sparkmllib 特征抽取、特征转换及特征选择
特征抽取
- TF-IDF
TF-IDF一般应用于文本挖掘中,用来反映一个特征项的重要性。设特征项为 t,文档为d,文档集为D。特征频率( term frequency)TF(t,d) 为特征项在文档d中出现在次数。 文档频率(document frequency)DF(t,D)表示含特征项t的文档数。如果只是用tf来衡量重要性,那么对于一遍文档中出现多次但含信息量极少来说是没什么用处的。因此可以用逆文档频率IDF(Inverse document frequency )来衡量特征项的重要性,公式如下:
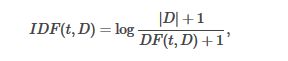
|D|表示文档总数,显然如果t出现在所有的文档中,那么idf的值为0。然后tf-idf为:
![]()
示例:
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
val sentenceData = spark.createDataFrame(Seq(
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
)).toDF("label", "sentence")
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsData = tokenizer.transform(sentenceData)
val hashingTF = new HashingTF()
.setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20)
val featurizedData = hashingTF.transform(wordsData)
// alternatively, CountVectorizer can also be used to get term frequency vectors
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
rescaledData.select("label", "features").show()- Word2Vec
Word2Vec使用每个词在文档中出现的概率代表这个词,然后整个文档是这些概率值组成的一个向量。它常被用来作文档相似性计算。
示例:
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// Input data: Each row is a bag of words from a sentence or document.
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)).toDF("text")
// Learn a mapping from words to Vectors.
val word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0)
val model = word2Vec.fit(documentDF)
val result = model.transform(documentDF)
result.collect().foreach { case Row(text: Seq[_], features: Vector) =>
println(s"Text: [${text.mkString(", ")}] => \nVector: $features\n") }特征转换
- n-gram
n-gram代表由n个字组成的句子。利用上下文中相邻词间的搭配信息,在需要把连续无空格的拼音、笔划,或代表字母或笔划的数字,转换成汉字串(即句子)时,可以计算出具有最大概率的句子,从而实现到汉字的自动转换,无需用户手动选择,避开了许多汉字对应一个相同的拼音(或笔划串,或数字串)的重码问题。该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
示例:
import org.apache.spark.ml.feature.NGram
val wordDataFrame = spark.createDataFrame(Seq(
(0, Array("Hi", "I", "heard", "about", "Spark")),
(1, Array("I", "wish", "Java", "could", "use", "case", "classes")),
(2, Array("Logistic", "regression", "models", "are", "neat"))
)).toDF("id", "words")
val ngram = new NGram().setN(2).setInputCol("words").setOutputCol("ngrams")
val ngramDataFrame = ngram.transform(wordDataFrame)
ngramDataFrame.select("ngrams").show(false)- 标准化
sparkmllib使用Normalizer类来进行标准化。可以指定p的值来进行标准化,p的默认值为2。
示例:
import org.apache.spark.ml.feature.Normalizer
import org.apache.spark.ml.linalg.Vectors
val dataFrame = spark.createDataFrame(Seq(
(0, Vectors.dense(1.0, 0.5, -1.0)),
(1, Vectors.dense(2.0, 1.0, 1.0)),
(2, Vectors.dense(4.0, 10.0, 2.0))
)).toDF("id", "features")
// Normalize each Vector using $L^1$ norm.
val normalizer = new Normalizer()
.setInputCol("features")
.setOutputCol("normFeatures")
.setP(1.0)
val l1NormData = normalizer.transform(dataFrame)
println("Normalized using L^1 norm")
l1NormData.show()
// Normalize each Vector using $L^\infty$ norm. infty范数
val lInfNormData = normalizer.transform(dataFrame, normalizer.p -> Double.PositiveInfinity)
println("Normalized using L^inf norm")
lInfNormData.show()特征选择
特征选择是从特征集合中选取一组子集。因为机器学习中特征太多,我们需要提取有用的特征。假如我们用个DataFrame:
userFeatures
------------------
[0.0, 10.0, 0.5]它第一列为0,因些没什么用需剔除。我们使用VectorSlicer 类的setIndices(1, 2)方法来进行特征提取。
userFeatures | features
------------------|-----------------------------
[0.0, 10.0, 0.5] | [10.0, 0.5]示例:
import java.util.Arrays
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute}
import org.apache.spark.ml.feature.VectorSlicer
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.StructType
val data = Arrays.asList(
Row(Vectors.sparse(3, Seq((0, -2.0), (1, 2.3)))),
Row(Vectors.dense(-2.0, 2.3, 0.0))
)
val defaultAttr = NumericAttribute.defaultAttr
val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName)
val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]])
val dataset = spark.createDataFrame(data, StructType(Array(attrGroup.toStructField())))
val slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setIndices(Array(1)).setNames(Array("f3"))
// or slicer.setIndices(Array(1, 2)), or slicer.setNames(Array("f2", "f3"))
val output = slicer.transform(dataset)
output.show(false)