Flink提交任务(总篇)——执行逻辑整体分析
Flink客户端提交任务执行的逻辑分析
针对Flink1.7-release版本
前言
Flink的源码体系比较庞大,一头扎进去,很容易一头雾水,不知道从哪部分代码看起。但是如果结合我们的业务开发,有针对性地去跟进源码去发现问题,理解源码里的执行细节,效果会更好。
笔者在近期的Flink开发过程中,因为产品的原因,只允许部署Flink standalone模式,出于性能考虑,很有必要对其性能做下测试。
Flink的standalone模式的部署方式很简单。只需要设定下基本的全局配置参数就行。比如jobmanager.heap.size, taskmanager.heap.size, parallelism.default, taskmanager.numberOfTaskSlots等这些常用参数,就可以执行./bin/start-cluster.sh来启动Flink的standalone模式。
但是当我执行:
./bin/flink run -c chx.demo.FirstDemo /demo/chx.jar
来提交我的任务时,发现问题了。当批处理的数据量达2000W时,一切还挺正常,但是当批处理的数据量达3800W时,报出了异常:
Caused by: akka.pattern.AskTimeoutException: Ask timed out on
>>>> [Actor[akka://flink/user/$a#183984057]] after [10000ms]
碰到这种报错,首先Akka的机制我们是有必要熟悉下的,但是本文不重点讲解Akka的原理和用法,不过我后续文章想对akka做具体的分析和总结。
本文重点讲述我们通过./bin/flink run提交任务时,程序到底做了什么事情。对背后代码的执行逻辑做一番分析。
1. 整体逻辑
Flink通过客户端提交任务的入口在:org.apache.flink.client.cli$CliFrontend。其入口函数main的逻辑如下:
public static void main(final String[] args) {
// 1. 打印基本的环境信息
EnvironmentInformation.logEnvironmentInfo(LOG, "Command Line Client", args);
// 2. 获取配置目录。一般是flink安装目录下的/conf目录
final String configurationDirectory = getConfigurationDirectoryFromEnv();
// 3. 加载全局配置(加载配置yaml文件,将其解析出来)
final Configuration configuration = GlobalConfiguration.loadConfiguration(configurationDirectory);
// 4. 加载自定义命令行(包含yarn模式命令行和默认命令行两种)
final List<CustomCommandLine<?>> customCommandLines = loadCustomCommandLines(
configuration,
configurationDirectory);
try {
// 5. 初始化命令行前端
final CliFrontend cli = new CliFrontend(
configuration,
customCommandLines);
// 6. 安装安全机制
SecurityUtils.install(new SecurityConfiguration(cli.configuration));
// 7. 执行,回调。返回状态码retCode。所以这块将是主要逻辑
int retCode = SecurityUtils.getInstalledContext()
.runSecured(() -> cli.parseParameters(args));
System.exit(retCode);
}
catch (Throwable t) {
final Throwable strippedThrowable = ExceptionUtils.stripException(t, UndeclaredThrowableException.class);
LOG.error("Fatal error while running command line interface.", strippedThrowable);
strippedThrowable.printStackTrace();
System.exit(31);
}
}
2. 细节分析
2.1. 打印基本的环境信息
main入口执行的第一步是打印基本的环境信息。我们具体看下主要的逻辑:
/**
* 环境的日志信息, 像代码修订,当前用户,Java版本,和 JVM参数.
*
* @param log The logger to log the information to.
* @param componentName 日志中要提到的组件名称.
* @param commandLineArgs 启动组件时附带的参数。
*/
public static void logEnvironmentInfo(Logger log, String componentName, String[] commandLineArgs) {
if (log.isInfoEnabled()) {
// 1. 得到代码git的最终提交id和日期
RevisionInformation rev = getRevisionInformation();
// 2. 代码版本
String version = getVersion();
// 3.JVM版本,利用JavaSDK自带的ManagementFactory类来获取。
String jvmVersion = getJvmVersion();
// 4. JVM的启动参数,也是通过JavaSDK自带的ManagementFactory类来获取。
String[] options = getJvmStartupOptionsArray();
// 5. JAVA_Home目录
String javaHome = System.getenv("JAVA_HOME");
// 6. JVM的最大堆内存大小,单位Mb。
long maxHeapMegabytes = getMaxJvmHeapMemory() >>> 20;
// 7. 打印基本信息
log.info("--------------------------------------------------------------------------------");
log.info(" Starting " + componentName + " (Version: " + version + ", "
+ "Rev:" + rev.commitId + ", " + "Date:" + rev.commitDate + ")");
log.info(" OS current user: " + System.getProperty("user.name"));
log.info(" Current Hadoop/Kerberos user: " + getHadoopUser());
log.info(" JVM: " + jvmVersion);
log.info(" Maximum heap size: " + maxHeapMegabytes + " MiBytes");
log.info(" JAVA_HOME: " + (javaHome == null ? "(not set)" : javaHome));
// 打印出Hadoop的版本信息
String hadoopVersionString = getHadoopVersionString();
if (hadoopVersionString != null) {
log.info(" Hadoop version: " + hadoopVersionString);
} else {
log.info(" No Hadoop Dependency available");
}
// 打印JVM运行 参数
if (options.length == 0) {
log.info(" JVM Options: (none)");
}
else {
log.info(" JVM Options:");
for (String s: options) {
log.info(" " + s);
}
}
// 打印任务程序启动参数
if (commandLineArgs == null || commandLineArgs.length == 0) {
log.info(" Program Arguments: (none)");
}
else {
log.info(" Program Arguments:");
for (String s: commandLineArgs) {
log.info(" " + s);
}
}
log.info(" Classpath: " + System.getProperty("java.class.path"));
log.info("--------------------------------------------------------------------------------");
}
}
2.2. 获取配置目录
代码如下:
public static String getConfigurationDirectoryFromEnv() {
// 1. 得到环境变量的FLINK_CONF_DIR值
String location = System.getenv(ConfigConstants.ENV_FLINK_CONF_DIR);
if (location != null) {
if (new File(location).exists()) {
return location;
}
else {
throw new RuntimeException("The configuration directory '" + location + "', specified in the '" +
ConfigConstants.ENV_FLINK_CONF_DIR + "' environment variable, does not exist.");
}
}
// 2. 这里是得到./conf目录
else if (new File(CONFIG_DIRECTORY_FALLBACK_1).exists()) {
location = CONFIG_DIRECTORY_FALLBACK_1;
}
// 3. 这里是得到conf目录
else if (new File(CONFIG_DIRECTORY_FALLBACK_2).exists()) {
location = CONFIG_DIRECTORY_FALLBACK_2;
}
else {
throw new RuntimeException("The configuration directory was not specified. " +
"Please specify the directory containing the configuration file through the '" +
ConfigConstants.ENV_FLINK_CONF_DIR + "' environment variable.");
}
return location;
}
2.3. 加载全局配置
将第2步获取到的配置路径作为参数传进GlobalConfiguration.loadConfiguration方法中,以此用来加载全局配置。看下具体的逻辑:
public static Configuration loadConfiguration(final String configDir) {
return loadConfiguration(configDir, null);
}
进一步调用loadConfiguration方法:
public static Configuration loadConfiguration(final String configDir, @Nullable final Configuration dynamicProperties) {
if (configDir == null) {
throw new IllegalArgumentException("Given configuration directory is null, cannot load configuration");
}
final File confDirFile = new File(configDir);
if (!(confDirFile.exists())) {
throw new IllegalConfigurationException(
"The given configuration directory name '" + configDir +
"' (" + confDirFile.getAbsolutePath() + ") does not describe an existing directory.");
}
// 1. 得到flink-conf.yaml配置文件。
final File yamlConfigFile = new File(confDirFile, FLINK_CONF_FILENAME);
if (!yamlConfigFile.exists()) {
throw new IllegalConfigurationException(
"The Flink config file '" + yamlConfigFile +
"' (" + confDirFile.getAbsolutePath() + ") does not exist.");
}
// 2. 核心逻辑,解析YAML配置文件
Configuration configuration = loadYAMLResource(yamlConfigFile);
if (dynamicProperties != null) {
configuration.addAll(dynamicProperties);
}
return configuration;
}
代码可以看出来,加载全局配置的逻辑,是解析/conf/flink-conf.yaml文件,将里面的配置映射出来。存到Configuration中去。
2.4. 加载自定义命令行
任务提交方式有两种:yarn命令行提交模式和普通默认提交模式。看下具体逻辑:
/**
* 加载自定义命令行
* @param configuration 配置项
* @param configurationDirectory 配置文件目录
* @return
*/
public static List<CustomCommandLine<?>> loadCustomCommandLines(Configuration configuration, String configurationDirectory) {
// 1. 初始化一个容量是2的命令栏容器。
List<CustomCommandLine<?>> customCommandLines = new ArrayList<>(2);
// 2. YARN会话的命令行接口,所有选项参数都是以y/yarn前缀。
final String flinkYarnSessionCLI = "org.apache.flink.yarn.cli.FlinkYarnSessionCli";
try {
// 3. 添加yarn模式命令行
customCommandLines.add(
loadCustomCommandLine(flinkYarnSessionCLI,
configuration,
configurationDirectory,
"y",
"yarn"));
} catch (NoClassDefFoundError | Exception e) {
LOG.warn("Could not load CLI class {}.", flinkYarnSessionCLI, e);
}
// 4. 添加默认模式命令行
customCommandLines.add(new DefaultCLI(configuration));
return customCommandLines;
}
下面分别展开分析是怎么添加yarn模式命令行和默认模式命令行的。
添加yarn模式化命令行
/**
* 通过反射构建命令行
* @param className 加载的类名全程.
* @param params 构建参数
*/
private static CustomCommandLine<?> loadCustomCommandLine(String className, Object... params) throws IllegalAccessException, InvocationTargetException, InstantiationException, ClassNotFoundException, NoSuchMethodException {
// 1. 加载classpath里相关的类,这个加载的类实现了CustomCommandLine接口
Class<? extends CustomCommandLine> customCliClass =
Class.forName(className).asSubclass(CustomCommandLine.class);
// 2. 从参数里构建出参数的Class类型
Class<?>[] types = new Class<?>[params.length];
for (int i = 0; i < params.length; i++) {
Preconditions.checkNotNull(params[i], "Parameters for custom command-lines may not be null.");
types[i] = params[i].getClass();
}
// 3. 生成构造器org.apache.flink.yarn.cli$FlinkYarnSessionCli
Constructor<? extends CustomCommandLine> constructor = customCliClass.getConstructor(types);
// 4. 构造器实例化。调用org.apache.flink.yarn.cli$FlinkYarnSessionCli的构造方法,进行实例化。
return constructor.newInstance(params);
}
所以这里的逻辑是通过FlinkYarnSessionCli的构造器来实例化对象。所以进一步看具体调用了org.apache.flink.yarn.cli$FlinkYarnSessionCli的哪个构造器。这个是根据构造器的参数来的。看代码:
public FlinkYarnSessionCli(
Configuration configuration,
String configurationDirectory,
String shortPrefix,
String longPrefix) throws FlinkException {
this(configuration, configurationDirectory, shortPrefix, longPrefix, true);
}
进一步地调用this(configuration, configurationDirectory, shortPrefix, longPrefix, true)这个构造器。所以分析下这个构造器的具体逻辑:
/**
* 初始化一个FlinkYarnSessionCli
* @param configuration 全局的配置
* @param configurationDirectory 全局的配置文件目录
* @param shortPrefix 命令行参数的缩写前缀
* @param longPrefix 命令行参数的展开前缀
* @param acceptInteractiveInput 是否接受交互型输入
* @throws FlinkException
*/
public FlinkYarnSessionCli(
Configuration configuration,
String configurationDirectory,
String shortPrefix,
String longPrefix,
boolean acceptInteractiveInput) throws FlinkException {
// 1. 初始化参数
super(configuration);
this.configurationDirectory = Preconditions.checkNotNull(configurationDirectory);
this.acceptInteractiveInput = acceptInteractiveInput;
// 2. 创建命令行选项
query = new Option(shortPrefix + "q", longPrefix + "query", false, "Display available YARN resources (memory, cores)");
applicationId = new Option(shortPrefix + "id", longPrefix + "applicationId", true, "Attach to running YARN session");
queue = new Option(shortPrefix + "qu", longPrefix + "queue", true, "Specify YARN queue.");
shipPath = new Option(shortPrefix + "t", longPrefix + "ship", true, "Ship files in the specified directory (t for transfer)");
flinkJar = new Option(shortPrefix + "j", longPrefix + "jar", true, "Path to Flink jar file");
jmMemory = new Option(shortPrefix + "jm", longPrefix + "jobManagerMemory", true, "Memory for JobManager Container with optional unit (default: MB)");
tmMemory = new Option(shortPrefix + "tm", longPrefix + "taskManagerMemory", true, "Memory per TaskManager Container with optional unit (default: MB)");
container = new Option(shortPrefix + "n", longPrefix + "container", true, "Number of YARN container to allocate (=Number of Task Managers)");
slots = new Option(shortPrefix + "s", longPrefix + "slots", true, "Number of slots per TaskManager");
dynamicproperties = Option.builder(shortPrefix + "D")
.argName("property=value")
.numberOfArgs(2)
.valueSeparator()
.desc("use value for given property")
.build();
streaming = new Option(shortPrefix + "st", longPrefix + "streaming", false, "Start Flink in streaming mode");
name = new Option(shortPrefix + "nm", longPrefix + "name", true, "Set a custom name for the application on YARN");
zookeeperNamespace = new Option(shortPrefix + "z", longPrefix + "zookeeperNamespace", true, "Namespace to create the Zookeeper sub-paths for high availability mode");
nodeLabel = new Option(shortPrefix + "nl", longPrefix + "nodeLabel", true, "Specify YARN node label for the YARN application");
help = new Option(shortPrefix + "h", longPrefix + "help", false, "Help for the Yarn session CLI.");
allOptions = new Options();
allOptions.addOption(flinkJar);
allOptions.addOption(jmMemory);
allOptions.addOption(tmMemory);
allOptions.addOption(container);
allOptions.addOption(queue);
allOptions.addOption(query);
allOptions.addOption(shipPath);
allOptions.addOption(slots);
allOptions.addOption(dynamicproperties);
allOptions.addOption(DETACHED_OPTION);
allOptions.addOption(SHUTDOWN_IF_ATTACHED_OPTION);
allOptions.addOption(YARN_DETACHED_OPTION);
allOptions.addOption(streaming);
allOptions.addOption(name);
allOptions.addOption(applicationId);
allOptions.addOption(zookeeperNamespace);
allOptions.addOption(nodeLabel);
allOptions.addOption(help);
// 3. 加载默认的yarn配置文件
this.yarnPropertiesFileLocation = configuration.getString(YarnConfigOptions.PROPERTIES_FILE_LOCATION);
final File yarnPropertiesLocation = getYarnPropertiesLocation(yarnPropertiesFileLocation);
// 4. 解析出yarn的配置参数
yarnPropertiesFile = new Properties();
if (yarnPropertiesLocation.exists()) {
LOG.info("Found Yarn properties file under {}.", yarnPropertiesLocation.getAbsolutePath());
try (InputStream is = new FileInputStream(yarnPropertiesLocation)) {
yarnPropertiesFile.load(is);
} catch (IOException ioe) {
throw new FlinkException("Could not read the Yarn properties file " + yarnPropertiesLocation +
". Please delete the file at " + yarnPropertiesLocation.getAbsolutePath() + '.', ioe);
}
final String yarnApplicationIdString = yarnPropertiesFile.getProperty(YARN_APPLICATION_ID_KEY);
if (yarnApplicationIdString == null) {
throw new FlinkException("Yarn properties file found but doesn't contain a " +
"Yarn application id. Please delete the file at " + yarnPropertiesLocation.getAbsolutePath());
}
try {
// 尝试将id转化成ApplicationId
yarnApplicationIdFromYarnProperties = ConverterUtils.toApplicationId(yarnApplicationIdString);
}
catch (Exception e) {
throw new FlinkException("YARN properties contains an invalid entry for " +
"application id: " + yarnApplicationIdString + ". Please delete the file at " +
yarnPropertiesLocation.getAbsolutePath(), e);
}
} else {
yarnApplicationIdFromYarnProperties = null;
}
// 5. 初始化yarn的配置
this.yarnConfiguration = new YarnConfiguration();
}
添加默认模式命令行
默认命令行的逻辑简单,构造器初始化时,就初始化了配置项:
public DefaultCLI(Configuration configuration) {
super(configuration);
}
yarn模式命令客户端和默认普通模式客户端的类图关系如下:
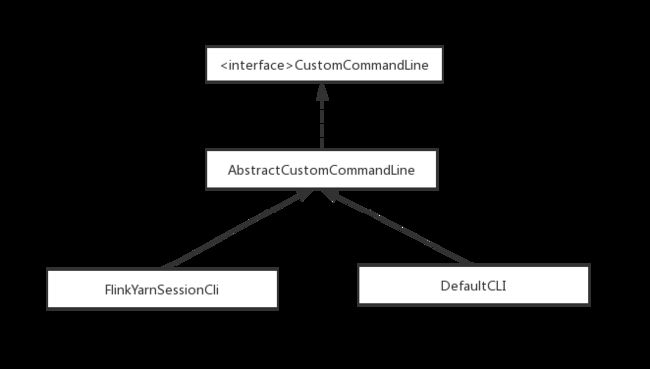
2.5. 初始化命令行前端
逻辑代码如下:
public CliFrontend(
Configuration configuration,
List<CustomCommandLine<?>> customCommandLines) throws Exception {
// 1. 初始化对象属性
this.configuration = Preconditions.checkNotNull(configuration);
this.customCommandLines = Preconditions.checkNotNull(customCommandLines);
try {
// 2. 初始化文件系统
FileSystem.initialize(this.configuration);
} catch (IOException e) {
throw new Exception("Error while setting the default " +
"filesystem scheme from configuration.", e);
}
// 3. 给命令行对象添加选项
this.customCommandLineOptions = new Options();
for (CustomCommandLine<?> customCommandLine : customCommandLines) {
customCommandLine.addGeneralOptions(customCommandLineOptions);
customCommandLine.addRunOptions(customCommandLineOptions);
}
// 4. 从全局配置里得到akka 客户端等待超时时间(akka.client.timeout)
this.clientTimeout = AkkaUtils.getClientTimeout(this.configuration);
// 5. 从全局配置里得到默认的系统并行度
this.defaultParallelism = configuration.getInteger(CoreOptions.DEFAULT_PARALLELISM);
}
2.6. 安装安全机制
安装安全机制的逻辑是调用:
SecurityUtils.install(new SecurityConfiguration(cli.configuration));
我们先分析下SecurityConfiguration对象的初始化,然后再分析SecurityUtils的install逻辑。
SecurityConfiguration初始化
/**
* 从全局配置创建安全配置.
* @param flinkConf flink全局配置
*/
public SecurityConfiguration(Configuration flinkConf) {
this(flinkConf, DEFAULT_MODULES);
}
其中DEFAULT_MODULES为默认的安全模板:
// 默认的安全模块
private static final List<SecurityModuleFactory> DEFAULT_MODULES = Collections.unmodifiableList(
Arrays.asList(new HadoopModuleFactory(), new JaasModuleFactory(), new ZookeeperModuleFactory()));
进一步看:
/**
* 从全局配置创建安全配置。
* @param flinkConf Flink的全局配置
* @param securityModuleFactories 要应用的安全模块.
*/
public SecurityConfiguration(Configuration flinkConf,
List<SecurityModuleFactory> securityModuleFactories) {
// 1. 一些全局参数的配置
this.isZkSaslDisable = flinkConf.getBoolean(SecurityOptions.ZOOKEEPER_SASL_DISABLE);
this.keytab = flinkConf.getString(SecurityOptions.KERBEROS_LOGIN_KEYTAB);
this.principal = flinkConf.getString(SecurityOptions.KERBEROS_LOGIN_PRINCIPAL);
this.useTicketCache = flinkConf.getBoolean(SecurityOptions.KERBEROS_LOGIN_USETICKETCACHE);
this.loginContextNames = parseList(flinkConf.getString(SecurityOptions.KERBEROS_LOGIN_CONTEXTS));
this.zkServiceName = flinkConf.getString(SecurityOptions.ZOOKEEPER_SASL_SERVICE_NAME);
this.zkLoginContextName = flinkConf.getString(SecurityOptions.ZOOKEEPER_SASL_LOGIN_CONTEXT_NAME);
// 2. 安全模块就是默认的安全模块
this.securityModuleFactories = Collections.unmodifiableList(securityModuleFactories);
this.flinkConfig = checkNotNull(flinkConf);
// 3. 验证
validate();
}
进一步看下validate的逻辑:
/**
* 验证
*/
private void validate() {
if (!StringUtils.isBlank(keytab)) {
// principal is required
if (StringUtils.isBlank(principal)) {
throw new IllegalConfigurationException("Kerberos login configuration is invalid; keytab requires a principal.");
}
// check the keytab is readable
File keytabFile = new File(keytab);
if (!keytabFile.exists() || !keytabFile.isFile() || !keytabFile.canRead()) {
throw new IllegalConfigurationException("Kerberos login configuration is invalid; keytab is unreadable");
}
}
}
如果全局配置(flink-conf.yaml)里配置了security.kerberos.login.keytab这个参数。那么要校验这个配置所指定的目录存在以及可读。这里其实有必要对kerberos的安全认证相关知识了解下。
SecurityUtils的install逻辑
SecurityConfiguration对象初始化好之后,作为参数传进SecurityUtils的install方法里面。具体逻辑:
/**
* 安装进程范围的安全配置。
*
* 使用可用的安全模块应用配置 (i.e. Hadoop, JAAS).
*/
public static void install(SecurityConfiguration config) throws Exception {
// 安装安全模块。
List<SecurityModule> modules = new ArrayList<>();
try {
// 遍历模板,对每个安全模板进行安装。
for (SecurityModuleFactory moduleFactory : config.getSecurityModuleFactories()) {
SecurityModule module = moduleFactory.createModule(config);
// can be null if a SecurityModule is not supported in the current environment
if (module != null) {
module.install();
modules.add(module);
}
}
}
catch (Exception ex) {
throw new Exception("unable to establish the security context", ex);
}
installedModules = modules;
// First check if we have Hadoop in the ClassPath. If not, we simply don't do anything.
try {
Class.forName(
"org.apache.hadoop.security.UserGroupInformation",
false,
SecurityUtils.class.getClassLoader());
// install a security context
// use the Hadoop login user as the subject of the installed security context
if (!(installedContext instanceof NoOpSecurityContext)) {
LOG.warn("overriding previous security context");
}
UserGroupInformation loginUser = UserGroupInformation.getLoginUser();
installedContext = new HadoopSecurityContext(loginUser);
} catch (ClassNotFoundException e) {
LOG.info("Cannot install HadoopSecurityContext because Hadoop cannot be found in the Classpath.");
} catch (LinkageError e) {
LOG.error("Cannot install HadoopSecurityContext.", e);
}
}
这里安装的安全模板主要包括了Java认证与授权服务(JAAS),Hadoop用户组信息(UGI)和Zookeeper的全过程安全设置。
2.7. 执行并且回调
执行逻辑:
int retCode = SecurityUtils.getInstalledContext()
.runSecured(() -> cli.parseParameters(args));
这一步是执行回调。runSecured的方法定义如下:
/**
* 可能需要具有的安全上下文才能运行可调用的.
*/
public interface SecurityContext {
<T> T runSecured(Callable<T> securedCallable) throws Exception;
}
具体执行逻辑是cli.parseParameters(args)。
所以重点分析parseParameters的逻辑:
/**
* 分析命令行参数并启动请求的操作.
*
* @param args 客户端的命令行参数.
* @return 程序的返回状态码
*/
public int parseParameters(String[] args) {
// 1. 检查动作
if (args.length < 1) {
CliFrontendParser.printHelp(customCommandLines);
System.out.println("Please specify an action.");
return 1;
}
// 2. 提取执行动作,比如run,list,cancel。这是命令的第一个参数
String action = args[0];
// 3. 从参数中移除执行动作
final String[] params = Arrays.copyOfRange(args, 1, args.length);
try {
// 4. 执行动作判断,分别做不同的处理
switch (action) {
case ACTION_RUN:
run(params);
return 0;
case ACTION_LIST:
list(params);
return 0;
case ACTION_INFO:
info(params);
return 0;
case ACTION_CANCEL:
cancel(params);
return 0;
case ACTION_STOP:
stop(params);
return 0;
case ACTION_SAVEPOINT:
savepoint(params);
return 0;
case ACTION_MODIFY:
modify(params);
return 0;
case "-h":
case "--help":
CliFrontendParser.printHelp(customCommandLines);
return 0;
case "-v":
case "--version":
String version = EnvironmentInformation.getVersion();
String commitID = EnvironmentInformation.getRevisionInformation().commitId;
System.out.print("Version: " + version);
System.out.println(commitID.equals(EnvironmentInformation.UNKNOWN) ? "" : ", Commit ID: " + commitID);
return 0;
default:
System.out.printf("\"%s\" is not a valid action.\n", action);
System.out.println();
System.out.println("Valid actions are \"run\", \"list\", \"info\", \"savepoint\", \"stop\", or \"cancel\".");
System.out.println();
System.out.println("Specify the version option (-v or --version) to print Flink version.");
System.out.println();
System.out.println("Specify the help option (-h or --help) to get help on the command.");
return 1;
}
} catch (CliArgsException ce) {
return handleArgException(ce);
} catch (ProgramParametrizationException ppe) {
return handleParametrizationException(ppe);
} catch (ProgramMissingJobException pmje) {
return handleMissingJobException();
} catch (Exception e) {
return handleError(e);
}
}
我们重点分析下执行任务的逻辑,即执行./flink run的逻辑。
执行run操作时的逻辑
具体代码:
/**
* 执行run操作
*
* @param args 运行操作的命令行参数。
*/
protected void run(String[] args) throws Exception {
LOG.info("Running 'run' command.");
final Options commandOptions = CliFrontendParser.getRunCommandOptions();
final Options commandLineOptions = CliFrontendParser.mergeOptions(commandOptions, customCommandLineOptions);
final CommandLine commandLine = CliFrontendParser.parse(commandLineOptions, args, true);
final RunOptions runOptions = new RunOptions(commandLine);
// 1.判断下是否是help操作
if (runOptions.isPrintHelp()) {
CliFrontendParser.printHelpForRun(customCommandLines);
return;
}
// 2.必须要指定任务的jar包路径
if (runOptions.getJarFilePath() == null) {
throw new CliArgsException("The program JAR file was not specified.");
}
// 3.初始化打包的任务执行程序
final PackagedProgram program;
try {
LOG.info("Building program from JAR file");
program = buildProgram(runOptions);
}
catch (FileNotFoundException e) {
throw new CliArgsException("Could not build the program from JAR file.", e);
}
final CustomCommandLine<?> customCommandLine = getActiveCustomCommandLine(commandLine);
try {
// 4. 执行任务程序
runProgram(customCommandLine, commandLine, runOptions, program);
} finally {
program.deleteExtractedLibraries();
}
}
继续看执行任务程序runProgram(customCommandLine, commandLine, runOptions, program):
/**
* 执行逻辑
* @param customCommandLine
* @param commandLine
* @param runOptions
* @param program
* @param
* @throws ProgramInvocationException
* @throws FlinkException
*/
private <T> void runProgram(
CustomCommandLine<T> customCommandLine,
CommandLine commandLine,
RunOptions runOptions,
PackagedProgram program) throws ProgramInvocationException, FlinkException {
final ClusterDescriptor<T> clusterDescriptor = customCommandLine.createClusterDescriptor(commandLine);
try {
final T clusterId = customCommandLine.getClusterId(commandLine);
// 集群客户端
final ClusterClient<T> client;
// directly deploy the job if the cluster is started in job mode and detached
if (clusterId == null && runOptions.getDetachedMode()) {
int parallelism = runOptions.getParallelism() == -1 ? defaultParallelism : runOptions.getParallelism();
// 构建JobGraph
final JobGraph jobGraph = PackagedProgramUtils.createJobGraph(program, configuration, parallelism);
final ClusterSpecification clusterSpecification = customCommandLine.getClusterSpecification(commandLine);
// 装载任务
client = clusterDescriptor.deployJobCluster(
clusterSpecification,
jobGraph,
runOptions.getDetachedMode());
logAndSysout("Job has been submitted with JobID " + jobGraph.getJobID());
try {
client.shutdown();
} catch (Exception e) {
LOG.info("Could not properly shut down the client.", e);
}
} else {
final Thread shutdownHook;
if (clusterId != null) {
client = clusterDescriptor.retrieve(clusterId);
shutdownHook = null;
} else {
// also in job mode we have to deploy a session cluster because the job
// might consist of multiple parts (e.g. when using collect)
final ClusterSpecification clusterSpecification = customCommandLine.getClusterSpecification(commandLine);
client = clusterDescriptor.deploySessionCluster(clusterSpecification);
// if not running in detached mode, add a shutdown hook to shut down cluster if client exits
// there's a race-condition here if cli is killed before shutdown hook is installed
if (!runOptions.getDetachedMode() && runOptions.isShutdownOnAttachedExit()) {
shutdownHook = ShutdownHookUtil.addShutdownHook(client::shutDownCluster, client.getClass().getSimpleName(), LOG);
} else {
shutdownHook = null;
}
}
try {
client.setPrintStatusDuringExecution(runOptions.getStdoutLogging());
client.setDetached(runOptions.getDetachedMode());
LOG.debug("Client slots is set to {}", client.getMaxSlots());
LOG.debug("{}", runOptions.getSavepointRestoreSettings());
int userParallelism = runOptions.getParallelism();
LOG.debug("User parallelism is set to {}", userParallelism);
if (client.getMaxSlots() != MAX_SLOTS_UNKNOWN && userParallelism == -1) {
logAndSysout("Using the parallelism provided by the remote cluster ("
+ client.getMaxSlots() + "). "
+ "To use another parallelism, set it at the ./bin/flink client.");
userParallelism = client.getMaxSlots();
} else if (ExecutionConfig.PARALLELISM_DEFAULT == userParallelism) {
userParallelism = defaultParallelism;
}
// 执行程序核心逻辑
executeProgram(program, client, userParallelism);
} finally {
if (clusterId == null && !client.isDetached()) {
// terminate the cluster only if we have started it before and if it's not detached
try {
client.shutDownCluster();
} catch (final Exception e) {
LOG.info("Could not properly terminate the Flink cluster.", e);
}
if (shutdownHook != null) {
// we do not need the hook anymore as we have just tried to shutdown the cluster.
ShutdownHookUtil.removeShutdownHook(shutdownHook, client.getClass().getSimpleName(), LOG);
}
}
try {
client.shutdown();
} catch (Exception e) {
LOG.info("Could not properly shut down the client.", e);
}
}
}
} finally {
try {
clusterDescriptor.close();
} catch (Exception e) {
LOG.info("Could not properly close the cluster descriptor.", e);
}
}
}
接着分析executeProgram(program, client, userParallelism)的逻辑:
protected void executeProgram(PackagedProgram program, ClusterClient<?> client, int parallelism) throws ProgramMissingJobException, ProgramInvocationException {
logAndSysout("Starting execution of program");
// 执行任务
final JobSubmissionResult result = client.run(program, parallelism);
if (null == result) {
throw new ProgramMissingJobException("No JobSubmissionResult returned, please make sure you called " +
"ExecutionEnvironment.execute()");
}
// 判断是否返回了任务程序执行的结果。即代表任务正常执行完了。
if (result.isJobExecutionResult()) {
logAndSysout("Program execution finished");
JobExecutionResult execResult = result.getJobExecutionResult();
System.out.println("Job with JobID " + execResult.getJobID() + " has finished.");
System.out.println("Job Runtime: " + execResult.getNetRuntime() + " ms");
Map<String, Object> accumulatorsResult = execResult.getAllAccumulatorResults();
if (accumulatorsResult.size() > 0) {
System.out.println("Accumulator Results: ");
System.out.println(AccumulatorHelper.getResultsFormatted(accumulatorsResult));
}
} else {
logAndSysout("Job has been submitted with JobID " + result.getJobID());
}
}
这里是通过ClusterClient来运行已经打包好的任务。并且获取到执行完之后的结果JobSubmissionResult。
ClusterClient运行任务的逻辑如下:
/**
* 从CliFronted中运行一个用户自定义的jar包来运行任务程序。运行模式有阻塞(blocking)模式和分离(detached)模式。
* 具体是什么模式,主要看{@code setDetached(true)} or {@code setDetached(false)}.
* @param prog 打包过的程序
* @param parallelism 执行Flink job的并行度
* @return 执行的结果
* @throws ProgramMissingJobException
* @throws ProgramInvocationException
*/
public JobSubmissionResult run(PackagedProgram prog, int parallelism)
throws ProgramInvocationException, ProgramMissingJobException {
Thread.currentThread().setContextClassLoader(prog.getUserCodeClassLoader());
// 1. 如果程序指定了执行入口
if (prog.isUsingProgramEntryPoint()) {
final JobWithJars jobWithJars;
if (hasUserJarsInClassPath(prog.getAllLibraries())) {
jobWithJars = prog.getPlanWithoutJars();
} else {
jobWithJars = prog.getPlanWithJars();
}
// 执行主逻辑
return run(jobWithJars, parallelism, prog.getSavepointSettings());
}
// 2. 如果没有指定执行入口,那么就利用交互模式执行程序
else if (prog.isUsingInteractiveMode()) {
log.info("Starting program in interactive mode (detached: {})", isDetached());
final List<URL> libraries;
if (hasUserJarsInClassPath(prog.getAllLibraries())) {
libraries = Collections.emptyList();
} else {
libraries = prog.getAllLibraries();
}
ContextEnvironmentFactory factory = new ContextEnvironmentFactory(this, libraries,
prog.getClasspaths(), prog.getUserCodeClassLoader(), parallelism, isDetached(),
prog.getSavepointSettings());
ContextEnvironment.setAsContext(factory);
try {
// invoke main method
prog.invokeInteractiveModeForExecution();
if (lastJobExecutionResult == null && factory.getLastEnvCreated() == null) {
throw new ProgramMissingJobException("The program didn't contain a Flink job.");
}
if (isDetached()) {
// in detached mode, we execute the whole user code to extract the Flink job, afterwards we run it here
return ((DetachedEnvironment) factory.getLastEnvCreated()).finalizeExecute();
}
else {
// in blocking mode, we execute all Flink jobs contained in the user code and then return here
return this.lastJobExecutionResult;
}
}
finally {
ContextEnvironment.unsetContext();
}
}
else {
throw new ProgramInvocationException("PackagedProgram does not have a valid invocation mode.");
}
}
我们这里不考虑交互模型,即只考虑任务程序的执行入口给定的情况。所以重点分析run(jobWithJars, parallelism, prog.getSavepointSettings())的逻辑。
/**
* 通过客户端,在Flink集群中运行程序。调用将一直阻塞,知道执行结果返回。
*
* @param jobWithJars 任务jar包.
* @param parallelism 运行该任务的并行度
*
*/
public JobSubmissionResult run(JobWithJars jobWithJars, int parallelism, SavepointRestoreSettings savepointSettings)
throws CompilerException, ProgramInvocationException {
// 获取类加载器
ClassLoader classLoader = jobWithJars.getUserCodeClassLoader();
if (classLoader == null) {
throw new IllegalArgumentException("The given JobWithJars does not provide a usercode class loader.");
}
// 得到优化执行计划
OptimizedPlan optPlan = getOptimizedPlan(compiler, jobWithJars, parallelism);
// 执行
return run(optPlan, jobWithJars.getJarFiles(), jobWithJars.getClasspaths(), classLoader, savepointSettings);
}
这里重点是优化执行计划是怎么生成的。本文主要是讲解整体流程,所以暂不对这个做重点研究。后续文章会对执行计划的生成做重点研究。
进一步分析run(optPlan, jobWithJars.getJarFiles(), jobWithJars.getClasspaths(), classLoader, savepointSettings)流程。
public JobSubmissionResult run(FlinkPlan compiledPlan,
List<URL> libraries, List<URL> classpaths, ClassLoader classLoader, SavepointRestoreSettings savepointSettings)
throws ProgramInvocationException {
// 得到JobGraph
JobGraph job = getJobGraph(flinkConfig, compiledPlan, libraries, classpaths, savepointSettings);
// 提交任务执行
return submitJob(job, classLoader);
}
进一步看提交任务执行的逻辑submitJob(job, classLoader)。
不同的运行模式,提交逻辑是不一样的。我们就看下standalone模式的逻辑:
public JobSubmissionResult submitJob(JobGraph jobGraph, ClassLoader classLoader)
throws ProgramInvocationException {
// 分离模式
if (isDetached()) {
return super.runDetached(jobGraph, classLoader);
// 非分离模式
} else {
return super.run(jobGraph, classLoader);
}
}
我们重点分析下非分离模式。
/**
* 阻塞式地提交一个JobGraph
* @param jobGraph The JobGraph
* @param classLoader User code class loader to deserialize the results and errors (may contain custom classes).
* @return JobExecutionResult
* @throws ProgramInvocationException
*/
public JobExecutionResult run(JobGraph jobGraph, ClassLoader classLoader) throws ProgramInvocationException {
// 等待集群准备好,因为是standalone模式,所以这一步实际上啥都不用做。
waitForClusterToBeReady();
final ActorSystem actorSystem;
try {
actorSystem = actorSystemLoader.get();
} catch (FlinkException fe) {
throw new ProgramInvocationException("Could not start the ActorSystem needed to talk to the " +
"JobManager.", jobGraph.getJobID(), fe);
}
try {
logAndSysout("Submitting job with JobID: " + jobGraph.getJobID() + ". Waiting for job completion.");
// 提交任务并且等待结果
this.lastJobExecutionResult = JobClient.submitJobAndWait(
actorSystem,
flinkConfig,
highAvailabilityServices,
jobGraph,
timeout,
printStatusDuringExecution,
classLoader);
return lastJobExecutionResult;
} catch (JobExecutionException e) {
throw new ProgramInvocationException("The program execution failed: " + e.getMessage(), jobGraph.getJobID(), e);
}
}
进一步分析JobClient.submitJobAndWait的逻辑:
/**
* Sends a [[JobGraph]] to the JobClient actor specified by jobClient which submits it then to
* the JobManager. The method blocks until the job has finished or the JobManager is no longer
* alive. In the former case, the [[SerializedJobExecutionResult]] is returned and in the latter
* case a [[JobExecutionException]] is thrown.
*
* @param actorSystem 用来通信的actor system
* @param config 集群的配置
* @param highAvailabilityServices Service factory for high availability services
* @param jobGraph 描述Flink job的JobGraph
* @param timeout 等待futures的超时时间
* @param sysoutLogUpdates 如果true,那么就实时打印运行日志
* @param classLoader 解析结果的类加载器
* @return The job execution result
* @throws JobExecutionException Thrown if the job
* execution fails.
*/
public static JobExecutionResult submitJobAndWait(
ActorSystem actorSystem,
Configuration config,
HighAvailabilityServices highAvailabilityServices,
JobGraph jobGraph,
FiniteDuration timeout,
boolean sysoutLogUpdates,
ClassLoader classLoader) throws JobExecutionException {
// 提交Job
JobListeningContext jobListeningContext = submitJob(
actorSystem,
config,
highAvailabilityServices,
jobGraph,
timeout,
sysoutLogUpdates,
classLoader);
// 监听,等待执行结果返回
return awaitJobResult(jobListeningContext);
}
先分析下submitJob的逻辑:
/**
* Submits a job to a Flink cluster (non-blocking) and returns a JobListeningContext which can be
* passed to {@code awaitJobResult} to get the result of the submission.
* @return JobListeningContext which may be used to retrieve the JobExecutionResult via
* {@code awaitJobResult(JobListeningContext context)}.
*/
public static JobListeningContext submitJob(
ActorSystem actorSystem,
Configuration config,
HighAvailabilityServices highAvailabilityServices,
JobGraph jobGraph,
FiniteDuration timeout,
boolean sysoutLogUpdates,
ClassLoader classLoader) {
checkNotNull(actorSystem, "The actorSystem must not be null.");
checkNotNull(highAvailabilityServices, "The high availability services must not be null.");
checkNotNull(jobGraph, "The jobGraph must not be null.");
checkNotNull(timeout, "The timeout must not be null.");
// for this job, we create a proxy JobClientActor that deals with all communication with
// the JobManager. It forwards the job submission, checks the success/failure responses, logs
// update messages, watches for disconnect between client and JobManager, ...
Props jobClientActorProps = JobSubmissionClientActor.createActorProps(
highAvailabilityServices.getJobManagerLeaderRetriever(HighAvailabilityServices.DEFAULT_JOB_ID),
timeout,
sysoutLogUpdates,
config);
ActorRef jobClientActor = actorSystem.actorOf(jobClientActorProps);
Future<Object> submissionFuture = Patterns.ask(
jobClientActor,
new JobClientMessages.SubmitJobAndWait(jobGraph), // 提交等待任务。
new Timeout(AkkaUtils.INF_TIMEOUT()));
return new JobListeningContext(
jobGraph.getJobID(),
submissionFuture,
jobClientActor,
timeout,
classLoader,
highAvailabilityServices);
}
再来看下awaitJobResult(jobListeningContext)的逻辑:
public static JobExecutionResult awaitJobResult(JobListeningContext listeningContext) throws JobExecutionException {
final JobID jobID = listeningContext.getJobID();
final ActorRef jobClientActor = listeningContext.getJobClientActor();
final Future<Object> jobSubmissionFuture = listeningContext.getJobResultFuture();
final FiniteDuration askTimeout = listeningContext.getTimeout();
// retrieves class loader if necessary
final ClassLoader classLoader = listeningContext.getClassLoader();
// wait for the future which holds the result to be ready
// ping the JobClientActor from time to time to check if it is still running
while (!jobSubmissionFuture.isCompleted()) {
try {
Await.ready(jobSubmissionFuture, askTimeout);
} catch (InterruptedException e) {
throw new JobExecutionException(
jobID,
"Interrupted while waiting for job completion.");
} catch (TimeoutException e) {
try {
Await.result(
Patterns.ask(
jobClientActor,
// Ping the Actor to see if it is alive
new Identify(true),
Timeout.durationToTimeout(askTimeout)),
askTimeout);
// we got a reply, continue waiting for the job result
} catch (Exception eInner) {
// we could have a result but the JobClientActor might have been killed and
// thus the health check failed
if (!jobSubmissionFuture.isCompleted()) {
throw new JobExecutionException(
jobID,
"JobClientActor seems to have died before the JobExecutionResult could be retrieved.",
eInner);
}
}
}
}
final Object answer;
try {
// we have already awaited the result, zero time to wait here
answer = Await.result(jobSubmissionFuture, Duration.Zero());
}
catch (Throwable throwable) {
throw new JobExecutionException(jobID,
"Couldn't retrieve the JobExecutionResult from the JobManager.", throwable);
}
finally {
// failsafe shutdown of the client actor
jobClientActor.tell(PoisonPill.getInstance(), ActorRef.noSender());
}
// second block handles the actual response
if (answer instanceof JobManagerMessages.JobResultSuccess) {
LOG.info("Job execution complete");
SerializedJobExecutionResult result = ((JobManagerMessages.JobResultSuccess) answer).result();
if (result != null) {
try {
return result.toJobExecutionResult(classLoader);
} catch (Throwable t) {
throw new JobExecutionException(jobID,
"Job was successfully executed but JobExecutionResult could not be deserialized.");
}
} else {
throw new JobExecutionException(jobID,
"Job was successfully executed but result contained a null JobExecutionResult.");
}
}
else if (answer instanceof JobManagerMessages.JobResultFailure) {
LOG.info("Job execution failed");
SerializedThrowable serThrowable = ((JobManagerMessages.JobResultFailure) answer).cause();
if (serThrowable != null) {
Throwable cause = serThrowable.deserializeError(classLoader);
if (cause instanceof JobExecutionException) {
throw (JobExecutionException) cause;
} else {
throw new JobExecutionException(jobID, "Job execution failed", cause);
}
} else {
throw new JobExecutionException(jobID,
"Job execution failed with null as failure cause.");
}
}
else if (answer instanceof JobManagerMessages.JobNotFound) {
throw new JobRetrievalException(
((JobManagerMessages.JobNotFound) answer).jobID(),
"Couldn't retrieve Job " + jobID + " because it was not running.");
}
else {
throw new JobExecutionException(jobID,
"Unknown answer from JobManager after submitting the job: " + answer);
}
}
总结
分析Flink客户端提交任务的执行逻辑,发现主要难点是:
- 执行计划OptimizedPlan的生成逻辑。
- JobGraph的生成。
- Actor模式下,客户端提交任务,然后和JobManager的交互过程。
后续会继续分析这些重点细节。