Scrapy爬简书【女神米仓凉子】搜索图片
环境:
IDE:pycharm、python:3.5、Scrapy
python3.x和Twisted不兼容,只能单独下载Twisted进行安装。以win10+64+python3.5为例下载。标识cp35:python3.5
Twisted下载地址

放在python3.5安装目录E:\Applications\Python,Pycharm terminal切换到E:\Applications\Python
1、pip install Twisted-18.4.0-cp35-cp35m-win_amd64.whl
2、pip install scrapy
使用Scrapy命令创建项目 (shift+鼠标右键)打开终端(windows powershell)
scrapy startproject scrapyTest
错误:ImportError: No module named ‘win32api’
下载安装pywin32
这里注意求情方式
当前爬去几页,没有爬取大量图片。翻页注意参数
import scrapy
import json
from scrapy.http import Request
from testScrapy.items import JianshuPic
from testScrapy.items import JianshuItem
class TestJianshu4(scrapy.Spider):
name = 'jianshu23'
allowed_domains = ['jianshu.com']
base_url = 'https://www.jianshu.com/search?q=米仓凉子&type=note&page=1'
next_url = 'https://www.jianshu.com/search/do?'
start_urls = [base_url]
showDetailUrl ='https://www.jianshu.com/p/'
headers = {
'Accept': 'application/json',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '0',
'Cookie': 'read_mode=day; default_font=font2; locale=zh-CN; _m7e_session=458bfff7155710101760129497cd6e82; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216208b5086e465-0d2fb6ab77b01b-3b60450b-1049088-16208b5087064e%22%2C%22%24device_id%22%3A%2216208b5086e465-0d2fb6ab77b01b-3b60450b-1049088-16208b5087064e%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_utm_source%22%3A%22desktop%22%2C%22%24latest_utm_medium%22%3A%22index-banner-s%22%7D%7D; Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1530491510,1530491596,1530493283,1530493479; Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1530497542; signin_redirect=https%3A%2F%2Fwww.jianshu.com%2Fsearch%3Fq%3D%25E7%25B1%25B3%25E4%25BB%2593%25E5%2587%2589%25E5%25AD%2590%26page%3D1%26type%3Dnote',
'Host': 'www.jianshu.com',
'Origin': 'https://www.jianshu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
'X-CSRF-Token': 'OqYI0/owqbkGf2Er2jZNGNrKf1A7ZodbD4QJIBbGorWklNI50+ERjrM6HTWwx8PrqwtYI1qXL9ONyqS5FHAT3g==',
'Referer': base_url
}
headers2 = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# 'Content-Length': '0',
'Cookie': 'read_mode=day; default_font=font2; locale=zh-CN; Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1530500933,1530501037,1530501061,1530576964; _m7e_session=6c4e3e2994d689631707353462150e5d; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216208b5086e465-0d2fb6ab77b01b-3b60450b-1049088-16208b5087064e%22%2C%22%24device_id%22%3A%2216208b5086e465-0d2fb6ab77b01b-3b60450b-1049088-16208b5087064e%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_utm_source%22%3A%22desktop%22%2C%22%24latest_utm_medium%22%3A%22search-trending%22%7D%7D; signin_redirect=https%3A%2F%2Fwww.jianshu.com%2Fsearch%3Futf8%3D%25E2%259C%2593%26q%3D%25E4%25B8%2596%25E7%2595%258C%25E6%259D%25AF; Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1530577479',
'Host': 'www.jianshu.com',
# 'Origin': 'https://www.jianshu.com',
'If-None-Match':'W/"768c2605b207f5e820729965c3e77a5a"',
'Referer': base_url,
'Upgrade-Insecure-Requests':'1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
# 'X-CSRF-Token': 'OqYI0/owqbkGf2Er2jZNGNrKf1A7ZodbD4QJIBbGorWklNI50+ERjrM6HTWwx8PrqwtYI1qXL9ONyqS5FHAT3g==',
}
formdata = {
'q': '米仓凉子',
'type': 'note',
'page': '1',
'order_by': 'default'
}
def __init__(self):
self.count = 1
def start_requests(self):
return [Request(self.base_url, callback=self.parse_Item, headers=self.headers2)]
def parse_Search(self,response):
self.count += 1
js = json.loads(response.body.decode('utf-8'))
sizeEntries = len(js['entries'])
for sel in js['entries']:
item = JianshuItem()
# print(sel['content'].encode("gbk", 'ignore').decode("gbk", "ignore"))
item['refresh_url'] = sel['slug']
print(sel['slug'])
yield scrapy.Request(self.showDetailUrl+item['refresh_url'],callback=self.search_Details)
yield item
now_page = js['page']
print(now_page)
self.formdata['page'] = str(self.count)
self.base_url = 'https://www.jianshu.com/search?q=米仓凉子&type=note&page=' + str(self.count - 1)
self.headers['Referer'] = self.base_url
# if self.count <= 5:
# print(self.formdata)
# print(self.base_url)
# yield scrapy.FormRequest(self.next_url, callback=self.parse_Search, headers=self.headers,
# formdata=self.formdata)
def parse_Item(self, response):
# js = json.loads(str(response.body))
divApp = response.xpath("//div[@id='app']")
yield scrapy.FormRequest(self.next_url,callback=self.parse_Search,headers=self.headers,formdata=self.formdata)
def search_Details(self,response):
self.log('开始进入爬去图片 from %s' %response.url)
print('============================================')
# print(response.body.decode('utf-8'))
print(response.xpath("/html/body/div[1]/div[1]/div[1]/h1"))
img_urls = []
for sel in response.xpath("//div[@class='show-content-free']/p"):
print(sel)
for sel3 in response.xpath("//div[@class='image-view']/img"):
itemJian = JianshuPic()
imgUrl ='https:'+sel3.xpath("./@data-original-src").extract()[0]
img_urls.append(imgUrl)
print(imgUrl)
itemJian['image_url'] = img_urls
yield itemJian爬去过程中遇到各种奇葩的错误,在此记录下
错误1、关于403解决方案
scrapy shell -s user_agent=’Mozilla/5.0’ https://www.jianshu.com
scrapy shell -s user_agent=’Mozilla/5.0’ https://www.jianshu.com/p/46df1e8cd65f
错误2、把unicode转行成utf-8
raise TypeError(‘Request url must be str or unicode, got %s:’ % type(url).name)
newUrl.decode(‘utf-8’)
‘str’ object has no attribute ‘string’
错误3、UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xa0’ in position 0: illegal multibyte
self.file.write(content.encode(“gbk”, ‘ignore’).decode(“gbk”, “ignore”))
错误4、scrapy does not support field:
错误:title =scrapy.field
正确:title =scrapy.Field()
错误6、【406】’bytes’ object is not callable 在setting文件设置
HTTPERROR_ALLOWED_CODES = [406]
错误7、the JSON object must be str, not ‘bytes’
转换:response.body.decode(‘utf-8’)
错误8、scrapy 爬虫 搜索过于频繁
DOWNLOAD_DELAY 设置延迟时间:
DOWNLOAD_DELAY = 5
错误9、No module named ‘PIL’
pillow下载地址
pip install Pillow-5.2.0-cp35-cp35m-win_amd64
错误11、TypeError: ‘ItemMeta’ object does not support item assignment
错误:il = ItemLoader(item=Product)
正确:il = ItemLoader(item=Product())
关于Pipeline:
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
scrapy shell ‘http://scrapy.org’ –nolog
错误12、dictionary update sequence element #0 has length 1; 2 is required
写入的json格式{‘name’:[”]}
或者 {‘name’:”}
错误13、a bytes-like object is required, not ‘str’
写入json是字符串 转行
line = json.dumps(dict(it))+’\n’
print(line.encode())
爬取的结果,参考一些网上文章。
兴趣是第一学习动力
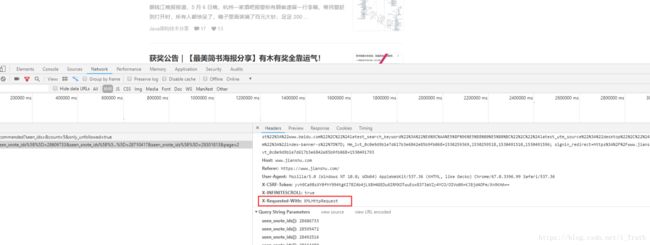
一定要注意请求方式请:求头是xmlRequest 需要设置headers属性
‘X-Requested-With’:’XMLHttpRequest’
分析过wb结构,不敢拿自己的号试