HBase大批量写入操作ipc queue size持续上升问题记录及修复
由于需要将关系数据库数据通过VDataHub工具导入到HBase表,虽然在VDataHub中进行了流控,但是由于集群还有其他任务在跑,导致整个集群磁盘IO几乎跑满,很多put操作没法写入,在hbase服务端可以看到很多类似以下的异常日志:
2015-06-23 13:45:18,844 WARN [RpcServer.handler=71,port=60020] ipc.RpcServer: (responseTooSlow): {"processingtimems":18758,"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","client":":54083","starttimems":1435038300085,"queuetimems":0,"class":"HRegionServer","responsesize":503,"method":"Multi"}
2015-06-23 13:45:18,844 WARN [RpcServer.handler=71,port=60020] ipc.RpcServer: RpcServer.respondercallId: 9805 service: ClientService methodName: Multi size: 119.3 K connection: :54083: output error
2015-06-23 13:45:18,845 WARN [RpcServer.handler=71,port=60020] ipc.RpcServer: RpcServer.handler=71,port=60020: caught a ClosedChannelException, this means that the server was processing a request but the client went away. The error message was: null
2015-06-23 13:45:19,080 WARN [RpcServer.handler=77,port=60020] ipc.RpcServer: (responseTooSlow): {"processingtimems":18725,"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","client":"55791","starttimems":1435038300354,"queuetimems":0,"class":"HRegionServer","responsesize":675,"method":"Multi"}
2015-06-23 13:45:19,080 WARN [RpcServer.handler=77,port=60020] ipc.RpcServer: RpcServer.respondercallId: 9354 service: ClientService methodName: Multi size: 160.1 K connection: :55791: output error
2015-06-23 13:45:19,081 WARN [RpcServer.handler=77,port=60020] ipc.RpcServer: RpcServer.handler=77,port=60020: caught a ClosedChannelException, this means that the server was processing a request but the client went away. The error message was: null 然后便是导入任务一直卡住,无法成功结束(其实就是sqoop的mapreduce任务)。但是令人费解的是,当其他任务结束了,整个集群就我们的数据导入任务的时候,通过看hbase的管理页面,看到没有几个请求,按理来说应该每秒请求数几万+的,而集群已处于空闲状态。
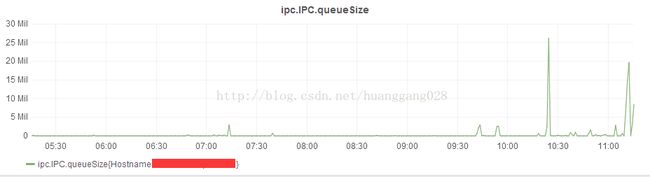
另外通过观察我们线上已经部署的metis监控图表,发现ipc queue size不太正常,按理来说,它的图示应该是有增有降, 但几乎看到的现象是持续上升,偶尔有一点降,但总体是上升的,而正常的情况是当没有请求的时候是会降回到0的。
集群资源空闲无法写入,于是没办法重启集群,然后重新跑导入任务,写入正常,非常快。过了2-3天,监控图表显示queue size从重启后的0又不断攀升, 慢慢地又写入不了。这可烦死人了,难道这以后还得定时重启,这不是笑话吗? 继续定位问题,既然资源肯定没达到限制的情况下无法写入了,肯定是hbase自身出现什么问题了,于是根据queue size的异常情况翻开hbase源码,一看还真发现了点问题,对于这个监控值,只有在CallRunner类中才存在减操作的情况,而代码里面如果一旦出现IO等异常,那个减操作的代码根本没法执行,于是出现了整个集群在负载高出现异常后,queue size会不断上升,但是又不减少。但达到一定大小后,hbase 会根据queue size大小做一个简单的流控,就引发了后面及时真实queue size没那么大,但还是采用了错误的值去做判断。
CallRunner代码片段public void run() {
try {
if (!call.connection.channel.isOpen()) {
if (RpcServer.LOG.isDebugEnabled()) {
RpcServer.LOG.debug(Thread.currentThread().getName() + ": skipped " + call);
}
return;
}
this.status.setStatus("Setting up call");
this.status.setConnection(call.connection.getHostAddress(), call.connection.getRemotePort());
if (RpcServer.LOG.isDebugEnabled()) {
UserGroupInformation remoteUser = call.connection.user;
RpcServer.LOG.debug(call.toShortString() + " executing as " +
((remoteUser == null) ? "NULL principal" : remoteUser.getUserName()));
}
Throwable errorThrowable = null;
String error = null;
Pair resultPair = null;
RpcServer.CurCall.set(call);
TraceScope traceScope = null;
try {
if (!this.rpcServer.isStarted()) {
throw new ServerNotRunningYetException("Server is not running yet");
}
if (call.tinfo != null) {
traceScope = Trace.startSpan(call.toTraceString(), call.tinfo);
}
RequestContext.set(userProvider.create(call.connection.user), RpcServer.getRemoteIp(),
call.connection.service);
// make the call
resultPair = this.rpcServer.call(call.service, call.md, call.param, call.cellScanner,
call.timestamp, this.status);
} catch (Throwable e) {
RpcServer.LOG.debug(Thread.currentThread().getName() + ": " + call.toShortString(), e);
errorThrowable = e;
error = StringUtils.stringifyException(e);
} finally {
if (traceScope != null) {
traceScope.close();
}
// Must always clear the request context to avoid leaking
// credentials between requests.
RequestContext.clear();
}
RpcServer.CurCall.set(null);
this.rpcServer.addCallSize(call.getSize() * -1);
// Set the response for undelayed calls and delayed calls with
// undelayed responses.
if (!call.isDelayed() || !call.isReturnValueDelayed()) {
Message param = resultPair != null ? resultPair.getFirst() : null;
CellScanner cells = resultPair != null ? resultPair.getSecond() : null;
call.setResponse(param, cells, errorThrowable, error);
}
call.sendResponseIfReady();
this.status.markComplete("Sent response");
this.status.pause("Waiting for a call");
} catch (OutOfMemoryError e) {
if (this.rpcServer.getErrorHandler() != null) {
if (this.rpcServer.getErrorHandler().checkOOME(e)) {
RpcServer.LOG.info(Thread.currentThread().getName() + ": exiting on OutOfMemoryError");
return;
}
} else {
// rethrow if no handler
throw e;
}
} catch (ClosedChannelException cce) {
RpcServer.LOG.warn(Thread.currentThread().getName() + ": caught a ClosedChannelException, " +
"this means that the server was processing a " +
"request but the client went away. The error message was: " +
cce.getMessage());
} catch (Exception e) {
RpcServer.LOG.warn(Thread.currentThread().getName()
+ ": caught: " + StringUtils.stringifyException(e));
}
} 既然这样,修复的办法便很明了了,不管是否异常,在最后都进行减操作,直接放到finally代码块中,google一下,发现果然有人也遇到同样的问题,在去年8月份的时候社区已经修复了,修复的版本是0.98.6,不过我们的版本是cdh 0.98.1,只能靠自己源码编译改了,坑爹呀。
http://qnalist.com/questions/5065474/ipc-queue-size
https://issues.apache.org/jira/browse/HBASE-11705
https://issues.apache.org/jira/secure/attachment/12660609/HBASE-11705.v2.patch
具体如何源码编译改的话,请参考博客里的另外一篇文章,这就不累述了。
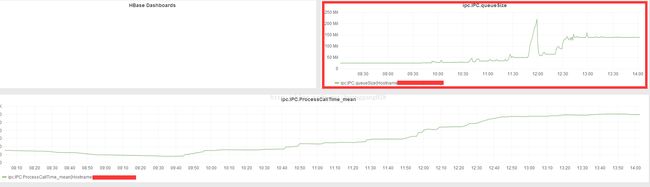
修复后图表显示表明处于正常状态了: