caffe学习(六):使用python调用训练好的模型来分类(Ubuntu)
在caffe的学习过程中,我发现我需要一个模板的程序来方便我测试训练的模型。我在上一篇博客中(caffe学习(五):cifar-10数据集训练及测试(Ubuntu) ),最后测试训练好的模型时是修改caffe自带的classify.py来进行测试的,如果每次都修改未免太麻烦了,所以我就上网找了相关的资料。
参考博客:Caffe学习系列(20):用训练好的caffemodel来进行分类
下载模型
1、先去下载一个训练好的caffemodel,bvlc_reference_caffenet.caffemodel。
下载地址:http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel
大小约230M,几分钟就下好了。
这个模型是caffe的作者贾扬清及其团队训练好的,我们默认将这个文件放到
$CAFFE_ROOT/models/bvlc_reference_caffenet/下。
也可使用脚本下载,速度较慢:
cd $CAFFE_ROOT
./scripts/download_model_binary.py models/bvlc_reference_caffenet2、生成均值文件。
输入指令:
cd $CAFFE_ROOT
sh ./data/ilsvrc12/get_ilsvrc_aux.sh在测试时,程序会将数据减去均值,随后再调用训练好的模型。我们直接将这个文件下载下来。
调用脚本下载时,一并将synset_words.txt下载好了。这个文件放的是1000个类的名称。
编写python代码
我此前安装过anaconda2,使用其自带的jupyter notebook编写代码。可以看到每一步的运行结果,也可以看到报错等,调试代码十分方便。
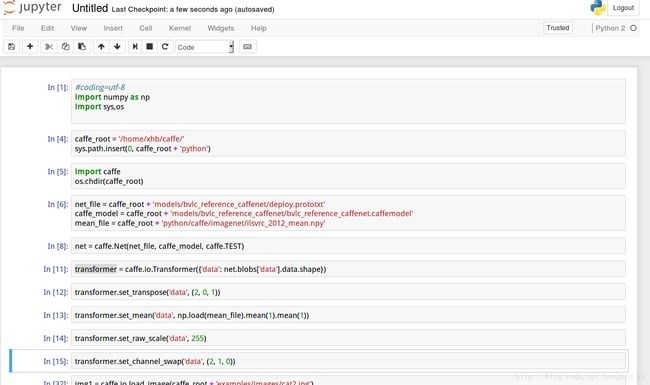
下面按照每段代码的顺序列出来:
1、引入依赖库。
#coding=utf-8
import numpy as np
import sys,os2、引入caffe的路径,caffe_root修改为自己的caffe的根目录。
caffe_root = '/home/xhb/caffe/'
sys.path.insert(0, caffe_root + 'python')3、引入caffe,将路劲切换到caffe根目录。
import caffe
os.chdir(caffe_root)4、几个用到的文件,caffe_model就是我们之前下载的模型,mean_file是均值文件,net_file是网络配置文件。
net_file = caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt'
caffe_model = caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
mean_file = caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy'5、caffe模型配置,读入模型和网络配置以及均值文件。
net = caffe.Net(net_file, caffe_model, caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2, 0, 1))
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2, 1, 0))6、读取图片,这里读取的是我自己下载的图片,路径由自己更改。
img1 = caffe.io.load_image(caffe_root + 'examples/images/cat2.jpg')7、预处理。
net.blobs['data'].data[...] = transformer.preprocess('data', img1)
8、前向传播一次,最后一层网络会输出结果。
out = net.forward()9、读取存放了标签的文件synset_words.txt。
imagenet_labels_filename = caffe_root + 'data/ilsvrc12/synset_words.txt'
labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t')10、将最后一层的结果按照概率大小排序。
op_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]11、打印预测结果,预测概率从大到小。
for i in np.arange(top_k.size):
print top_k[i], labels[top_k[i]]
到命令行下再测试几个看看:
狗

结果:(很详细啊)
208 n02099712 Labrador retriever
222 n02104029 kuvasz
257 n02111500 Great Pyrenees
179 n02093256 Staffordshire bullterrier, Staffordshire bull terrier
180 n02093428 American Staffordshire terrier, Staffordshire terrier, American pit bull terrier, pit bull terrier飞机:
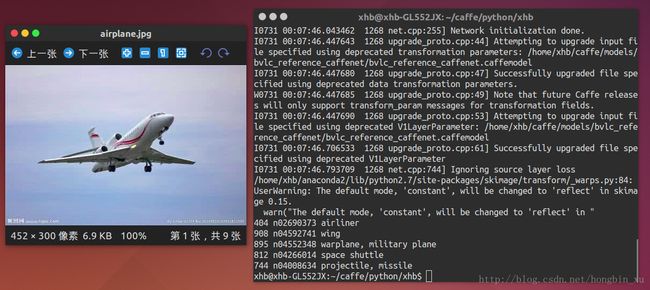
结果:
404 n02690373 airliner
908 n04592741 wing
895 n04552348 warplane, military plane
812 n04266014 space shuttle
744 n04008634 projectile, missile
笔
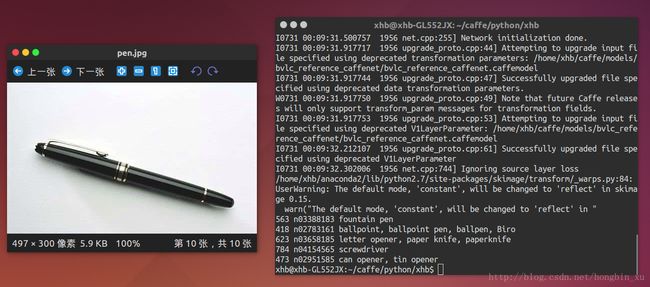
结果:
563 n03388183 fountain pen
418 n02783161 ballpoint, ballpoint pen, ballpen, Biro
623 n03658185 letter opener, paper knife, paperknife
784 n04154565 screwdriver
473 n02951585 can opener, tin opener
这套python代码可以当做一个模板来使用了,只需要稍微修改一点图片名等信息即可,方便了不少。