Java调用Tensorflow训练模型预测结果
Java调用Tensorflow训练好的模型做预测,首先需要读取词典,然后加载模型,读入数据,最后预测结果。
模型训练参考上一篇博客:使用Tensorflow训练LSTM+Attention中文标题党分类
首先需要下载一些包,如果是maven项目在pom.xml中添加两个依赖。
<dependency>
<groupId>org.tensorflowgroupId>
<artifactId>tensorflowartifactId>
<version>1.5.0version>
dependency>
<dependency>
<groupId>org.tensorflowgroupId>
<artifactId>libtensorflow_jniartifactId>
<version>1.5.0version>
dependency>
读取词典文件
这个词典文件wordIndexMap.txt,就是上一篇对应训练模型之前生成的词典文件。每行一个词和词的编号。
// 从文件读取词典文件存入Map
private static Map<String, Integer> readVocabFromFile(String pathname) throws IOException{
Map<String, Integer> wordMap = new HashMap<String, Integer>();
File filename = new File(pathname);
InputStreamReader reader = new InputStreamReader(new FileInputStream(filename));
BufferedReader br = new BufferedReader(reader);
String line = "";
line = br.readLine();
String[] lineArray;
while(line != null){
lineArray = line.split(" ");
wordMap.put(lineArray[0], Integer.parseInt(lineArray[1]));
line = br.readLine();
}
return wordMap;
}
加载Tensorflow模型文件
这里加载上一篇中训练完成保存的模型文件lstm_attention.pb。
// 读取tensorflow二进制的模型文件
private static byte[] readAllBytes(String pathname) throws IOException{
File filename = new File(pathname);
BufferedInputStream in = new BufferedInputStream(new FileInputStream(filename));
ByteArrayOutputStream out = new ByteArrayOutputStream(1024);
byte[] temp = new byte[1024];
int size = 0;
while((size = in.read(temp)) != -1){
out.write(temp, 0, size);
}
in.close();
byte[] content = out.toByteArray();
return content;
}
读取预测数据
预测可以是一条数据,也可以是一个batch的数据。
// 读取分词后的一个样本,并建立索引
public static int[][] getInputFromSentence(String sentence, Map<String, Integer> wordIndexMap) {
int[][] indexArray = new int[1][MAX_SEQUENCE_LENGTH];
String[] words = sentence.split(" ");
for(int i=0; i<words.length; i++){
if(wordIndexMap.containsKey(words[i])){
indexArray[0][i] = wordIndexMap.get(words[i]);
}
}
return indexArray;
}
// 对一个batch的样本建立索引
public static int[][] getInputFromSentenceBatch(String[] sentences, Map<String, Integer> wordIndexMap){
int[][] indexArray = new int[sentences.length][MAX_SEQUENCE_LENGTH];
for(int i=0; i<sentences.length; i++){
String[] words = sentences[i].split(" ");
for(int j=0; j<words.length; j++){
if(wordIndexMap.containsKey(words[j])){
indexArray[i][j] = wordIndexMap.get(words[j]);
}
}
}
return indexArray;
}
预测结果
需要新建Tensorflow的Session会话,读取训练好的模型计算图和参数,
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import org.tensorflow.Graph;
import org.tensorflow.Session;
import org.tensorflow.Tensor;
public class TensorflowDemo {
private static String TensorFlow_MODEL_PATH = "lstm_attention.pb";
private static String WORD_INDEX_PATH = "wordIndexMap.txt";
private static int MAX_SEQUENCE_LENGTH = 60;
private static int CLASS_NUM = 2;
public static void main(String[] args) throws IOException{
// 构建词典Map
Map<String, Integer> wordsMap = readVocabFromFile(WORD_INDEX_PATH);
System.out.println("vocabulary size:"+wordsMap.size());
// 加载Tensorflow训练好的模型
byte[] graphDef = readAllBytes(TensorFlow_MODEL_PATH);
Graph graph = new Graph();
graph.importGraphDef(graphDef);
Session session = new Session(graph);
String test_sentence = "再也 不用 愁 看不起 病 了 , 老祖宗 留下 此表 !";
System.out.println("sentence: "+test_sentence);
// 输入模型的测试语句
int[][] sentenceBuf = getInputFromSentence(test_sentence, wordsMap);
int[] sentLength = {sentenceBuf[0].length};
Tensor inputTensor = Tensor.create(sentenceBuf);
Tensor lengthTensor = Tensor.create(sentLength);
// 输入数据,得到预测结果
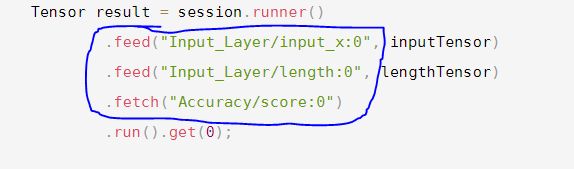
Tensor result = session.runner()
.feed("Input_Layer/input_x:0", inputTensor)
.feed("Input_Layer/length:0", lengthTensor)
.fetch("Accuracy/score:0")
.run().get(0);
long[] rshape = result.shape();
int batchSize = (int) rshape[0];
// int nlabels = (int) rshape[1];
float[][] resultArray = new float[batchSize][CLASS_NUM];
result.copyTo(resultArray); // 输出结果Tensor复制到二维数组中
System.out.println(resultArray[0][0]+" "+resultArray[0][1]);
}
注意预测结果时同样要保持模型输入输出格式名称一致。预测的输入输出要与模型最初构建时保持一致。
模型构建时是下面这种写法:


java预测时是这种写法:
由于代码是一块一块分开的,感觉整体不是很连贯,后面会完善。