Java 日志框架解析:设计模式、性能
- Java 日志框架解析设计模式性能
- Java 的日志框架
- 设计模式
- 门面模式
- 适配器模式
- slf4j API 和具体实现的绑定
- 异步日志输出的原理
- logback
- 同步的 RollingFileAppender
- 异步的 AsyncAppender
- 总结
- log4j2
- Disruptor
- 总结
- logback
- 参考文献
Java 日志框架解析:设计模式、性能
在平常的系统开发中,日志起到了重要的作用,日志写得好对于线上问题追踪有着很大的帮助。一个好的日志框架,既要方便易用,也要有较好的性能,减少日志输出对系统内存、CPU 的影响。
研究一款开源项目,学到的不仅仅是这个项目本身,还会学到很多设计思想,可以利用到日常工作中。这里我们主要讨论 & 描述三个问题:
- Java 日志框架有哪些组件?各自都是什么角色?
- Java 日志框架用到了哪些设计模式?
- 日志门面和具体实现是如何绑定的?
- 日志组件中异步输出的原理是什么?如果提升性能的?
Java 的日志框架
比较常见的日志组件有 slf4j、commons-logging、log4j、logback,它们之间是什么样的关系呢?大致可以分为 4类:
1. 日志门面:commons-logging-api 和 slf4j 提供了一套通用的接口,具体的实现可以由开发者自由选择。
2. 具体实现:log4j、logback、log4j2 等都是 slf4j 的具体实现,不需修改代码,通过简单的修改配置即可实现切换,十分方便。
3. 旧日志到 slf4j 的适配器:一些系统之前采用的是老的日志组件,其 API 和 slf4j 不太一样,那么如果想要切换成 slf4j + 具体实现的模式,可以使用一些适配器来嫁接到 sl4fj 上,比如 log4j-over-slf4j 可以用于替换 log4j。
4. slf4j 到旧实现的适配器:有些日志组件的出现早于 slf4j,其 API 和 slf4j 不一样,如果想要在代码中使用 slf4j 做 API,而实现才有这些老日志组件,那么就需要一个 slf4j 到旧实现的适配器,比如 slf4j-log4j12。

设计模式
门面模式
门面模式,是面向对象设计模中的结构模式,又称为外观模式。外部与一个子系统的通信必须通过一个统一的外观对象进行,为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
使用门面模式的好处是,接口和实现分离,屏蔽了底层的实现细节。
当你使用 slf4j 作为系统的日志门面时,底层具体实现可以使用 log4j、logback、log4j2 中的任意一个。
适配器模式
将一个类的接口转换成客户希望的另外一个接口,Adapter 模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
通常要组合两个不相干的类有两种方法,一种是修改各自的接口,如果不愿意(接口是别人的,他们不想改)或不方便(接口是公共 API,调用方很多,不方便单独给你改)修改,那就需要使用 Adapter 适配器,在两个接口之间做一个适配层。
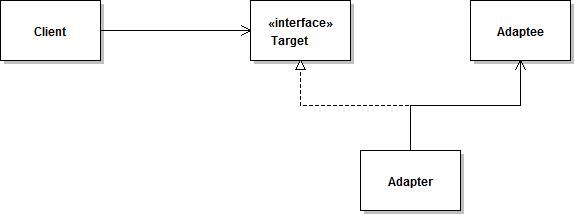
上图所示是适配器模式的类图。Adapter 适配器设计模式中有 3 个重要角色:被适配者 Adaptee,适配器 Adapter 和目标对象 Target。想要把 Client/Target 和 Adaptee 组合到一起,而它们接口又不适配时,就可以通过创建一个适配器 Adapter 将它们组合在一起。
比如想要将 slf4j 和 log4j 组合在一起,然而它们之间接口又不一致,就使用 slf4j-log4j12 来做适配器达到目的。适配器的存在,避免了对已有组件的修改。
slf4j API 和具体实现的绑定
在实际使用,一般只是在 pom.xml 文件中引入各种日志 jar 包,然后在 resources 文件夹下放一个日志配置 logback.xml 或 log4j.properties 即可,并没有显式的对 API 和其实现进行绑定。那么 slf4j API 是如何与不同实现进行绑定的呢?下面我们深入源码研究一下。
private static final Logger log = LoggerFactory.getLogger("MyLoggerName");一般在打日志的时候会调用 slf4j 的 LoggerFactory 创建一个 Logger,我们看看 LoggerFactory 的源码:
public final class LoggerFactory {
public static Logger getLogger(String name) {
ILoggerFactory iLoggerFactory = getILoggerFactory();
return iLoggerFactory.getLogger(name);
}
} getLogger 方法调用 getILoggerFactory 来获取工厂类,getILoggerFactory 源码如下所示,主要调用了 performInitialization 方法进行初始化:
public final class LoggerFactory {
public static ILoggerFactory getILoggerFactory() {
if (INITIALIZATION_STATE == UNINITIALIZED) {
INITIALIZATION_STATE = ONGOING_INITIALIZATION;
// 如果尚未初始化,则执行初始化操作
performInitialization();
}
switch (INITIALIZATION_STATE) {
case SUCCESSFUL_INITIALIZATION:
return StaticLoggerBinder.getSingleton().getLoggerFactory();
case NOP_FALLBACK_INITIALIZATION:
return NOP_FALLBACK_FACTORY;
case FAILED_INITIALIZATION:
throw new IllegalStateException(UNSUCCESSFUL_INIT_MSG);
case ONGOING_INITIALIZATION:
// support re-entrant behavior.
// See also http://bugzilla.slf4j.org/show_bug.cgi?id=106
return TEMP_FACTORY;
}
throw new IllegalStateException("Unreachable code");
}
private final static void performInitialization() {
// 绑定日志实现
bind();
if (INITIALIZATION_STATE == SUCCESSFUL_INITIALIZATION) {
versionSanityCheck();
}
}
} performInitialization 方法进一步调用链 bind 方法,源码如下:
private final static void bind() {
try {
Set staticLoggerBinderPathSet = findPossibleStaticLoggerBinderPathSet();
// 如果存在多个日志实现,则使用 System.err 输出一些日志来提醒用户
reportMultipleBindingAmbiguity(staticLoggerBinderPathSet);
// the next line does the binding
StaticLoggerBinder.getSingleton();
INITIALIZATION_STATE = SUCCESSFUL_INITIALIZATION;
reportActualBinding(staticLoggerBinderPathSet);
fixSubstitutedLoggers();
} catch (Exception e) {
// 省略异常处理代码
}
} bind 方法首先调用了 findPossibleStaticLoggerBinderPathSet 方法来找到所有的 slf4j 实现:
private static Set findPossibleStaticLoggerBinderPathSet() {
// use Set instead of list in order to deal with bug #138
// LinkedHashSet appropriate here because it preserves insertion order during iteration
Set staticLoggerBinderPathSet = new LinkedHashSet();
try {
ClassLoader loggerFactoryClassLoader = LoggerFactory.class.getClassLoader();
Enumeration paths;
if (loggerFactoryClassLoader == null) {
paths = ClassLoader.getSystemResources(STATIC_LOGGER_BINDER_PATH);
} else {
paths = loggerFactoryClassLoader.getResources(STATIC_LOGGER_BINDER_PATH);
}
while (paths.hasMoreElements()) {
URL path = (URL) paths.nextElement();
staticLoggerBinderPathSet.add(path);
}
} catch (IOException ioe) {
Util.report("Error getting resources from path", ioe);
}
return staticLoggerBinderPathSet;
} findPossibleStaticLoggerBinderPathSet 会使用 ClassLoader 来找到 org/slf4j/impl/StaticLoggerBinder.class 的资源路径,所有支持 slf4j-api 的日志实现类都会有这个类,比如下图中的 logback 和 slf4j-log4j12 都有这个类:
StaticLoggerBinder 主要实现了 LoggerFactoryBinder 接口
package org.slf4j.spi;
import org.slf4j.ILoggerFactory;
public interface LoggerFactoryBinder {
ILoggerFactory getLoggerFactory();
String getLoggerFactoryClassStr();
}总结一下,一个日志实现想要能够和 slf4j-api 成功绑定,需要实现 org/slf4j/impl/StaticLoggerBinder 类,而且该类需要实现 LoggerFactoryBinder 接口。
异步日志输出的原理
异步记录日志,将耗时的 IO 操作放到了单独的线程中,既可以提升性能,也可以加快程序主流程的处理速度。下面我们分别从源码角度来解析一下 logback 和 log4j2 的异步实现原理。
logback
在 logback 配置文件里,一般通过配置 appender 来指定日志输出级别、格式、滚动策略等等。最常用的是输出日志到文件的 RollingFileAppender 和用于异步输出日志的 AsyncAppender。
<appender name="fileAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>${catalina.base}/logs/default.logFile>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${catalina.base}/logs/default.%d{yyyy-MM-dd-HH}.logfileNamePattern>
<maxHistory>30maxHistory>
rollingPolicy>
<encoder charset="UTF-8">
<pattern>${normalPattern}pattern>
<immediateFlush>falseimmediateFlush>
encoder>
appender>
<appender name="asyncFileAppender" class= "ch.qos.logback.classic.AsyncAppender">
<discardingThreshold >0discardingThreshold>
<queueSize>512queueSize>
<appender-ref ref ="fileAppender"/>
appender>RollingFileAppender 和 AsyncAppender 都是类 UnsynchronizedAppenderBase 的子类,而 UnsynchronizedAppenderBase 实现了接口 Appender,doAppend 方法主要调用了抽象方法 append 来追加日志。
public interface Appender<E> extends LifeCycle, ContextAware, FilterAttachable<E> {
// 追加日志
void doAppend(E event) throws LogbackException;
}
abstract public class UnsynchronizedAppenderBase<E> extends ContextAwareBase implements
Appender<E> {
public void doAppend(E eventObject) {
// 省略不重要代码
this.append(eventObject);
}
abstract protected void append(E eventObject);
} 同步的 RollingFileAppender
RollingFileAppender 继承关系:RollingFileAppender -> FileAppender -> OutputStreamAppender -> UnsynchronizedAppenderBase,OutputStreamAppender 中的 append 方法调用了 subAppend 方法,subAppend 又调用了 writeOut 方法,writeOut 又调用了 LayoutWrappingEncoder 的 doEncode 方法,在 doEncode 方法中调用了 outputStream 的 write 方法,并且判断 immediateFlush 为 true 的话,则立即 flush。
public class RollingFileAppender<E> extends FileAppender<E> { }
public class FileAppender<E> extends OutputStreamAppender<E> { }
public class OutputStreamAppender<E> extends UnsynchronizedAppenderBase<E> {
@Override
protected void append(E eventObject) {
if (!isStarted()) {
return;
}
subAppend(eventObject);
}
protected void subAppend(E event) {
// 省略其他不重要的代码
lock.lock();
try {
writeOut(event);
} finally {
lock.unlock();
}
}
protected void writeOut(E event) throws IOException {
// setLayout 方法中设置了 encoder = new LayoutWrappingEncoder();
this.encoder.doEncode(event);
}
}
public class LayoutWrappingEncoder<E> extends EncoderBase<E> {
public void doEncode(E event) throws IOException {
String txt = layout.doLayout(event);
outputStream.write(convertToBytes(txt));
if (immediateFlush)
outputStream.flush();
}
} 我们再看代码追查一下 outputStream 的真实类型,FileAppender 是直接将日志输出到文件中,初始化了一个 ResilientFileOutputStream,其内部使用的是带缓冲的 BufferedOutputStream,然后调用超类的 setOutputStream 方法设置输出流,最终调用 encoder.init 方法将输出流对象赋值给了 outputStream。
public class FileAppender<E> extends OutputStreamAppender<E> {
public void openFile(String file_name) throws IOException {
LogbackLock var2 = this.lock;
synchronized(this.lock) {
File file = new File(file_name);
// 如果日志文件所在的文件夹还不存在,就创建之
if(FileUtil.isParentDirectoryCreationRequired(file)) {
boolean resilientFos = FileUtil.createMissingParentDirectories(file);
if(!resilientFos) {
this.addError("Failed to create parent directories for [" + file.getAbsolutePath() + "]");
}
}
ResilientFileOutputStream resilientFos1 = new ResilientFileOutputStream(file, this.append);
resilientFos1.setContext(this.context);
// 调用父类的 setOutputStream 方法
this.setOutputStream(resilientFos1);
}
}
}
public class ResilientFileOutputStream extends ResilientOutputStreamBase {
private File file;
private FileOutputStream fos;
public ResilientFileOutputStream(File file, boolean append) throws FileNotFoundException {
this.file = file;
this.fos = new FileOutputStream(file, append);
// OutputStream os 在超类 ResilientOutputStreamBase 里
this.os = new BufferedOutputStream(this.fos);
this.presumedClean = true;
}
}
public class OutputStreamAppender<E> extends UnsynchronizedAppenderBase<E> {
private OutputStream outputStream;
protected Encoder encoder;
public void setOutputStream(OutputStream outputStream) {
lock.lock();
try {
// close any previously opened output stream
closeOutputStream();
encoderInit();
} finally {
lock.unlock();
}
}
// 将 outputStream 送入 encoder
void encoderInit() {
encoder.init(outputStream);
}
} 异步的 AsyncAppender
AsyncAppender 的继承关系是:AsyncAppender -> AsyncAppenderBase -> UnsynchronizedAppenderBase,AsyncAppenderBase 中 append 方法实现如下:
public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
BlockingQueue blockingQueue = new ArrayBlockingQueue(queueSize);
@Override
protected void append(E eventObject) {
// 如果队列满,并且允许丢弃,则直接 return
if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) {
return;
}
preprocess(eventObject);
put(eventObject);
}
private void put(E eventObject) {
try {
blockingQueue.put(eventObject);
} catch (InterruptedException e) {
}
}
} 看代码可知,append 方法是把日志对象放到了阻塞队列 ArrayBlockingQueue 中。那么何时把队列中的数据存入日志文件呢?AsyncAppenderBase 中有一个 Worker 对象,负责从队列中取数据并调用 AppenderAttachableImpl 来处理:(这里一次只取一个进行追加的方式,效率有点低啊)
public void run() {
AsyncAppenderBase parent = AsyncAppenderBase.this;
AppenderAttachableImpl aai = parent.aai;
// loop while the parent is started
while (parent.isStarted()) {
try {
E e = parent.blockingQueue.take();
aai.appendLoopOnAppenders(e);
} catch (InterruptedException ie) {
break;
}
}
addInfo("Worker thread will flush remaining events before exiting. ");
for (E e : parent.blockingQueue) {
aai.appendLoopOnAppenders(e);
}
aai.detachAndStopAllAppenders();
}
} 这里的 AppenderAttachableImpl 也就是 logback.xml 里配置的 appender-ref 对象:
<appender name="asyncFileAppender" class="ch.qos.logback.classic.AsyncAppender">
<discardingThreshold >0discardingThreshold>
<queueSize>10000queueSize>
<appender-ref ref="fileAppender" />
appender>总结
RollingFileAppender 底层写文件使用的是 BufferedOutputStream。AsyncAppender 使用了 ArrayBlockingQueue 作缓冲,并且会用任务不停地从队列取数据放入底层 Appender(通常就是另一个 RollingFileAppender了),ArrayBlockingQueue 队列大小可以自由设置,但是从队列中取数据的任务是一个个的取并追加到下一个 Appender 的,性能提升不多。
log4j2
Disruptor

在 log4j2 中,同样是使用 Appender 将日志输出到文件、屏幕或网络中,查看代码后发现 AsyncAppender 和 logback 中的原理类似。log4j2 官方文档:异步中说“log4j2 的日志吞吐量如何能够比其他框架多出了 12 倍”,那么 log4j2 的性能好在哪里呢?

深究以后我们发现,log4j2 对性能改进是在 Logger 端,从上图也可以看出来 log4j2 中的 AsyncAppender 性能和 logback 的 AsyncAppender 差不多,但是 AsyncLogger 性能远远优于 AsyncAppender。为啥呢?在 AsyncLogger 类中,使用了 Disruptor 框架来缓存和处理日志。Disruptor 是一个高性能的并发框架,其底层数据结构是环形缓冲区 RingBuffer。
class AsyncLoggerDisruptor {
private volatile Disruptor disruptor;
}
public class AsyncLogger extends Logger implements EventTranslatorVararg<RingBufferLogEvent> {
private final AsyncLoggerDisruptor loggerDisruptor;
// Logger.info/debut 等方法会调用 logMessage
public void logMessage(String fqcn, Level level, Marker marker, Message message, Throwable thrown) {
// 当前线程是 Appender 线程,并且 RingBuffer 满时,才由当前线程来处理日志,否则放入 RingBuffer
if(this.loggerDisruptor.shouldLogInCurrentThread()) {
this.logMessageInCurrentThread(fqcn, level, marker, message, thrown);
} else {
this.logMessageInBackgroundThread(fqcn, level, marker, message, thrown);
}
}
private void logInBackground(String fqcn, Level level, Marker marker, Message message, Throwable thrown) {
if(this.loggerDisruptor.isUseThreadLocals()) {
this.logWithThreadLocalTranslator(fqcn, level, marker, message, thrown);
} else {
this.logWithVarargTranslator(fqcn, level, marker, message, thrown);
}
}
private void logWithThreadLocalTranslator(String fqcn, Level level, Marker marker, Message message, Throwable thrown) {
RingBufferLogEventTranslator translator = this.getCachedTranslator();
this.initTranslator(translator, fqcn, level, marker, message, thrown);
// 这个方法最终也是调用了 ringBuffer.publishEvent
this.loggerDisruptor.enqueueLogMessageInfo(translator);
}
private void logWithVarargTranslator(String fqcn, Level level, Marker marker, Message message, Throwable thrown) {
Disruptor disruptor = this.loggerDisruptor.getDisruptor();
if(disruptor == null) {
LOGGER.error("Ignoring log event after Log4j has been shut down.");
} else {
// 把数据放入 RingBuffer 中
disruptor.getRingBuffer().publishEvent(this, new Object[]{this, this.calcLocationIfRequested(fqcn), fqcn, level, marker, message, thrown});
}
}
} Disruptor & RingBuffer 性能好在哪里呢?ArrayBlockingQueue 在添加数据时使用了锁来确保线程安全,Disruptor 中的 RingBuffer 的添加数据分为两步:申请数据位、提交数据。在申请数据位时,使用 CAS 确保线程安全,效率较高:
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E> {
public void publishEvent(EventTranslator translator) {
long sequence = this.sequencer.next();
this.translateAndPublish(translator, sequence);
}
}
public final class MultiProducerSequencer extends AbstractSequencer {
// 申请数据位
public long next() {
return this.next(1);
}
public long next(int n) {
if(n < 1) {
throw new IllegalArgumentException("n must be > 0");
} else {
long current;
long next;
do {
while(true) {
current = this.cursor.get();
next = current + (long)n;
long wrapPoint = next - (long)this.bufferSize;
long cachedGatingSequence = this.gatingSequenceCache.get();
if(wrapPoint <= cachedGatingSequence && cachedGatingSequence <= current) {
break;
}
long gatingSequence = Util.getMinimumSequence(this.gatingSequences, current);
if(wrapPoint > gatingSequence) {
// 队列满时,让出 CPU
LockSupport.parkNanos(1L);
} else {
this.gatingSequenceCache.set(gatingSequence);
}
}
// CAS 自旋申请数据位
} while(!this.cursor.compareAndSet(current, next));
return next;
}
}
} 当然了,Disruptor 高性能的原因还有别的改进(伪共享 & 缓存行填充),更多内容可以看并发框架 Disruptor 译文。
总结
log4j2 对性能的提升,主要是采用了 Disruptor 这一个高性能的并发框架。
参考文献
- Java 日志性能那点事儿
- Java 日志体系(logback)
- Java日志框架(Commons-logging, SLF4j, Log4j, Logback)
- 设计模式(七)门面模式(Facade Pattern 外观模式)
- 适配器模式原理及实例介绍
- 适配器模式
- 从源码来理解slf4j的绑定,以及logback对配置文件的加载
- logback 源码解析
- Log4j2分析与实践-架构
- log4j2 官方文档:异步
- log4j2 性能剖析
- 并发框架Disruptor译文
- log4j2 官方文档:架构
- logback 官方文档:Appender