hive之union、union all的列名不统一的记录
在MySQL中,union和union all中,只需要列的数量对应,这样就可以完成union和union all操作。
但是在hive中,我也是这样想的,于是,我并没有关注列名必须一致,只是关注了列数量一致,这样的话,其实也是可以的,比如:
--不同渠道的目标客户量
select 'sources' as type,sources as type_detail,count(*) as count
from dw_release.dw_release_customer
where bdp_day = '20190619' group by bdp_day,sources
union
--不同区域的目标客户量
select 'area_code',area_code as type_detail_code,count(*) as count
from dw_release.dw_release_customer
where bdp_day = '20190619' group by bdp_day,area_code发现是没有问题的:
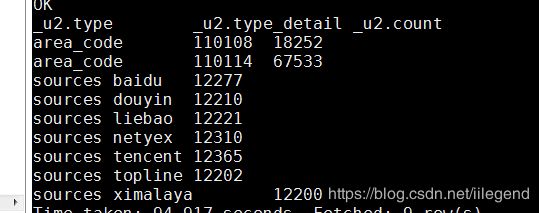
但是!!!我发现有一次在官网上!!
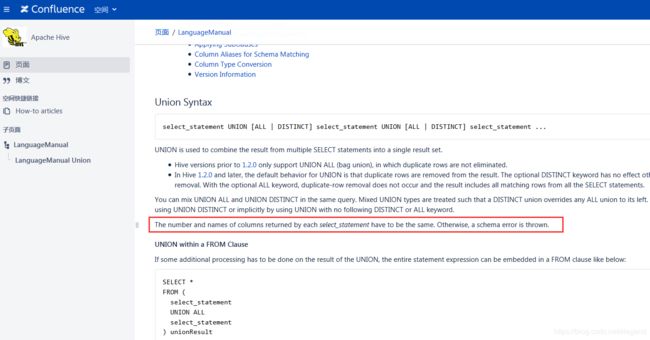
有一句话是:
The number and names of columns returned by each select_statement have to be the same. Otherwise, a schema error is thrown.每个select语句返回的列数和名称必须相同。否则,将引发架构错误。
我就纳闷了!官网是这样严谨的!! 注意这个词 : have to be the same. 必须一致
但是为什么可以不用相同的列名称呐 ?
然后官网还有这句话:
![]()
要求表达式列表的两边都有相同的架构。因此,以下查询可能会失败,并显示错误消息,如 “FAILED: SemanticException 4:47 Schema of both sides of union should match.”
INSERT OVERWRITE TABLE target_table
SELECT name, id, category FROM source_table_1
UNION ALL
SELECT name, id, "Category159" FROM source_table_2是有可能发生错误的!注意官网的用词 may fail
对,是有可能发生错误的。
在工作中也是有可能出现错误的,但是几率很小,尤其是 直接一个写死的字符串直接作为一个列的时候。
总结::
从此以后,我追随官网的脚步!
但是,虽然我们要严格遵守官网的规范,但是还是对此有些疑问的,因为“必须一致”,“可能发生错误”这种词并不具备严谨性
其实还是希望官网把这个问题能更严谨一下,不知道我说的对不对,特此记录一下,然后我以后写SQL,为了避免不该有的、未知的错误,我还是老老实实写一样的列名吧。
以后我写代码就是:
比如:
SELECT name, id, category FROM source_table_1
UNION ALL
SELECT name, id, "Category159" as category FROM source_table_2--不同渠道的目标客户量
select 'sources' as type,sources as type_detail,count(*) as count
from dw_release.dw_release_customer
where bdp_day = '20190619' group by bdp_day,sources
union
--不同区域的目标客户量
select 'area_code' as type,area_code as type_detail_code,count(*) as count
from dw_release.dw_release_customer
where bdp_day = '20190619' group by bdp_day,area_code