Python爬虫入门教程 4-100 美空网未登录图片爬取
简介
上一篇写的时间有点长了,接下来继续把美空网的爬虫写完,这套教程中编写的爬虫在实际的工作中可能并不能给你增加多少有价值的技术点,因为它只是一套入门的教程,老鸟你自动绕过就可以了,或者带带我也行。
爬虫分析
首先,我们已经爬取到了N多的用户个人主页,我通过链接拼接获取到了
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/list.html
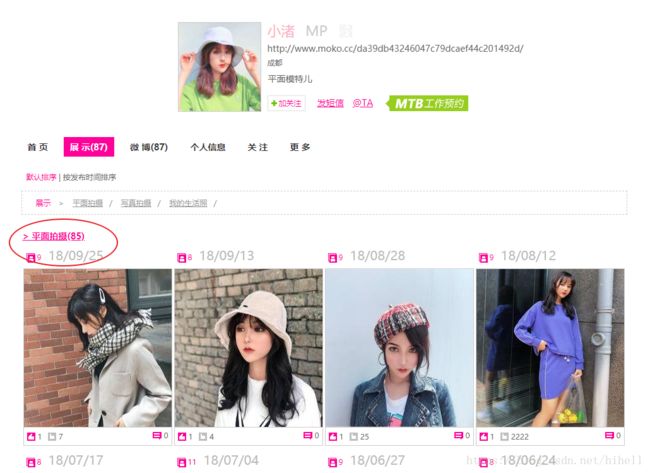
在这个页面中,咱们要找几个核心的关键点,发现平面拍摄点击进入的是图片列表页面。
接下来开始代码走起。
获取所有列表页面
我通过上篇博客已经获取到了70000(实际测试50000+)用户数据,读取到python中。
这个地方,我使用了一个比较好用的python库pandas,大家如果不熟悉,先模仿我的代码就可以了,我把注释都写完整。
import pandas as pd
# 用户图片列表页模板
user_list_url = "http://www.moko.cc/post/{}/list.html"
# 存放所有用户的列表页
user_profiles = []
def read_data():
# pandas从csv里面读取数据
df = pd.read_csv("./moko70000.csv") #文件在本文末尾可以下载
# 去掉昵称重复的数据
df = df.drop_duplicates(["nikename"])
# 按照粉丝数目进行降序
profiles = df.sort_values("follows", ascending=False)["profile"]
for i in profiles:
# 拼接链接
user_profiles.append(user_list_url.format(i))
if __name__ == '__main__':
read_data()
print(user_profiles)
数据已经拿到,接下来我们需要获取图片列表页面,找一下规律,看到重点的信息如下所示,找对位置,就是正则表达式的事情了。

快速的编写一个正则表达式
引入re,requests模块
import requests
import re
# 获取图片列表页面
def get_img_list_page():
# 固定一个地址,方便测试
test_url = "http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/list.html"
response = requests.get(test_url,headers=headers,timeout=3)
page_text = response.text
pattern = re.compile('')
# 获取page_list
page_list = pattern.findall(page_text)
运行得到结果
[('/post/da39db43246047c79dcaef44c201492d/category/304475/1.html', '85'), ('/post/da39db43246047c79dcaef44c201492d/category/304476/1.html', '2'), ('/post/da39db43246047c79dcaef44c201492d/category/304473/1.html', '0')]
继续完善代码,我们发现上面获取的数据,有"0"的产生,需要过滤掉
# 获取图片列表页面
def get_img_list_page():
# 固定一个地址,方便测试
test_url = "http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/list.html"
response = requests.get(test_url,headers=headers,timeout=3)
page_text = response.text
pattern = re.compile('')
# 获取page_list
page_list = pattern.findall(page_text)
# 过滤数据
for page in page_list:
if page[1] == '0':
page_list.remove(page)
print(page_list)
获取到列表页的入口,下面就要把所有的列表页面全部拿到了,这个地方需要点击下面的链接查看一下
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/1.html
本页面有分页,4页,每页显示数据4*7=28条
所以,基本计算公式为 math.ceil(85/28)
接下来是链接生成了,我们要把上面的链接,转换成
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/1.html
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/2.html
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/3.html
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/4.html
page_count = math.ceil(int(totle)/28)+1
for i in range(1,page_count):
# 正则表达式进行替换
pages = re.sub(r'\d+?\.html',str(i)+".html",start_page)
all_pages.append(base_url.format(pages))
当我们回去到足够多的链接之后,对于初学者,你可以先干这么一步,把这些链接存储到一个csv文件中,方便后续开发
# 获取所有的页面
def get_all_list_page(start_page,totle):
page_count = math.ceil(int(totle)/28)+1
for i in range(1,page_count):
pages = re.sub(r'\d+?\.html',str(i)+".html",start_page)
all_pages.append(base_url.format(pages))
print("已经获取到{}条数据".format(len(all_pages)))
if(len(all_pages)>1000):
pd.DataFrame(all_pages).to_csv("./pages.csv",mode="a+")
all_pages.clear()
让爬虫飞一会,我这边拿到了80000+条数据
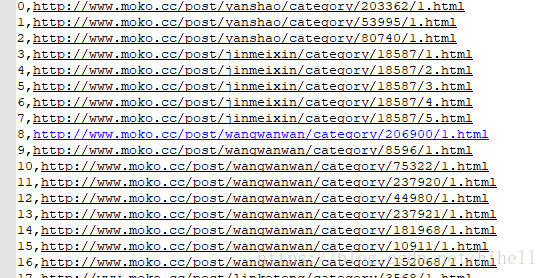
好了,列表数据有了,接下来,我们继续操作这个数据,是不是感觉速度有点慢,代码写的有点LOW,好吧,我承认这是给新手写的其实就是懒,我回头在用一篇文章把他给改成面向对象和多线程的

我们接下来基于爬取到的数据再次进行分析
例如 http://www.moko.cc/post/nimusi/category/31793/1.html 这个页面中,我们需要获取到,红色框框的地址,为什么要或者这个?因为点击这个图片之后进入里面才是完整的图片列表。
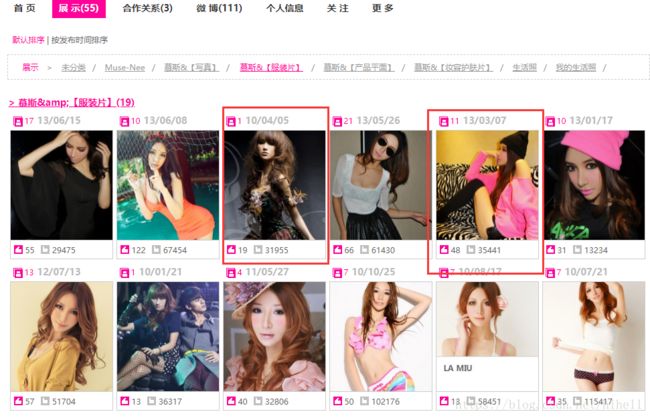
我们还是应用爬虫获取
几个步骤
- 循环我们刚才的数据列表
- 抓取网页源码
- 正则表达式匹配所有的链接
def read_list_data():
# 读取数据
img_list = pd.read_csv("./pages.csv",names=["no","url"])["url"]
# 循环操作数据
for img_list_page in img_list:
try:
response = requests.get(img_list_page,headers=headers,timeout=3)
except Exception as e:
print(e)
continue
# 正则表达式获取图片列表页面
pattern = re.compile('VIEW MORE')
img_box = pattern.findall(response.text)
need_links = [] # 待抓取的图片文件夹
for img in img_box:
need_links.append(img)
# 创建目录
file_path = "./downs/{}".format(str(img[0]).replace('/', ''))
if not os.path.exists(file_path):
os.mkdir(file_path) # 创建目录
for need in need_links:
# 获取详情页面图片链接
get_my_imgs(base_url.format(need[1]), need[0])
上面代码几个重点地方
pattern = re.compile('VIEW MORE')
img_box = pattern.findall(response.text)
need_links = [] # 待抓取的图片文件夹
for img in img_box:
need_links.append(img)
获取到抓取目录,这个地方,我匹配了两个部分,主要用于创建文件夹
创建文件夹需要用到 os 模块,记得导入一下
# 创建目录
file_path = "./downs/{}".format(str(img[0]).replace('/', ''))
if not os.path.exists(file_path):
os.mkdir(file_path) # 创建目录
获取到详情页面图片链接之后,在进行一次访问抓取所有图片链接
#获取详情页面数据
def get_my_imgs(img,title):
print(img)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
response = requests.get(img, headers=headers, timeout=3)
pattern = re.compile('![]() ')
all_imgs = pattern.findall(response.text)
for download_img in all_imgs:
downs_imgs(download_img,title)
')
all_imgs = pattern.findall(response.text)
for download_img in all_imgs:
downs_imgs(download_img,title)
最后编写一个图片下载的方法,所有的代码完成,图片保存本地的地址,用的是时间戳。
def downs_imgs(img,title):
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
response = requests.get(img,headers=headers,timeout=3)
content = response.content
file_name = str(int(time.time()))+".jpg"
file = "./downs/{}/{}".format(str(title).replace('/','').strip(),file_name)
with open(file,"wb+") as f:
f.write(content)
print("完毕")
运行代码,等着收图

代码运行一下,发现报错了

原因是路径的问题,在路径中出现了…这个特殊字符,我们需要类似上面处理/的方式处理一下。自行处理一下吧。
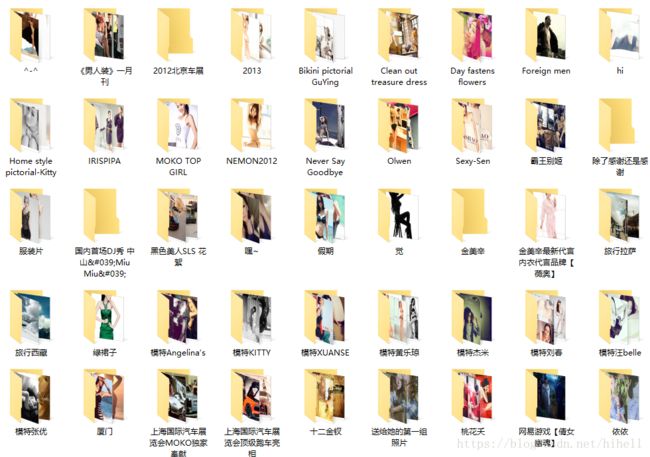
数据获取到,就是这个样子的
代码中需要完善的地方
- 代码分成了两部分,并且是面向过程的,非常不好,需要改进
- 网络请求部分重复代码过多,需要进行抽象,并且加上错误处理,目前是有可能报错的
- 代码单线程,效率不高,可以参照前两篇文章进行改进
- 没有模拟登录,最多只能爬取6个图片,这也是为什么先把数据保存下来的原因,方便后期直接改造
github代码地址与csv地址