论文笔记《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》
这篇关于Cycle-GAN的论文笔记是今年三月份所写的,由于各种原因,直到现在才整理好,稳重有说的不对的地方,请批评指正。
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
from ICCV 2017, UC Berkeley
图对图翻译是一类计算机视觉任务,其目标是利用一个经过校准的图片对数据集学到输入图片对输出图片的映射关系。实际上,对于许多任务,成对的图片数据集很难获得。该文章提出了一种从源数据域X的图片到目标数据域Y的图片的映射(翻译,translation)学习方法,其利用的数据集{X,Y}是非成对的。具体来讲,算法的目标是学习到一个映射G:X->Y,而且算法引入对抗性损失(Adversarial loss)来区分真正的Y域图像的数据分布和从X域变换而来的图像G(X)的数据分布,从而构成了生成对抗网络的基本结构。
由于这个映射非常缺乏约束条件(G:X->Y),因此增加一个反向的映射F:Y->X,并且引入循环一致性损失(Cycle Consistency Loss)以强化F(G(X))≈X,也就是要求X域的图像映射到Y域上再映射回X域之后,与原图尽可能保持一致,反之亦然,从Y域映射到X域在映射回来的Y域图像也应与原图保持一致。
文章也在不同任务上进行了量化分析,任务包括collection style transfer,目标变形(object transfiguration),季节变换,照片增强。
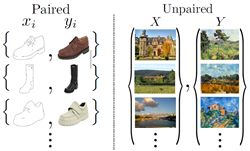
成对图片数据集和非成对图片数据集的区别
注1:Collection style transfer是指不同于神经风格变换的一种图像变换(翻译),一般是指对自然风景的图像迁移。神经风格变换(或神经风格迁移)是指使用 CNN 将一张图片的语义内容与不同风格融合起来的过程被称为神经风格迁移,例如将一张真实世界的照片转换成梵高优化风格的图像。
注2:目标变形是指对ImageNet数据集上的目标图像主要进行几何变形的图像迁移。
文章中提出的Cycle-GAN的整体结构如下图所示。

X − > Y X->Y X−>Y的生成对抗损失的具体形式如下,感觉和二分类的损失函数很像,不过判别器干的事情也就是一个二分类任务。

循环一致性损失的具体形式如下:

算法整体的损失函数定义如下。Loss包括三个部分, X − > Y X->Y X−>Y的生成对抗损失, Y − > X Y->X Y−>X的生成对抗损失,以及文章提出的循环一致性损失。 λ \lambda λ是调节循环一致性损失和生成对抗损失的权重系数。
![]()
训练阶段依照下述公式执行,一方面训练判别器 D X D_X DX和 D Y D_Y DY,使得判别器对映射图像和真实图像的判别能力不断增强,也就是 m a x D X , D Y max_{D_X,D_Y} maxDX,DY的意义;另一方面训练生成器 F , G F,G F,G,使得其对 X − > Y X->Y X−>Y的图像变换和 Y − > X Y->X Y−>X的图像变换越来越成熟,变换图像和目标域的图像越来越像,同时也要使 X − > Y − > X X->Y->X X−>Y−>X和 Y − > X − > Y Y->X->Y Y−>X−>Y过程的 l o s s loss loss越来越小,也就是 m i n G , F min_{G,F} minG,F的意义所在。
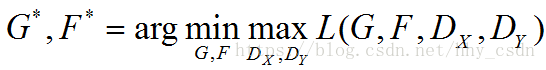
Cycle-GAN的图对图翻译效果如下。



下面的代码截取自 https://github.com/junyanz/CycleGAN.
从中可以看出生成器和判别器具体使用的卷积网络结构。
def Ck(input, k, slope=0.2, stride=2, reuse=False, norm='instance', is_training=True, name=None):
""" A 4x4 Convolution-BatchNorm-LeakyReLU layer with k filters and stride 2
def last_conv(input, reuse=False, use_sigmoid=False, name=None):
""" Last convolutional layer of discriminator network
(1 filter with size 4x4, stride 1)
Discriminator
C64 = ops.Ck(input, 64, reuse=self.reuse, norm=None,
is_training=self.is_training, name='C64') # (?, w/2, h/2, 64)
C128 = ops.Ck(C64, 128, reuse=self.reuse, norm=self.norm,
is_training=self.is_training, name='C128') # (?, w/4, h/4, 128)
C256 = ops.Ck(C128, 256, reuse=self.reuse, norm=self.norm,
is_training=self.is_training, name='C256') # (?, w/8, h/8, 256)
C512 = ops.Ck(C256, 512,reuse=self.reuse, norm=self.norm,
is_training=self.is_training, name='C512') # (?, w/16, h/16, 512)
# apply a convolution to produce a 1 dimensional output (1 channel?)
# use_sigmoid = False if use_lsgan = True
output = ops.last_conv(C512, reuse=self.reuse,
use_sigmoid=self.use_sigmoid, name='output') # (?, w/16, h/16, 1)
generator
with tf.variable_scope(self.name):
# conv layers
c7s1_32 = ops.c7s1_k(input, self.ngf, is_training=self.is_training, norm=self.norm,
reuse=self.reuse, name='c7s1_32') # (?, w, h, 32)
d64 = ops.dk(c7s1_32, 2*self.ngf, is_training=self.is_training, norm=self.norm,
reuse=self.reuse, name='d64') # (?, w/2, h/2, 64)
d128 = ops.dk(d64, 4*self.ngf, is_training=self.is_training, norm=self.norm,
reuse=self.reuse, name='d128') # (?, w/4, h/4, 128)
if self.image_size <= 128:
# use 6 residual blocks for 128x128 images
res_output = ops.n_res_blocks(d128, reuse=self.reuse, n=6) # (?, w/4, h/4, 128)
else:
# 9 blocks for higher resolution
res_output = ops.n_res_blocks(d128, reuse=self.reuse, n=9) # (?, w/4, h/4, 128)
# fractional-strided convolution
u64 = ops.uk(res_output, 2*self.ngf, is_training=self.is_training, norm=self.norm,
reuse=self.reuse, name='u64') # (?, w/2, h/2, 64)
u32 = ops.uk(u64, self.ngf, is_training=self.is_training, norm=self.norm,
reuse=self.reuse, name='u32', output_size=self.image_size) # (?, w, h, 32)
# conv layer
# Note: the paper said that ReLU and _norm were used
# but actually tanh was used and no _norm here
output = ops.c7s1_k(u32, 3, norm=None,
activation='tanh', reuse=self.reuse, name='output') # (?, w, h, 3)