基于oracle数据库与gephi的疾病相关性分析
关键字
Gephi SQL 相关性分析
概要
因业务需要,最近在研究如何进行疾病数据的相关性分析,这方面网上大多是基于python实现的,很少有直接基于关系型数据库(本例基于oracle,其他关系型数据库类似)的分析。
本文演示如何使用gephi对数据库中的疾病信息进行相关性分析。
约定:
1、如果一次就诊过程中含有2种及以上疾病,说明疾病之间具有相关性;
2、节点(nodes):疾病名称表示节点名称(label),疾病出现次数为权重(size);
3、边(edges):如果一次就诊含有2种疾病(疾病a1,疾病a2),则存在唯一一条边(需要按疾病名称排序):
source:疾病a1
target:疾病a2
weight:权重:1
4、关于边的权重计算:如果一次就诊中含有n种疾病,则边的数量计算公式为:(n*n-n)/2;
创建演示表
-- 创建演示表
create table test_desease(
id int, /*主键*/
jzxh int, /*就诊序号*/
jbmc varchar(20), /*疾病名称:一次就诊可以包含多个疾病*/
constraint pk_test_desease primary key(id)
);
-- 写入示例数据
insert into test_desease
select 1 as id, 1 jzxh, '高血压' as jbmc from dual union all
select 2 as id, 1 jzxh, '糖尿病' as jbmc from dual union all
select 3 as id, 2 jzxh, '高血压' as jbmc from dual union all
select 4 as id, 2 jzxh, '冠心病' as jbmc from dual union all
select 5 as id, 2 jzxh, '感冒' as jbmc from dual union all
select 6 as id, 3 jzxh, '高血压' as jbmc from dual union all
select 7 as id, 3 jzxh, '糖尿病' as jbmc from dual union all
select 8 as id, 3 jzxh, '脑卒中' as jbmc from dual
;
commit;
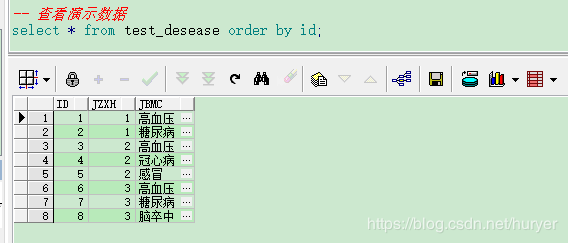
-- 查看演示数据
select * from test_desease order by id;
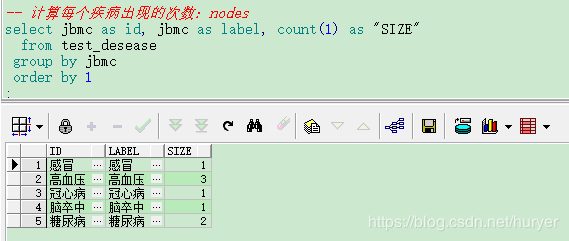
计算节点nodes
-- 计算每个疾病出现的次数:nodes
select jbmc as id, jbmc as label, count(1) as "SIZE"
from test_desease
group by jbmc
order by 1;
查询后,将数据导出到:演示-nodes.xlsx
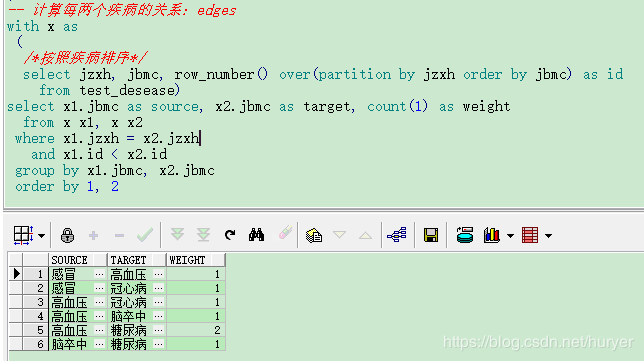
计算边edges
-- 计算每两个疾病的关系:edges
with x as
(
/*按照疾病排序*/
select jzxh, jbmc, row_number() over(partition by jzxh order by jbmc) as id
from test_desease)
select x1.jbmc as source, x2.jbmc as target, count(1) as weight
from x x1, x x2
where x1.jzxh = x2.jzxh
and x1.id < x2.id
group by x1.jbmc, x2.jbmc
order by 1, 2
查询后,将数据导出到:演示-edges.xlsx
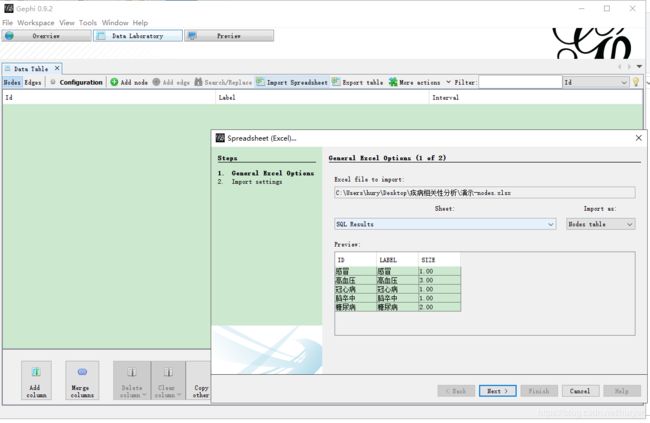
新建gephi工程
打开gephi,新建一个空白工程
导入节点nodes
切换到Data Laboratory页签,点击导入表格(Import Spreadsheet)
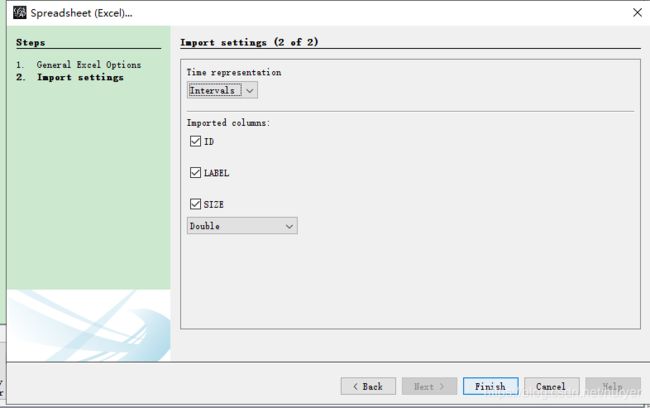
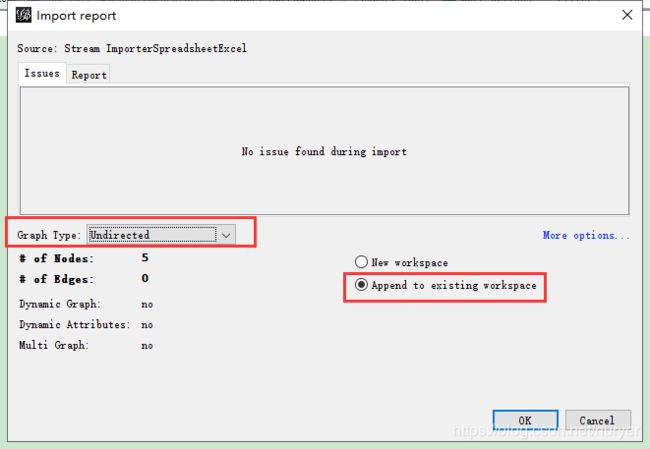
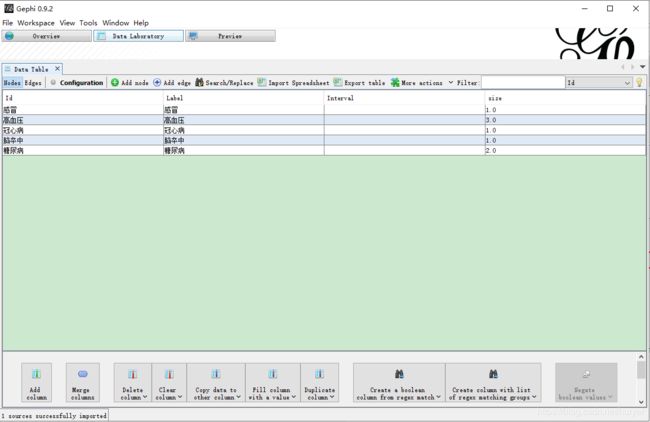
导入边edges
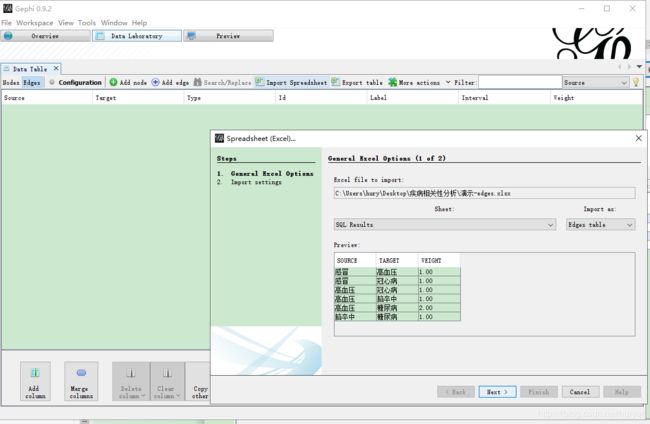
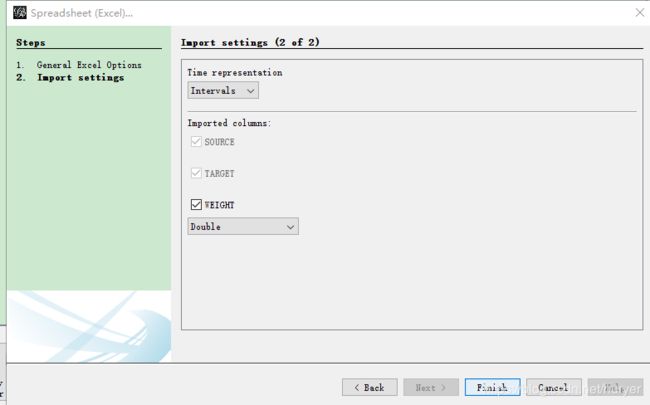
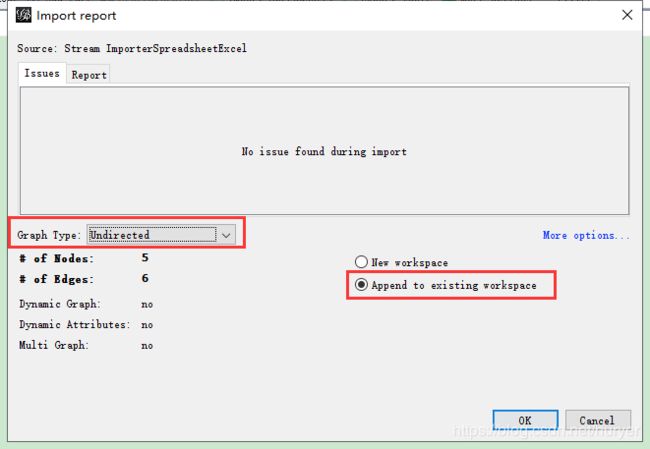
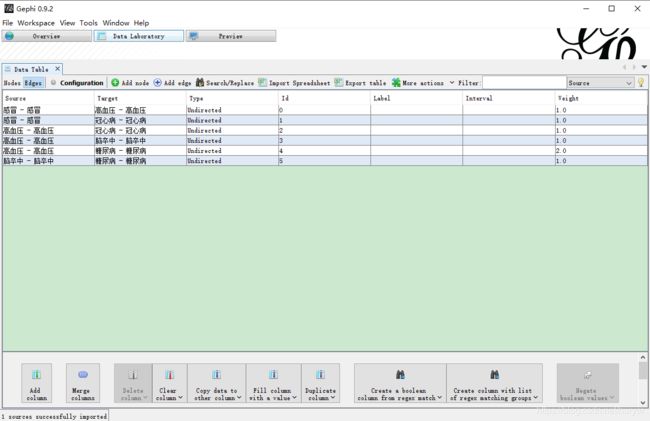
调整样式
切换到Overview页签,默认样式如下,看上去非常简陋,所以需要进行样式调整:
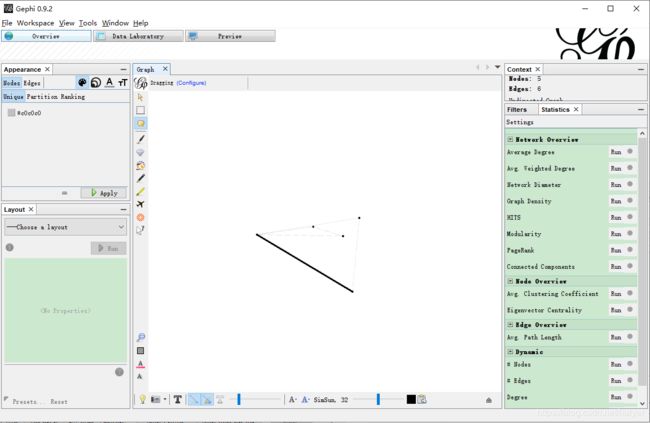
节点调整内容如下:
1、显示节点字体
2、Appearance:
调色板(Color)–》Partition,按照size调整;
节点大小(Size)–》Ranking,按照size调整,最小:20,最大:60;
3、布局(Layout):Fruchterman Reingold;
调整后的效果如下:
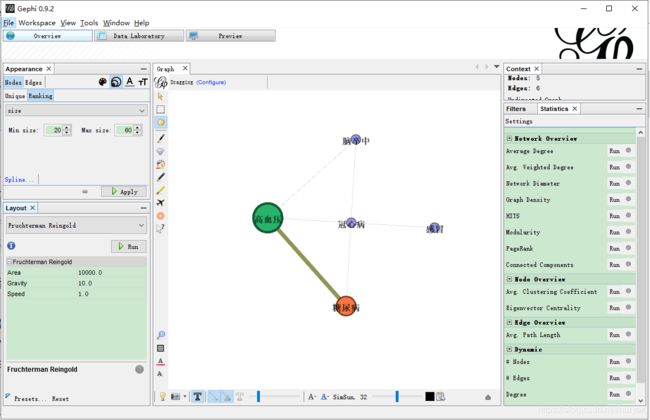
真实数据
最后来一张真实数据的效果图:
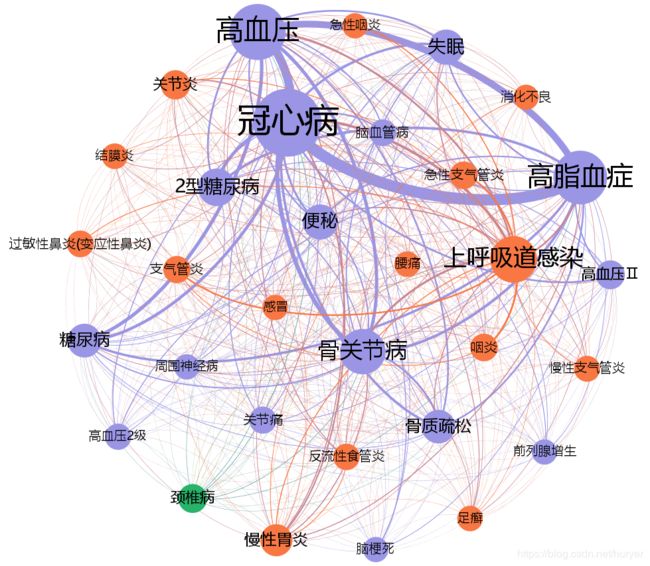
好吧,纯技术层面也就这样了,剩下的需要从业务层面入手了,感觉不了解业务很容易遇到天花板哪,哈哈。
参考
https://www.jianshu.com/p/86145943695a
–END–