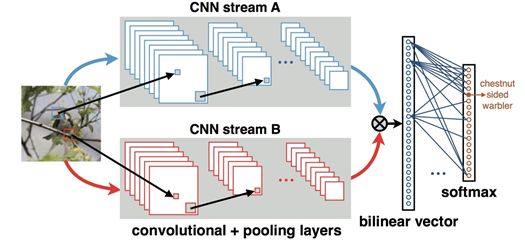
特征提取函数f (•)的作用可以看作一个函数映射,f:LXI→RcXD将输入图像I与位置区域L映射为一个cXD 维的特征。而两个特征提取函数的输出,可以通过一个双线性操作进行汇聚,得到最终的Bilinear特征:![]() .其中池化函数 的作用是将所有位置的Bilinear特征汇聚成一个特征。Bilinear CNN中所采用的池化函数是将所有位置的Bilinear特征累加起来:
.其中池化函数 的作用是将所有位置的Bilinear特征汇聚成一个特征。Bilinear CNN中所采用的池化函数是将所有位置的Bilinear特征累加起来: 到此Bilinear向量即可表示该细粒度图像,后续则为经典的全连接层进行图像分类。一种对Bilinear CNN模型的解释是,网络A的作用是对物体/部件进行定位,即完成前面介绍算法的物体与局部区域检测工作,而网络B则是用来对网络A检测到的物体位置进行特征提取。两个网络相互协调作用,完成了细粒度图像分类过程中两个最重要的任务:物体、局部区域的检测与特征提取。另外,值得一提的是,Bilinear模型由于其优异的泛化性能,不仅在细粒度图像分类上取得了优异效果,还被用于其他图像分类任务,如行人重检测(Person Re-ID)。
到此Bilinear向量即可表示该细粒度图像,后续则为经典的全连接层进行图像分类。一种对Bilinear CNN模型的解释是,网络A的作用是对物体/部件进行定位,即完成前面介绍算法的物体与局部区域检测工作,而网络B则是用来对网络A检测到的物体位置进行特征提取。两个网络相互协调作用,完成了细粒度图像分类过程中两个最重要的任务:物体、局部区域的检测与特征提取。另外,值得一提的是,Bilinear模型由于其优异的泛化性能,不仅在细粒度图像分类上取得了优异效果,还被用于其他图像分类任务,如行人重检测(Person Re-ID)。
细粒度图像检索
以上介绍了细粒度图像分类的几个代表性工作。图像分析中除监督环境下的分类任务,还有另一大类经典任务——无监督环境下的图像检索。相比细粒度图像分类,检索任务上的研究开展较晚,下面重点介绍两个该方面的工作。
图像检索(Image Retrieval)按检索信息的形式,分为“以文搜图”(Text-Based)和“以图搜图”(Image-Based)。在此我们仅讨论以图搜图的做法。传统图像检索任务一般是检索类似复制的图像(Near-Duplicated Images),如图12(b)所示。左侧单列为Query图像,右侧为返回的正确检索结果。可以看到,传统图像检索中图像是在不同光照不同时间下同一地点的图像,这类图像不会有形态、颜色、甚至是背景的差异。

而细粒度图像检索,如图13(a),则需要将同为“绿头鸭”的图像从众多不同类鸟类图像中返回;同样,需要将“劳斯莱斯幻影”从包括劳斯莱斯其他车型的不同品牌不同车型的众多图像中检索出来。细粒度图像检索的难点,一是图像粒度非常细微;二是对细粒度图像而言,哪怕是属于同一子类的图像本身也具有形态、姿势、颜色、背景等巨大差异。可以说,细粒度图像检索是图像检索领域和细粒度图像分析领域的一项具有新鲜生命力的研究课题。

L. Xie、J. Wang等在2015年首次提出细粒度图像“搜索”的概念,通过构造一个层次数据库将多种现有的细粒度图像数据集和传统图像检索(一般为场景)融合。在搜索时,先判断其隶属的大类,后进行细粒度检索。其所用特征仍然是人造图像特征(SIFT等),基于图像特征可以计算两图相似度,从而返回检索结果(如图14所示)。

SCDA
SCDA(Selective Convolutional Descriptor Aggregation)是我们近期提出的首个基于深度学习的细粒度图像检索方法。同其他深度学习框架下的图像检索工作一样,在SCDA中,细粒度图像作为输入送入Pre-Trained CNN模型得到卷积特征/全连接特征(如图15所示)。区别于传统图像检索的深度学习方法,针对细粒度图像检索问题,我们发现卷积特征优于全连接层特征,同时创新性的提出要对卷积描述子进行选择。不过SCDA与之前提到的Mask-CNN的不同点在于,在图像检索问题中,不仅没有精细的Part Annotation,就连图像级别标记都无从获取。这就要求算法在无监督条件下依然可以完成物体的定位,根据定位结果进行卷积特征描述子的选择。对保留下来的深度特征,分别做以平均和最大池化操作,之后级联组成最终的图像表示。

很明显,在SCDA中,最重要的就是如何在无监督条件下对物体进行定位。通过观察得到的卷积层特征(如图16所示),可以发现明显的“分布式表示”特性。对两种不同鸟类/狗,同一层卷积层的最强响应也差异很大。如此一来,单独选择一层卷积层特征来指导无监督物体定位并不现实,同时全部卷积层特征都拿来帮助定位也不合理。例如,对于第二张鸟的图像来说,第108层卷积层较强响应竟然是一些背景的噪声。

基于这样的观察,我们提出将卷积特征(HxWxD)在深度方向做加和,之后可以获得Aggregation Map(HxWx1)。在这张二维图中,可以计算出所有HxW个元素的均值,而此均值m便是该图物体定位的关键:Aggregation Map中大于m的元素位置的卷积特征需保留;小于的则丢弃。这一做法的一个直观解释是,细粒度物体出现的位置在卷积特征张量的多数通道都有响应,而将卷积特征在深度方向加和后,可以将这些物体位置的响应累积——有点“众人拾柴火焰高”的意味。而均值则作为一把“尺子”,将“不达标”的响应处标记为噪声,将“达标”的位置标为物体所在。而这些被保留下来的位置,也就对应了应保留卷积特征描述子的位置。后续做法类似Mask-CNN。实验中,在细粒度图像检索中,SCDA同样获得了最好结果;同时SCDA在传统图像检索任务中,也可取得同目前传统图像检索任务最好方法相差无几(甚至优于)的结果(如图17所示)。

展望
细粒度图像分析任务在过去的十年里一直是计算机视觉中的热门研究领域,尤其在深度学习繁荣的近几年,方法和问题可谓“常做常新”。不过随着深度学习方法研究的深入,在传统细粒度图像分析问题上,如鸟类、狗、车等子类分类和检索,尤其分类问题的准确率,可以说是到了瓶颈期。虽然时常会有不少细粒度图像分类工作问世,但每年也大概只能将分类准确率提升1个百分点左右(在经典的鸟类分类上,目前强监督分类模型为87.3%左右,弱监督模型为84.1%左右)。这便催生了细粒度图像分析任务的不同设定,如基于网络数据的细粒度图像分类、基于wiki知识获取的细粒度图像分类等。
同时,更加广义的“细粒度图像分析”研究也越来越多。常见的行人重检测(Person Re-ID)、人脸判别(Face Verification)、示例级别检索(Instance Retrieval)等问题都可以用传统细粒度图像分析的思路去解决,也期待更加优秀的相关研究出现。
参考文献
[1] N. Zhang, J. Donahue, R. Girshick, and T. Darrell. Part-based R-CNNs for fine-grained category detection. In European Conference on Computer Vision, Part I, LNCS 8689, pages 834–849, Zurich, Switzerland, Sept. 2014. Springer, Switzerland.
[2] S. Branson, G. V. Horn, S. Belongie, and P. Perona. Bird species categorization using pose normalized deep convolutional nets. In British Machine Vision Conference, pages 1–14, Nottingham, England, Sept. 2014.
[3] S. Branson, O. Beijbom, and S. Belongie. Efficient large-scale structured learning. In IEEE Conference on Computer Vision and Pattern Recognition, In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pages 1806–1813, Portland, Oregon, Jun. 2013.
[4] X.-S. Wei, C.-W. Xie and J. Wu. Mask-CNN: Localizing Parts and Selecting Descriptors for Fine-Grained Image Recognition. arXiv:1605.06878, 2016.
[5] T. Xiao, Y. Xu, K. Yang, J. Zhang, Y. Peng, and Z. Zhang. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pages 842–850, Boston, MA, Jun. 2015.
[6] M. Simon and E. Rodner. Neural activation constellations: Unsupervised part model discovery with convolutional networks. In Proceedings of IEEE International Conference on Computer Vision, pages 1143–1151, Sandiago, Chile, Dec. 2015.
[7] T.-Y. Lin, A. RoyChowdhury, and S. Maji. Bilinear CNN models for fine-grained visual recognition. In Proceedings of IEEE International Conference on Computer Vision, pages 1449–1457, Sandiago, Chile, Dec. 2015.
[8] L. Xie, J. Wang, B. Zhang, and Q. Tian. Fine-grained image search. IEEE Transactions on Multimedia, vol. 17, no. 5, pp. 636–647, 2015.
[9] X.-S. Wei, J.-H. Luo, J. Wu, and Z.-H. Zhou. Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval. IEEE Transactions on Image Processing, 2017, in press.
[10] G. E. Hinton. Learning distributed representations of concepts. In Annual Conference of the Cognitive Science Society, Amherst, MA, 1986, pp. 1–12.


由CSDN主办的中国云计算技术大会(CCTC 2017)将于5月18-19日在北京召开,Spark、Container、区块链、大数据四大主题峰会震撼袭来,包括Mesosphere CTO Tobi Knaup,Rancher labs 创始人梁胜、Databricks 工程师 Spark commiter 范文臣等近60位技术大牛齐聚京城,为云计算、大数据以及人工智能领域开发者带来一场技术的盛大Party。现在报名,只需399元就可以聆听近60场的顶级技术专家分享,还等什么,登陆官网(http://cctc.csdn.net/),赶快报名吧!
