分布式大数据环境搭建教程
写在前面的话
在安装过程中会遇到很多linux命令,在此对重要命令进行总结
(1):VMware虚拟机与Windows间系统光标切换快捷键:Ctrl+Alt
(2):linux系统复制快捷键:Ctrl+Insert
(3):linux系统粘贴快捷键是:Shift+Insert
(4):linux系统vi编辑器下搜索快捷键:/+你要搜索的内容
(5):linux系统vi编辑器下显示文件内容行号执行::set nu命令即可
(6):linux删除文件命令:rm-rf,-rf参数表示递归强制删除
(7):linux命令行补全快捷键,按下Tab键即可
(8):hdfs创建文件夹:~/hadoop/bin/hadoop fs -mkdir
(9):hdfs删除文件夹:~/hadoop/bin/hadoop fs -rm -r
(10):hdfs查看文件夹下内容:~/hadoop/bin/hadoop fs -ls
(11):停止命令行执行快捷键:Ctrl+C
(12):返回上一次访问的文件目录执行命令:cd -
1. 安装VMware Workstation 12
安装方法是一路next,安装成功之后,输入秘钥:5A02H-AU243-TZJ49-GTC7K-3C61N
2. 安装CentOS6.9
参考教程:http://blog.csdn.net/ProgrammingWay/article/details/78237856
安装过程中可能出现的问题
问题1:在打开虚拟机之后,出现下面报错界面:
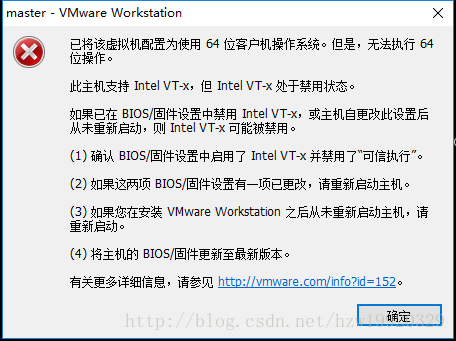
错误原因:因为本机禁用了Intel Virtualization Technology功能,具体解决方法参考:http://www.jb51.net/softjc/494576.html
问题2:在安装CentOS系统的时候,可能会出现下面选项窗体
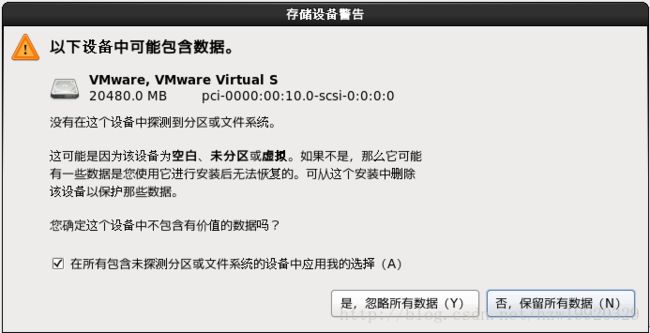
选择是,忽略所有数据即可,不用担心,它格式化的只是虚拟机硬盘里面的数据,和你自己的物理机器硬盘数据没有关系
3. 按照同样的方法创建几个虚拟机
4. 配置虚拟机处于同一个网段
(1):首先查看虚拟机使用的物理网卡
点击VMware的工具栏编辑—>虚拟网络编辑器
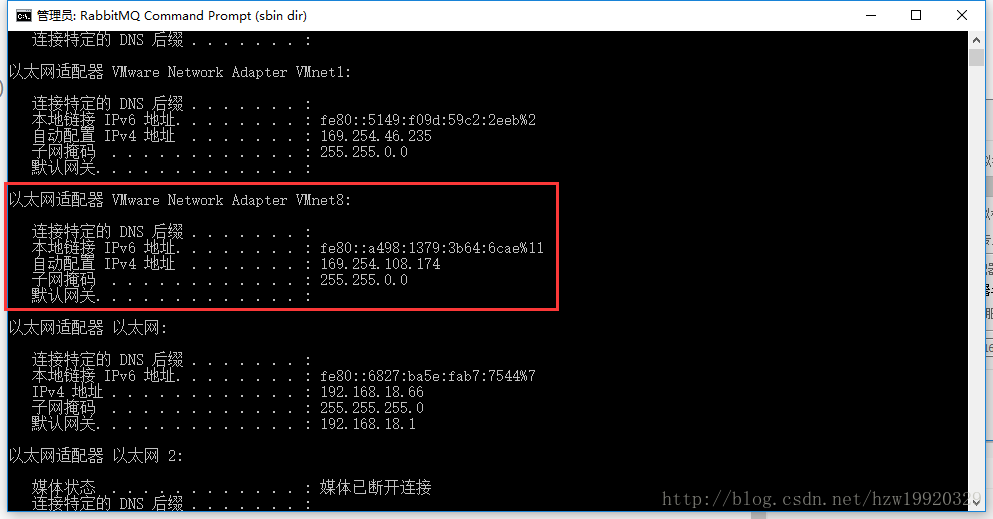
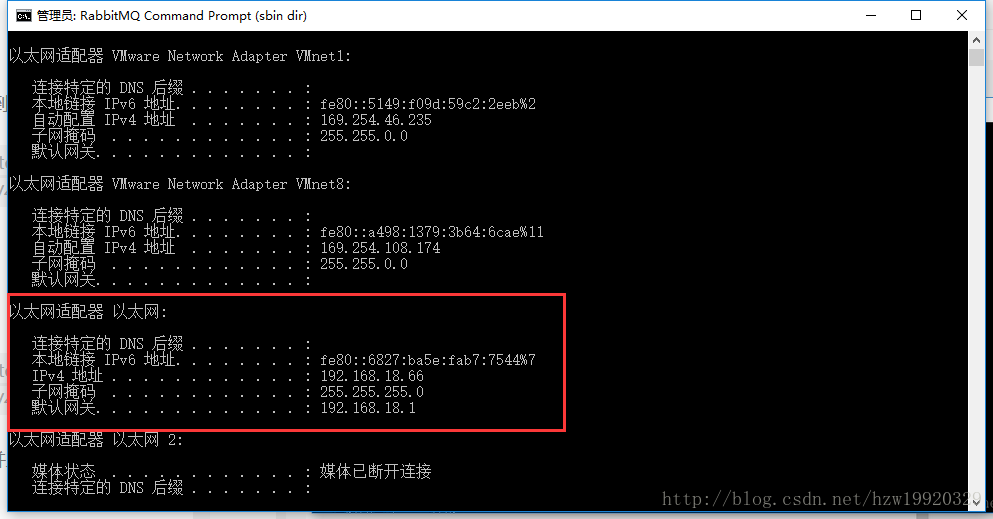
(2):查看VMnet8对应的IP地址,方法是在cmd命令下输入ipconfig
(3):打开网络和共享中心—>更改适配器设置—>以太网,右键选择属性界面,切换到共享选项卡,进行如下设置

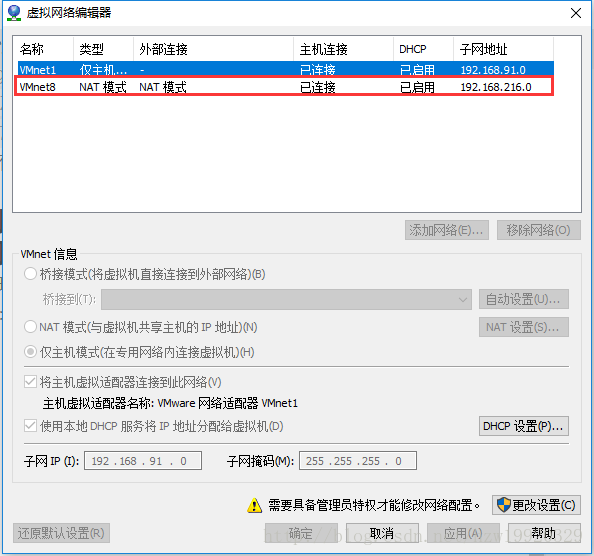
(4):点击VMware的工具栏编辑—>虚拟网络编辑器,进行如下设置

注意不要勾选使用本地DHCP服务器将IP地址分配给虚拟机这个复选框,其中VMnet8的IP设置成192.168.18.0的原因是,本机以太网的IP是192.168.18.66,并且其子网掩码是255.255.255.0
(5):点击NAT设置按钮,进行下面设置

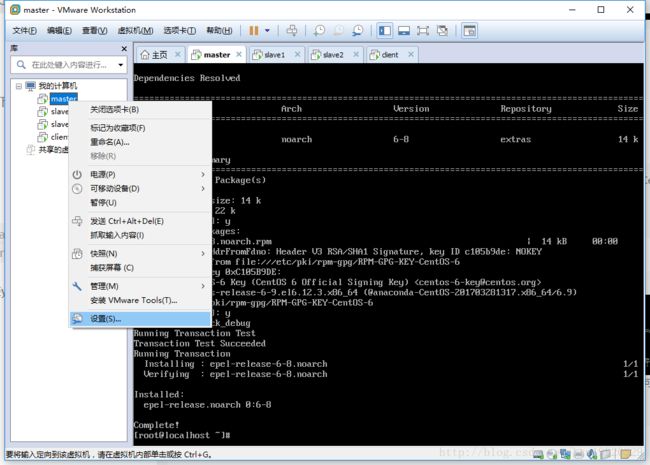
(6):首选登录名称为master的那个CentOS系统(本教程集群包含master、slave1、slave2、client四台虚拟机),分别执行下面命令
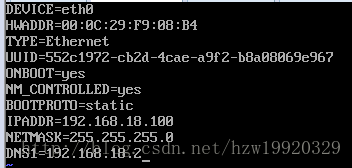
vi /etc/sysconfig/network-scripts/ifcfg-eth0
将ifcfg-eth0文件修改如下:
执行shutdown -r now重启系统,以使得我们刚刚的配置生效
执行vi /etc/resolv.conf修改resolv.conf文件,进行下面设置

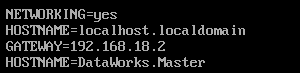
执行vi /etc/sysconfig/network,修改network文件,其中HOSTNAME的值在不同的机器下要设置成不同的
执行service network restart重启网络服务
执行vi /etc/hosts设置hosts文件,设置

执行ip addr,结果如下图所示即表示设置静态IP成功

执行ping 192.168.18.66,其中192.168.18.66表示物理主机的ip地址,出现下面输出表示物理主机和虚拟主机处于同一网段啦

(7):这样对master虚拟机的ip配置结束了,用同样的方式配置slave1、slave2、以及client,设置其ip分别是192.168.18.101,192.168.18.105,192.168.18.106,所不同的是需要修改上面network文件里面的HOSTNAME名称
(8):在每台虚拟机上执行vi /etc/hosts,将所有的虚拟机hosts文件修改成下面这样

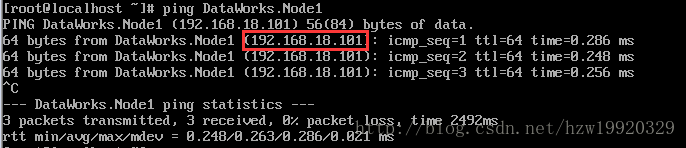
执行ping DataWorks.Node1,如果出现下面输出,表示hosts文件修改成功
5. 安装XShell用于ssh登录虚拟机
6. 安装WinSCP用于向虚拟机传送文件内容
7. 安装yum源,用于软件包管理(每台虚拟机)
但是CentOS的yum源相对更新较慢,因此下载一些额外的第三方软件源,这里下载epel源,打开CentOS命令行,输入下面命令:
yum install epel-release
yum makecache
在每台虚拟机上均安装yum源
安装过程中可能出现的问题
问题1:出现下面的报错信息

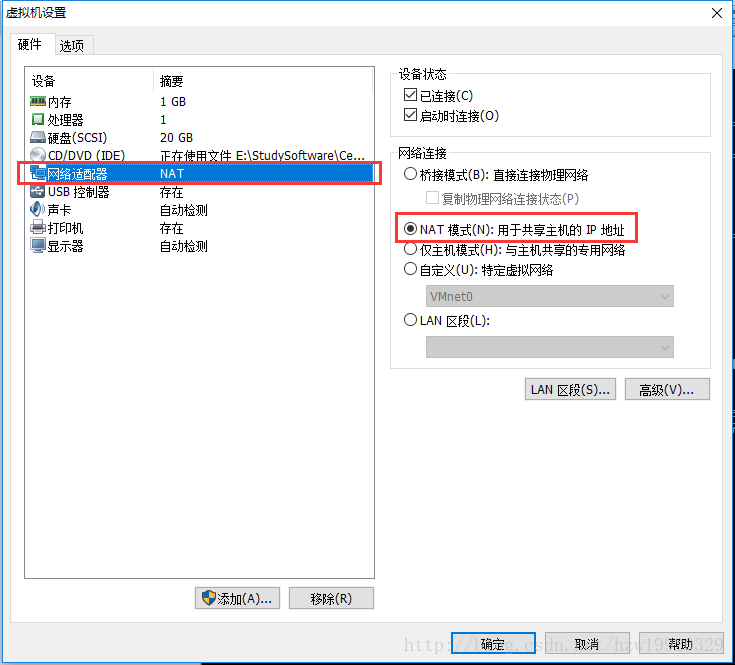
出错原因:因为我们物理主机与虚拟机之间的连接方式目前是桥接模式,而安装yum资源是需要访问Internet的,只有改成NAT模式才能正确访问网络资源。
解决方法:
8. 安装JDK1.7(每台虚拟机)
因为hadoop是运行在java环境之上的,我们可以使用yum的方式进行轻松安装,执行下面命令:
yum install java-1.7.0-openjdk*
配置java环境变量:
首先执行ls -l /usr/lib/jvm,查看是否已经安装JDK
执行vi /etc/profile,在末尾添加下面信息
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.161.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:
$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
执行java -version,出现下面界面表示JDK安装成功

9. 为后续hadoop操作创建专门用户(每台虚拟机)
(1):添加一个名为hadoop的用户组,执行命令:groupadd hadoop
(2):添加一个hadoop用户并加入hadoop组,执行命令:useradd hadoop -g hadoop
(3):编辑sudoers文件,给hadoop用户授予sudo权限,执行命令:vi /etc/sudoers,在sudoers的尾部添加下面这行代码hadoop ALL=(ALL) ALL,如果在执行:wq保存退出的时候出现下面错误,只需要执行:wq!即可。

10. 配置虚拟机之间ssh免密码登录
Hadoop的基础是分布式文件系统HDFS,HDFS集群有两类节点以管理者-工作者的模式运行,即一个namenode(管理者)和多个datanode(工作者)。在Hadoop启动以后,namenode通过SSH来启动和停止各个节点上的各种守护进程,这就需要在这些节点之间执行指令时采用无需输入密码的认证方式,因此,我们需要将SSH配置成使用无需输入root密码的密钥文件认证方式。
首先在Master主机上
(1):重新设置hadoop用户的密码,具体就是执行下面命令,首先通过su root切换到root用户下,接着执行echo “123456” | passwd –stdin hadoop,将hadoop用户的密码也设置成123456
(2):执行命令:su hadoop,切换到hadoop用户
(3):执行命令:cd ~,进入hadoop用户目录
(4):执行ssh-keygen生成秘钥,在执行ssh-keygen的过程中,出现提示框的时候,只需要按下Enter键即可,总共需要按3次Enter键,具体每一次提示分别表示,第一次是询问秘钥的生成路径,我们直接默认即可,第二次是询问用户输入秘钥,因为我们要做的是免密码登录,按下Enter表示无密码,第三次提示用户输入刚刚输入的秘钥,因为我们已经设置成无密码登录了,因此此时也是直接按下Enter键即可
(5):执行命令:ls ~/.ssh可以看到下面已经生成id_rsa id_rsa.pub这两个秘钥文件了,具体来讲一个是公钥,一个是私钥
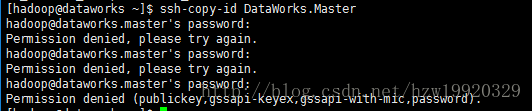
(6):复制master公钥到master上,执行命令:ssh-copy-id DataWorks.Master,执行这条命令的时候,可能会出现下面错误:
解决方法步骤如下
参考:http://blog.csdn.net/songhuiqiao/article/details/40427739
第一步,su root用户下,执行vi /etc/ssh/sshd_config命令,修改sshd_config文件,具体就是打开下面代码的注释(即去掉其前面的#即可):
HostKey /etc/ssh/ssh_host_rsa_key
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
再执行命令:/etc/init.d/sshd restart
第二步具体来讲就是修改hadoop文件夹,.ssh文件夹,以及id_rsa id_rsa.pub文件的权限即可,分别执行下面命令即可:
chmod 700 /home/hadoop
chmod 700 /home/hadoop/.ssh
chmod 600 /home/hadoop/.ssh/id_rsa
(7):复制master公钥到DataWorks.Node1、DataWorks.Node2以及DataWorks.client下,具体就是分别执行下面命令,在第一次执行的时候,是需要输入root用户的密码:
ssh-copy-id DataWorks.Node1
ssh-copy-id DataWorks.Node2
ssh-copy-id DataWorks.client
这时候,通过vi ~/.ssh/known_hosts命令,你会看到下面输出
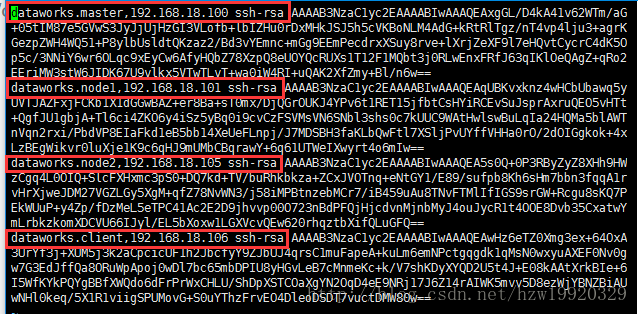
可以发现,Master、Node1、Node2以及client已经出现在了当前Master能够识别的机器列表中
(8):通过ssh免密码登录其他机器,验证命令行为:
ssh DataWorks.Master
exit
ssh DataWorks.Node1
exit
ssh DataWorks.Node2
exit
ssh DataWorks.client
exit
退出命令行的方式是,输入exit即可
(9):按照同样的方式设置Node1、Node2以及client能够免密码登录到其他机器
注意事项:
①一定要保证Master、Node1、Node2以及client这四台机器之间能够两两免密码登录。
②在免密码登录完成之后,一定要能够记清楚你当前登录的是哪台机器,避免混淆。
11. 下载、安装并配置hadoop
(1):首先切换到hadoop用户下,通过yum源安装wget包,具体就是执行sudo yum -y install wget命令
(2):执行命令:wget -c http://mirrors.shuosc.org/apache/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz下载hadoop-2.7.5.tar.gz,如果你想下载不同版本的,可以通过http://hadoop.apache.org/releases.html找到
(3):将hadoop-2.7.5.tar.gz解压到~目录下,并将hadoop-2.7.5.tar.gz文件夹重命名为hadoop,具体来说就是执行下面两条命令:
tar -zxvf hadoop-2.7.5.tar.gz
mv hadoop-2.7.5 hadoop
(4):配置hadoop-env.sh,执行vi ~/hadoop/etc/hadoop/hadoop-env.sh修改文件,找到export JAVA_HOME的位置,将其内容修改成:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.161.x86_64
(5):配置yarn-env.sh,执行vi ~/hadoop/etc/hadoop/yarn-env.sh修改文件,找到export JAVA_HOME的位置,打开注释,将其内容修改成:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.161.x86_64
(6):配置slaves文件,执行vi ~/hadoop/etc/hadoop/slaves,在其中添加下面内容
DataWorks.Node1
DataWorks.Node2
DataWorks.client
(7):配置core-site.xml文件
在配置core-site.xml文件之前,需要在~/hadoop下面创建一个tmp文件夹,具体就是执行命令:mkdir ~/hadoop/tmp
接着执行命令:vi ~/hadoop/etc/hadoop/core-site.xml,在configuration标签中间添加下面信息:
hadoop.tmp.dir
/home/hadoop/hadoop/tmp
fs.default.name
hdfs://DataWorks.Master:9000
其中fs.default.name配置了hadoop的HDFS系统的命名,位于主机的9000端口
(8):配置hdfs-site.xml文件
执行命令:vi ~/hadoop/etc/hadoop/hdfs-site.xml,在configuration标签中间添加下面信息:
dfs.http.address
DataWorks.Master:50070
dfs.namenode.secondary.http.address
DataWorks.Master:50090
dfs.replication
1
(9):配置mapred-site.xml文件
首先执行命令,根据模板文件创建mapred-site.xml文件,cp ~/hadoop/etc/hadoop/mapred-site.xml.template ~/hadoop/etc/hadoop/mapred-site.xml
接着执行vi ~/hadoop/etc/hadoop/mapred-site.xml,在configuration标签中间添加下面信息:
mapred.job.tracker
DataWorks.Master:9001
mapred.map.tasks
20
mapred.reduce.tasks
4
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
DataWorks.Master:10020
mapreduce.jobhistory.webapp.address
DataWorks.Master:19888
(10):配置yarn-site.xml文件,在configuration标签中间添加下面信息:
执行命令:vi ~/hadoop/etc/hadoop/yarn-site.xml
yarn.resourcemanager.address
DataWorks.Master:8032
yarn.resourcemanager.scheduler.address
DataWorks.Master:8030
yarn.resourcemanager.webapp.address
DataWorks.Master:8088
yarn.resourcemanager.resource-tracker.address
DataWorks.Master:8031
yarn.resourcemanager.admin.address
DataWorks.Master:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.aux-services这句配置了节点管理器运行的附加服务为mapreduce_shuffle,只有这样才能运行MapReduce程序
(11):将这些配置复制到DataWorks.Node1和DataWorks.Node2以及DataWorks.client上,具体就是执行下面命令:
scp -r ~/hadoop [email protected]:~/
scp -r ~/hadoop [email protected]:~/
scp -r ~/hadoop [email protected]:~/
(12):对DataWorks.Master的hdfs进行格式化,也即在DataWorks.Master虚拟机下面执行命令:
~/hadoop/bin/hdfs namenode -format
(13):启动HDFS,执行命令:~/hadoop/sbin/start-dfs.sh,执行结束之后,输入jps,在DataWorks.Master上执行jps输出如下:

在DataWorks.Node1和DataWorks.Node2以及DataWorks.client上执行jps,输出结果如下:
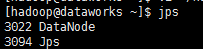
如果想要停止HDFS服务,可以执行:~/hadoop/sbin/stop-dfs.sh
(14):启动YARN,YARN是一个资源管理、任务调度的框架,主要包括三大模块,ResourceManager、NodeManager以及ApplicationManager
在DataWorks.Master上执行命令:~/hadoop/sbin/start-yarn.sh,在DataWorks.Master上执行jps出现ResourceManager,在DataWorks.Node1和DataWorks.Node2以及DataWorks.client上执行jps出现NodeManager表示yarn启动成功
如果想要停止YARN服务,可以执行~/hadoop/sbin/stop-yarn.sh
(15):执行hadoop dfsadmin -report命令能够查看详细的启动信息,如果在执行该命令的时候,出现下面错误bash: hadoop: command not found,具体解决方法是:http://blog.csdn.net/wang_zhenwei/article/details/50534684,执行下面命令:
vi /etc/profile
export HADOOP_HOME=/home//hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
在执行完hadoop dfsadmin -report之后,如果出现下面输出,就表示你的hadoop集群已经搭建起来了
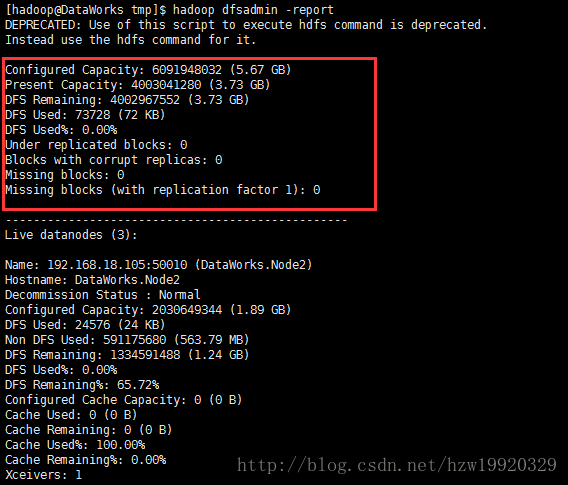
安装过程中可能出现的问题
问题1:如果在Master主机上执行jps的时候,没找到namenode节点,解决方法参考:http://blog.csdn.net/bychjzh/article/details/7830508
原因在于:问题出在了tmp文件夹,我们只需要重新生成该文件夹下面的内容即可,执行下面几条命令
①删除tmp文件夹下的内容:rm -rf ~/hadoop/tmp
② 对HDFS进行格式化:~/hadoop/bin/hdfs namenode -format
③登录Node1、Node2以及client主机,同样执行:rm -rf ~/hadoop/tmp
④在Master主机上执行:
scp -r ~/hadoop/tmp [email protected]:~/hadoop/tmp
scp -r ~/hadoop/tmp [email protected]:~/hadoop/tmp
scp -r ~/hadoop/tmp [email protected]:~/hadoop/tmp问题2:如果在Node1、Node2以及client上执行jps的时候,没找到datenode节点,解决方法参考:
https://www.cnblogs.com/kingatnuaa/p/4592989.html问题3:如果在执行hadoop dfsadmin -report命令之后,出现下面错误提示:

原因在于:防火墙拒绝了你的请求,我们需要关闭防火墙,具体解决措施是:
①切换到root用户下:su root
②关闭防火墙:service iptables stop问题4:出问题了一定要看log日志,hadoop的日志存储位置为:~/hadoop/logs下面
12. 在eclipse下配置hadoop插件
为了便捷的开发MapReduce程序,通常我们都是在eclipse开发好程序,打包成jar包发布到服务器上运行hadoop程序的
找到eclipse的安装路径,找到路径下的plugins文件夹,将hadoop-eclipse-plugin-2.7.1.jar文件夹移动到该文件夹下
在eclipse下new的时候,就会出现下面界面
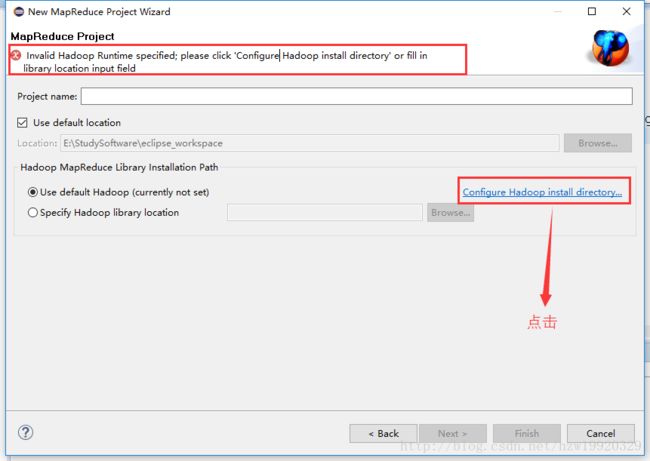
创建MapReduce项目,会出现下面界面,点击图中标示部分,选择你的hadoop-2.7.5存储路径
13. 开发编译并运行第一个MapReduce程序
①在eclipse下创建一个HadoopTest工程并在其中创建WordCount类,其内容如下:
package com.hzw.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//map方法,划分一行文本,读一个单词写出一个<单词,1>
public void map(Object key, Text value, Context context)throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);//写出<单词,1>
}}}
//定义reduce类,对相同的单词,把它们中的VList值全部相加
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();//相当于,将两个1相加 ,K类型
job.setMapOutputValueClass(IntWritable.class); //指定Map类输出的,V类型
job.setPartitionerClass(HashPartitioner.class); //指定使用默认的HashPartitioner类
job.setReducerClass(IntSumReducer.class); //指定使用上述自定义Reduce类
job.setNumReduceTasks(Integer.parseInt(args[2])); //指定Reduce个数
job.setOutputKeyClass(Text.class); //指定Reduce类输出的,K类型
job.setOutputValueClass(Text.class); //指定Reduce类输出的,V类型
job.setOutputFormatClass(TextOutputFormat.class); //指定使用默认输出格式类
TextOutputFormat.setOutputPath(job, new Path(args[1])); //设置输出结果文件位置
System.exit(job.waitForCompletion(true) ? 0 : 1); //提交任务并监控任务状态
}
} ②将HadoopTest工程export成jar包,方法是:右键HadoopTest工程,选择export,打开下面选项卡:
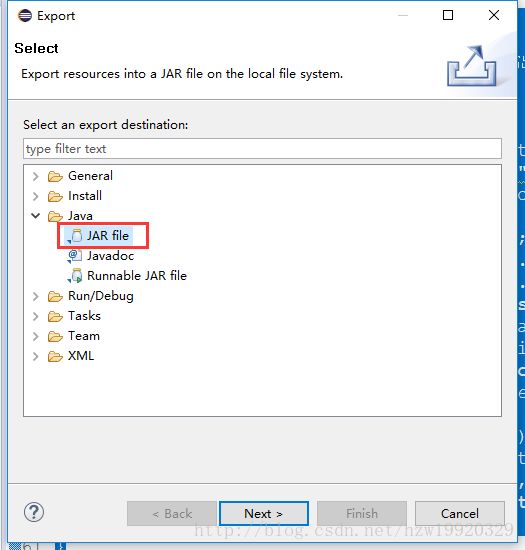
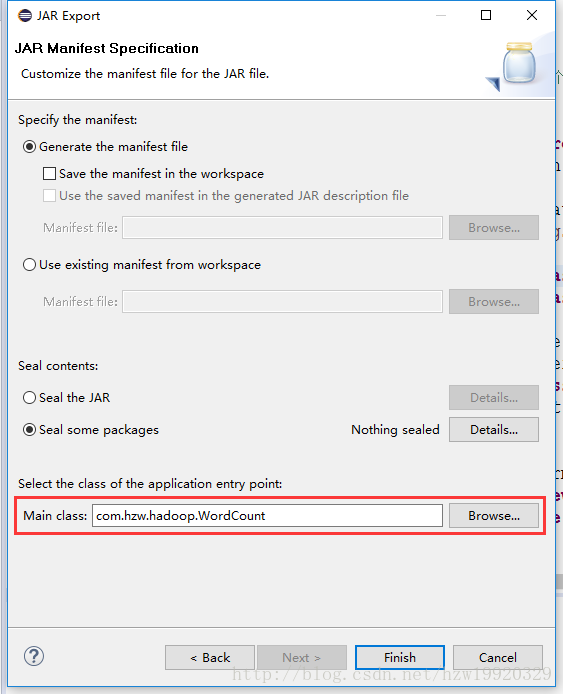
选择Next导出即可,注意在后面Next的过程中会出现下面界面,记得一定要选好你想要的main函数的入口位置:
③将创建成功的WordCount.jar文件通过WinSCP上传到DataWorks.client主机上,我上传的目录为/home/hadoop/hadoop/jarfile,jarfile文件夹是新建的
④在/home/hadoop/hadoop/下创建inputdata以及outputdata目录,在inputdata与outputdata目录下分别创建wordcount目录,在inputdata/wordcount目录下创建wordcount.txt文件,里面写入下面信息
hello hadoop
hello World
Hello Java
Hey man
i am a programmer
⑤在DataWorks.client上上传数据到hdfs上,首先需要在hdfs上创建存储文件的目录,分别执行下面命令:
~/hadoop/bin/hadoop fs -mkdir /hadoop/
~/hadoop/bin/hadoop fs -mkdir /hadoop/inputdata/
~/hadoop/bin/hadoop fs -mkdir /hadoop/inputdata/wordcount
接着执行命令:~/hadoop/bin/hadoop fs -put /home/hadoop/hadoop/inputdata/wordcount/wordcount.txt /hadoop/inputdata/wordcount,该命令将数据上传到hdfs的/hadoop/inputdata/wordcount路径下
接着不论是在哪台虚拟机上执行:~/hadoop/bin/hadoop fs -ls /hadoop/inputdata/wordcount命令,可以发现wordcount.txt已经上传到hdfs上啦,
⑥创建MapReduce程序输出文件的路径,执行下面命令:
~/hadoop/bin/hadoop fs -mkdir /hadoop/outputdata/
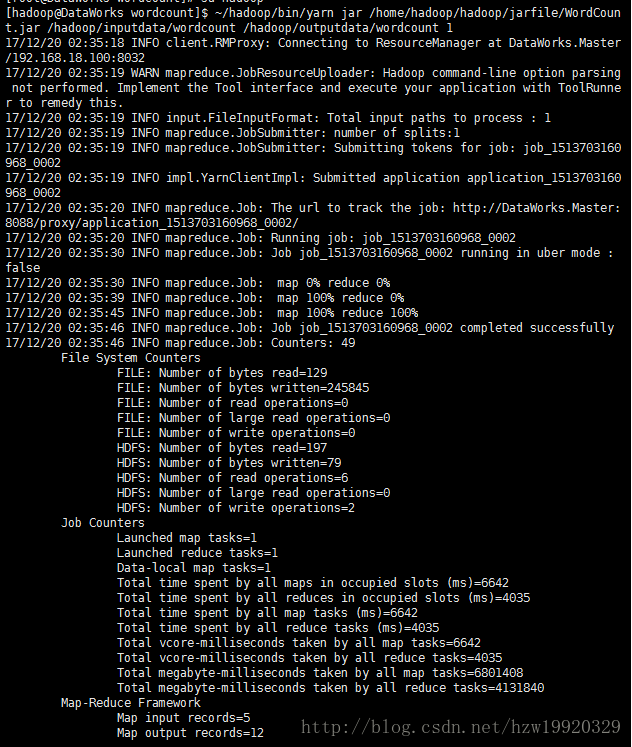
⑦执行命令:~/hadoop/bin/yarn jar /home/hadoop/hadoop/jarfile/WordCount.jar /hadoop/inputdata/wordcount /hadoop/outputdata/wordcount 1,第三个参数1表示reducer的个数,出现类似下面输出表示执行结束:
⑧ 通过命令~/hadoop/bin/hadoop fs -ls /hadoop/outputdata/wordcount,可以看到有下面输出结果:
其中的part-r-00000就是我们的输出结果文件,可以通过命令(这个命令可以在任意一台集群的机器上执行都会得到相同的结果)~/hadoop/bin/hadoop fs -cat /hadoop/outputdata/wordcount/part-r-00000查看文件的具体内容,输出结果如下:

到此,已经能够正确的运行一个简单的MapReduce程序啦。
安装过程中可能出现的问题
问题1:出现下面错误信息
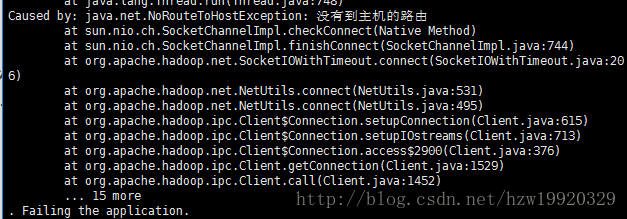
错误原因:因为client主机的防火墙没关闭
解决方法:su root到root用户下,执行service iptables status查看防火墙状态,接着执行service iptables stop关闭防火墙,再执行chkconfig iptables off 命令,保证开机不启动防火墙即可
问题2:你可以通过浏览器监控的方式来查看MapReduce的执行过程,具体来讲就是在浏览器中输入http://192.168.18.100:8088/
输出结果如下:
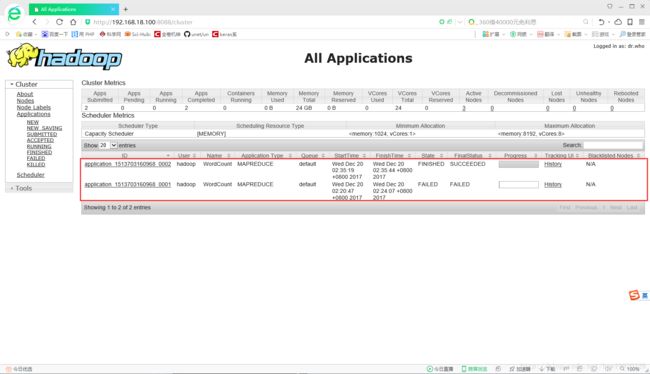
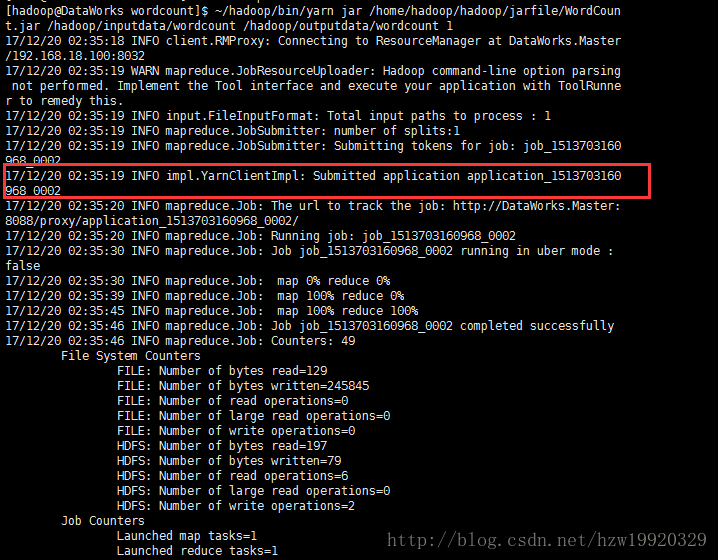
其中的IP地址:192.168.18.100表示hadoop集群中Master主机的IP,其中红色框住部分的application_ID中的id值来源于你在执行~/hadoop/bin/yarn jar /home/hadoop/hadoop/jarfile/WordCount.jar /hadoop/inputdata/wordcount /hadoop/outputdata/wordcount 1命令时的输出,我们可以从下面截图中看到:
问题3:通过浏览器查看hdfs文件的方法参考:http://blog.csdn.net/Haiyang_Duan/article/details/53287973
14. 进阶例子:环境大数据
任务:从北京市2016年1-6月这半年间的历史天气和空气质量数据文件中分析出环境统计结果,包括月平均气温、空气质量分布情况等等,利用MapReduce来统计月度平均气温和半年内空气质量为优、良、轻度污染、中度污染、重度污染和严重污染的天数
步骤如下:
在保证hdfs以及yarn启动的情况下进行下面步骤
①通过WinSCP上传环境质量数据到client主机上
②上传数据到hdfs上,首先创建文件夹,执行命令:~/hadoop/bin/hadoop fs -mkdir /hadoop/inputdata/enviroment,上传文件执行命令:~/hadoop/bin/hadoop fs -put /home/hadoop/hadoop/inputdata/enviroment/beijing.txt /hadoop/inputdata/enviroment,在执行这个命令的时候,可能会出现下面错误:

解决方法是:执行~/hadoop/bin/hadoop dfsadmin -safemode leave命令关掉datanode的safe mode安全模式即可。
③ 在eclipse下编写平均气温统计程序,代码如下:
package com.hzw.hadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class TemperatureMean{
public static class StatMapper extends Mapper
{
private IntWritable intValue = new IntWritable();
private Text dateKey = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
{
String[] items = value.toString().split(",");
String date = items[0];
String tmp = items[5];
if(!"DATE".equals(date) && !"N/A".equals(tmp))
{//排除第一行说明以及未取到数据的行
dateKey.set(date.substring(0, 6));
intValue.set(Integer.parseInt(tmp));
context.write(dateKey, intValue);
}
}
}
public static class StatReducer extends Reducer{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException
{
int tmp_sum = 0;
int count = 0;
for(IntWritable val : values)
{
tmp_sum += val.get();
count++;
}
int tmp_avg = tmp_sum/count;
result.set(tmp_avg);
context.write(key, result);
}
}
public static void main(String args[])
throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = new Configuration();
Job job = new Job(conf, "MonthlyAvgTmpStat");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job, args[0]);
job.setJarByClass(TemperatureMean.class);
job.setMapperClass(StatMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(StatReducer.class);
job.setNumReduceTasks(Integer.parseInt(args[2]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
④ 将项目export成.jar文件,并将其通过winSCP上传到client主机上,具体上传到的目录是:/home/hadoop/hadoop/jarfile
⑤在hadoop上执行.jar文件,执行命令:~/hadoop/bin/yarn jar /home/hadoop/hadoop/jarfile/TemperatureMean.jar /hadoop/inputdata/enviroment /hadoop/outputdata/enviroment 1
⑥执行~/hadoop/bin/hadoop fs -ls /hadoop/outputdata/enviroment查看程序输出文件。输出结果如下:

⑦执行~/hadoop/bin/hadoop fs -cat /hadoop/outputdata/enviroment/part-r-00000,输出结果见下:
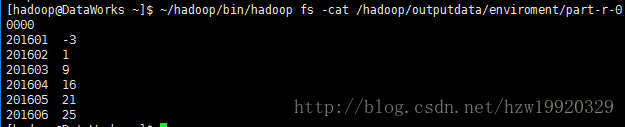
输出结果第一列表示时间,第二列表示当月的平均气温
15. 安装并配置scala(每台虚拟机)
因为spark是由scala实现的,因此需要首先安装scala
(1):首先执行:wget -c https://downloads.lightbend.com/scala/2.10.6/scala-2.10.6.tgz
下载安装包
(2):解压scala,执行命令:tar -zxvf scala-2.10.6.tgz
(3):重命名scala目录:mv scala-2.10.6 scala
(4):将scala添加到环境变量中,首先切换到root用户下,接着执行下面命令:vi /etc/profile,在profile文件中添加下面代码:在$PATH中添加:/home/hadoop/scala/bin,添加结束之后,执行source /etc/profile使得环境变量生效
(5):执行scala,如果出现下面输出,表示scala安装成功

16. 安装并配置spark(每台虚拟机)
(1):下载不包含hadoop的spark,执行命令:wget -c https://d3kbcqa49mib13.cloudfront.net/spark-1.6.3-bin-without-hadoop.tgz
(2):解压spark,执行命令:tar -zxvf spark-1.6.3-bin-without-hadoop.tgz
(3):重命名spark,执行命令:mv spark-1.6.3-bin-without-hadoop spark
(4):为spark设置环境变量,su root切换到root用户下,执行vi /etc/profile,在其中的$PATH中添加下面内容:/home/hadoop/spark/bin:/home/hadoop/spark/sbin,source /etc/profile使得环境变量生效
(5):复制一份spark-env.sh.template,执行命令:cp /home/hadoop/spark/conf/spark-env.sh.template /home/hadoop/spark/conf/spark-env.sh,编辑spark-env.sh,执行命令:vi /home/hadoop/spark/conf/spark-env.sh,在spark-env.sh的末尾添加下面内容:
export SPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop/bin/hadoop classpath)
export SCALA_HOME=/home/hadoop/scala
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.161.x86_64
export SPARK_MASTER=192.168.18.100
export SPARK_WORKER_MERMORY=512m
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
(6):复制一份slaves.template,执行命令cp /home/hadoop/spark/conf/slaves.template /home/hadoop/spark/conf/slaves,编辑slaves,执行命令:vi /home/hadoop/spark/conf/slaves,在其中添加下面内容:
DataWorks.Node1
DataWorks.Node2
DataWorks.client
(7):运行spark实例,在 /home/hadoop/spark/examples/src/main 目录下有一些 Spark 的示例程序,有 Scala、Java、Python、R 等语言的版本。我们可以先运行一个示例程序 SparkPi(即计算 π 的近似值),执行如下命令:
/home/hadoop/spark/bin/run-example SparkPi 2>&1 | grep “Pi is roughly”,如果输出下面结果,表示单机版spark安装完毕

(8):spark分布式集群搭建
①在Master主机上执行:/home/hadoop/spark/sbin/start-master.sh,在Master上执行jps会发现多了一个名为Master的进程
②在Node1,Node2或者client上执行:/home/hadoop/spark/sbin/start-slaves.sh,在Node1、Node2以及client上执行jps会发现多了一个名为Worker的进程
(9):至此,spark集群已经部署完毕,如果你想要关掉集群,可以执行下面命令:
①在Master主机上执行:/home/hadoop/spark/sbin/stop-master.sh,在Master上执行jps会发现Master进程已经不见了
②在Node1,Node2或者client上执行:/home/hadoop/spark/sbin/stop-slaves.sh,在Node1、Node2以及client上执行jps会发现Worker进程也不见了
17. spark入门应用举例,单词计数
(1):首先上传wordcount.txt数据到hdfs上,之前通过MapReduce统计单词个数的时候,我们已经上传过wordcount.txt文件了,在此我们直接用即可
(2):注意在执行这一步骤之前,记得一定要保证你的Node1、Node2以及client上的Worker进程已经启动,启动spark-shell,在client上执行下面命令即可:/home/hadoop/spark/bin/spark-shell –master spark://DataWorks.Master:7077 –executor-memory 256m –total-executor-cores 3 –executor-cores 1,进入之后,出现下面界面表示启动成功:

(3):在其中分别输入下面内容
val file=sc.textFile(“hdfs://DataWorks.Master:9000/hadoop/inputdata/wordcount/wordcount.txt”)
val count=file.flatMap(line => line.split(” “)).map(word => (word,1)).reduceByKey(+)
count.collect()
(4):输出单词统计数表示运行成功