HIVE 学习笔记之创建表和查询biao
鸣谢:
本笔记中不论测试数据还是使用方式都参考了下面几位博主的博客内容,故本文只作为个人学习记录。
https://blog.csdn.net/zimou5581/article/details/82383906
https://blog.csdn.net/u010003835/article/details/80671367
https://community.hortonworks.com/questions/68783/destination-table-is-stored-as-orc-but-the-file-be.html
背景:
小白最近开始接触hadoop生态中的hive,于是乎就开始了胡胡咧咧的hive学习史
建表:
hive 建表分为内部表(没有external)和外部表 (有external)
数据准备:
1、 通过 vi /home/hive/mytest01.txt创建数据文件,内容如下:
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong2、通过 hdfs dfs -put /home/hive/mytest01.txt /tmp/hive/ 将上述准备的数据上传到hdfs
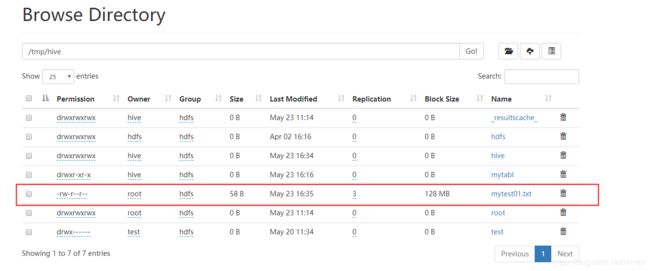
3、可以通过 hdfs dfs -cat /home/hive/mytest01.txt 来查看hdfs中的文件
建表:
1、可以通过beeline 工具来操作hive(该工具在hive1.14开始已集成)
Usage: java org.apache.hive.cli.beeline.BeeLine
-u the JDBC URL to connect to
-n the username to connect as
-p the password to connect as
-d the driver class to use
-i script file for initialization
-e query that should be executed
-f script file that should be executed
-w (or) --password-file the password file to read password from
--hiveconf property=value Use value for given property
--hivevar name=value hive variable name and value
This is Hive specific settings in which variables
can be set at session level and referenced in Hive
commands or queries.
--color=[true/false] control whether color is used for display
--showHeader=[true/false] show column names in query results
--headerInterval=ROWS; the interval between which heades are displayed
--fastConnect=[true/false] skip building table/column list for tab-completion
--autoCommit=[true/false] enable/disable automatic transaction commit
--verbose=[true/false] show verbose error messages and debug info
--showWarnings=[true/false] display connection warnings
--showNestedErrs=[true/false] display nested errors
--numberFormat=[pattern] format numbers using DecimalFormat pattern
--force=[true/false] continue running script even after errors
--maxWidth=MAXWIDTH the maximum width of the terminal
--maxColumnWidth=MAXCOLWIDTH the maximum width to use when displaying columns
--silent=[true/false] be more silent
--autosave=[true/false] automatically save preferences
--outputformat=[table/vertical/csv2/tsv2/dsv/csv/tsv] format mode for result display
Note that csv, and tsv are deprecated - use csv2, tsv2 instead
--truncateTable=[true/false] truncate table column when it exceeds length
--delimiterForDSV=DELIMITER specify the delimiter for delimiter-separated values output format (default: |)
--isolation=LEVEL set the transaction isolation level
--nullemptystring=[true/false] set to true to get historic behavior of printing null as empty string
--addlocaldriverjar=DRIVERJARNAME Add driver jar file in the beeline client side
--addlocaldrivername=DRIVERNAME Add drvier name needs to be supported in the beeline client side
--help display this message 2、采用命令 beeline -r -n hive -p hive 进入hive CUL操作界面 (鉴于记录jdbc url 地址复杂,可以直接通过 beeline 执行一次后使用该命令,可以省略记录地址的问题,因为该命令中的-r 就是使用上一次链接时的url):
建内部表:
1、 create table mytable(id int,name string,hobby array
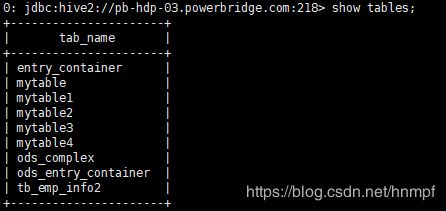
2、通过 select * from mytable;

3、通过 load data -inpath /tmp/hive/mytest01.txt OVERWRITE INTO TABLE mytable; 导入数据
4、导入成功后通过步揍2查询
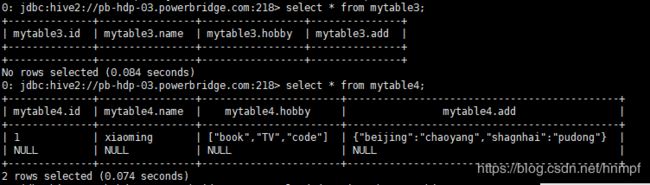
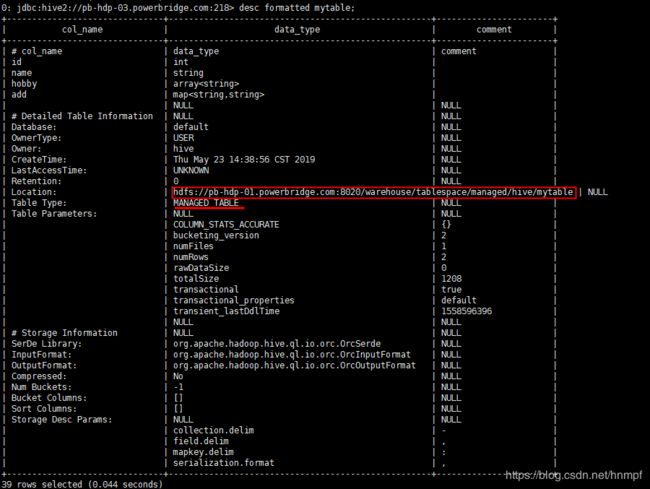
5、通过 desc formatted mytable4 ;查看明细
建外部表:
1、create external table mytable4(id int,name string,hobby array
2、通过load data inpath '/tmp/hive/mytest01.txt' OVERWRITE INTO TABLE mytable4; 导入数据.

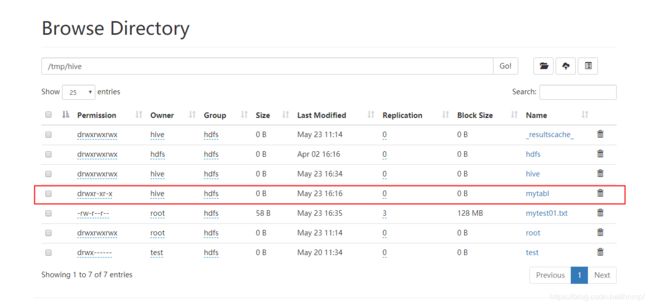
3、外部表在hdfs中的存储。
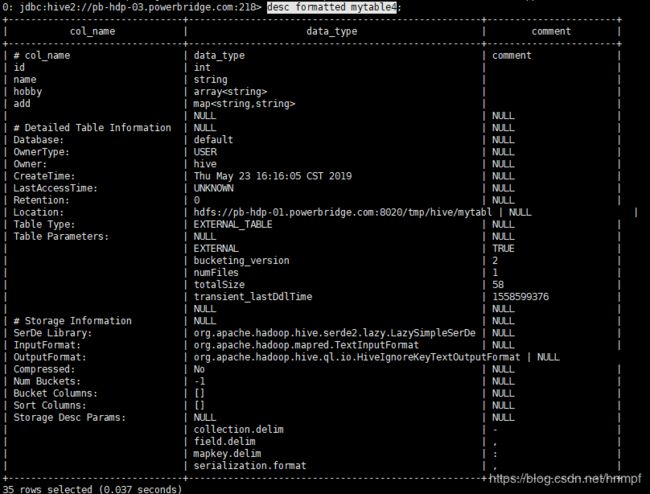
4、通过 desc 查看desc formatted mytable4;
区别:
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定;
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
比对:
1、内部表drop table mytable 后就会被彻底删除,外部表则不会。
2、通过desc formatted 表名;查看表结构信息会发现table_type 不同。
3、外部表删除后重建数据自动回复(因为没有删除HDFS上的文件)
通过查询来建表:
1、通过 AS 完成建表,
select * from mytable5;

create table mytable6 as select id,name from mytable5;

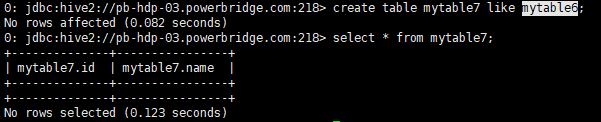
通过like来建表
会创建结构完成的空表
create table mytable7 like mytable6;
遇到的问题:
问题1:
hive sequencefile导入文件遇到FAILED: SemanticException Unable to load data to destination table. Error: The file that you are trying to load does not match the file format of the destination table
原因
这是因为SequenceFile的表不能使用load来加载数据,只能导入sequence类型的数据
解决办法
创建一张新表,
create table mytable3(id int,name string,hobby array
问题2:
执行一次load data 后再次执行会报错
原因:
执行后hdfs中的文件会被删除
解决方向:
hdfs dfs -put /home/hive/....txt /tem/hive/ 上传文件后执行即可解决。