用深度强化学习玩贪食蛇
文章同步发于公众号:1024程序开发者社区(cxkfzsq1024)
1024程序开发者社区博客
前期发布了两篇文章,分别介绍了贪食蛇游戏搭建和通过算法玩贪食蛇两篇文章:
Python:游戏:贪吃蛇
如何用AI玩贪食蛇?
本文将分三个部分,介绍用深度强化学习玩贪食蛇。
一、模型搭建
关于深度强化学习的发展和算法原理,在下文中进行了具体介绍:
如何训练AI玩飞机大战游戏
简而言之,深度强化学习模型在强化学习框架基础上,将感知环境的部分用CNN卷积神经网络进行构建(其中也包含部分图像特征提取的手段)。
这也是当前游戏AI发展的趋势,因为游戏复杂度越来越高,单纯的建模过于复杂。比较典型的代表就是:AlphaGo、星际争霸AI等。
基于此构建的模型框架为:
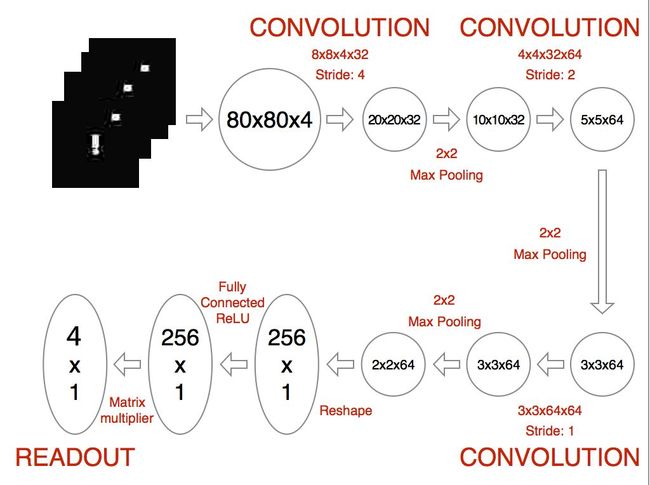
将游戏的决策频率确定为每前进一个单元格进行一次决策,动作分为:前后左右四种。
核心程序代码为:
while 1!= 0:
action = brain.getAction()
nextObservation,reward,terminal = snake.frame_step(action)
nextObservation = preprocess(nextObservation)
brain.setPerception(nextObservation,action,reward,terminal)
模型运行流程为:
①在当前状态下获取最优动作;
②游戏空间中运行该动作,获得reward和动作后的场景;
③对nextObservation进行图像处理;
④得到数据对神经网络进行训练。
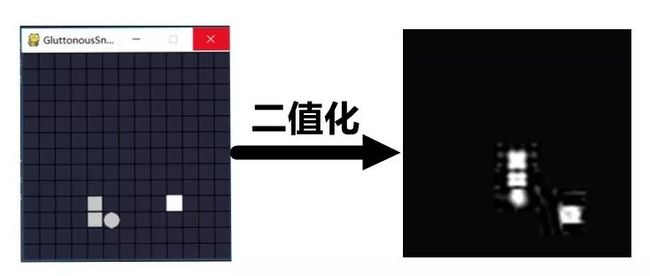
其中,本模型采用二值化(图片只是举例,不是对应时刻的两张):
reward函数定义时决定模型收敛速度的决定因素,模型设置了两种模式:
(1)固定回报值

(2)基于蛇头和食物之间距离的回报,离食物越近回报越高。
dis = (math.sqrt(pow((self.food[0]-next_s[0]),2)+pow((self.food[1]-next_s[1]),2)))
reward = (1/dis)*0.5
为使模型更大限度的探索不同动作空间,在动作选择get_action()函数中加入随机参数epsilon = 0.1(初始),一定概率的产生随机动作:
def getAction(self):
QValue = self.QValue.eval(feed_dict= {self.stateInput:[self.currentState]})[0]
action = np.zeros(self.actions)
action_index = 0 if self.timeStep % FRAME_PER_ACTION == 0:
if random.random() <= self.epsilon:
action_index = random.randrange(self.actions)
action[action_index] = 1 else:
action_index = np.argmax(QValue)
action[action_index] = 1 else:
action[0] = 1 # do nothing
# change episilon if self.epsilon > FINAL_EPSILON and self.timeStep > OBSERVE:
self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON)/EXPLORE
return action
其余部分可以具体看代码。
该模型优点是适应性强,对游戏规则不用过多建模,也就是任何一款游戏都可以用这个方法;
缺点是训练消耗大,硬件要求高。
二、游戏环境修改
模型中使用的游戏环境基础是丹枫无迹大哥的贪食蛇代码,根据模型需要进行了简化修改。
(1)为保持图像输入尽量少的干扰因素,将成绩和速度栏取消;
(2)为减小动作空间,将原游戏3022的单元格,缩减为1212;
(3)将蛇头和食物修改为圆的,为了使核心部分更具有特点;
(4)为加强吃到食物和死亡时游戏界面的特点,吃到食物时刻不立即产生新食物,死亡时会产生GameOver的界面;

整个游戏运行在snake.frame_step(action)中:
def frame_step(self,input_actions):
terminal = False
reward = 0.1
# 检测输入正确性
if input_actions[0] == 1 or input_actions[1]== 1 or input_actions[2]== 1 or input_actions[3] == 1: # 检查输入正常
if input_actions[0] == 1 and input_actions[1] == 0 and input_actions[2] == 0 and input_actions[3] == 0 and self.pos != (0,1):
# 向上
self.pos = (0, -1)
elif input_actions[0] == 0 and input_actions[1] == 1 and input_actions[2] == 0 and input_actions[3] == 0 and self.pos != (0,-1):
#向下
self.pos = (0, 1)
elif input_actions[0] == 0 and input_actions[1] == 0 and input_actions[2] == 1 and input_actions[3] == 0 and self.pos != (1,0):
#向左
self.pos = (-1, 0)
elif input_actions[0] == 0 and input_actions[1] == 0 and input_actions[2] == 0 and input_actions[3] == 1 and self.pos != (-1,0):
#向右
self.pos = (1, 0)
else:
pass
else:
raise ValueError('Multiple input actions!')
# 填充背景色
self.screen.fill(BGCOLOR)
# 画网格线 竖线
for x in range(SIZE, SCREEN_WIDTH, SIZE):
pygame.draw.line(self.screen, BLACK, (x, SCOPE_Y[0] * SIZE), (x, SCREEN_HEIGHT), LINE_WIDTH)
# 画网格线 横线
for y in range(SCOPE_Y[0] * SIZE, SCREEN_HEIGHT, SIZE):
pygame.draw.line(self.screen, BLACK, (0, y), (SCREEN_WIDTH, y), LINE_WIDTH)
next_s = (self.snake[0][0] + self.pos[0], self.snake[0][1] + self.pos[1])
if next_s == self.food:
# 吃到了食物
self.snake.appendleft(next_s)
self.score += self.food_style[0]
self.food = create_food(self.snake)
self.food_style = get_food_style()
reward = 1
else:
if SCOPE_X[0] <= next_s[0] <= SCOPE_X[1] and SCOPE_Y[0] <= next_s[1] <= SCOPE_Y[1] \
and next_s not in self.snake:
self.snake.appendleft(next_s)
self.snake.pop()
#通过距离定义reward # dis = (math.sqrt(pow((self.food[0]-next_s[0]),2)+pow((self.food[1]-next_s[1]),2))) # reward = (1/dis)*0.5 else:
reward = -1 #死亡惩罚
terminal = True
self.__init__()
print('score:%u' % self.score)
if terminal ==True:
font2 = pygame.font.Font(None,50 )# GAME OVER 的字体
fwidth, fheight = font2.size('GAME OVER')
print_text(self.screen, font2, (SCREEN_WIDTH - fwidth) // 2, (SCREEN_HEIGHT - fheight) // 2, 'GAME OVER', RED)
else:
# 画食物
if reward != 1:
pygame.draw.circle(self.screen, DARK,
(self.food[0] * SIZE + LINE_WIDTH + 10, self.food[1] * SIZE + LINE_WIDTH + 10), 10,
0)
# 画蛇
flag = 0
for s in self.snake:
if flag == 0:
pygame.draw.circle(self.screen, DARK, (s[0] * SIZE + LINE_WIDTH+10, s[1] * SIZE + LINE_WIDTH+10),10, 0)
flag = 1
else:
pygame.draw.rect(self.screen, DARK, (s[0] * SIZE + LINE_WIDTH, s[1] * SIZE + LINE_WIDTH,
SIZE - LINE_WIDTH * 2, SIZE - LINE_WIDTH * 2), 0)
image_data = pygame.surfarray.array3d(pygame.display.get_surface())
pygame.display.update()
clock = pygame.time.Clock()
clock.tick(90)
return image_data, reward, terminal,self.score
三、模型训练和效果
模型训练300W次后最优成绩达到15,在12*12的游戏空间中已经是条挺长的蛇了。

随着训练的进一步加深,效果肯定会更好。
训练过程如下:
通过视频可以看出,蛇基本上已经学会自保,但是对食物的兴趣还不够高,这也是下一步改进的方向。
总结一下,模型实现了从环境数据获取,模型训练的全过程,构建了可以用于移植的完整模型。
但还有很多需要改进的地方,比如模型的收敛速度。
关注公众号,回复【DQN贪食蛇】获取源代码。

1024程序开发者社区的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里就技术问题进行交流,还没有加入的小伙伴可以扫描下方“社区物业”二维码,让管理员帮忙拉进群,期待大家的加入。

//猜你喜欢//
-
Django+xadmin打造在线考试系统(一)
-
Django+uwsgi+nginx(Ubuntu:16.4)项目部署
-
《解忧杂货店》豆瓣书评爬取和情感分析初探
-
用Hexo+Github 搭建属于自己的博客(一)
-
用Hexo+Github 搭建属于自己的博客(二)
-
如何用AI玩贪食蛇?