Spark App自动化分析和故障诊断
陈泽,苏宁云商IT总部高级技术经理。苏宁云商大数据离线计算平台的计算方向负责人,目前主要从事Yarn,Hive,Spark,Druid等计算组件研发工作。曾就职于百度,有多年的Spark大数据方向的研发经验,精通Spark SQL,Druid等内核原理,有丰富的任务故障诊断和性能调优经验。
本文系陈泽老师在CCTC 2017 Spark技术峰会上所做的分享,点击下载演讲PPT。
非常高兴有机会可以代表我们团队在“CCTC 2017——Spark技术峰会”上给大家分享我们在Spark平台化上所做的一些工作,下面是分享的一些笔录。
苏宁大数据计算平台架构
苏宁大数据平台的计算引擎主要包括三个组成部分:离线计算、流式计算、OLAP引擎。
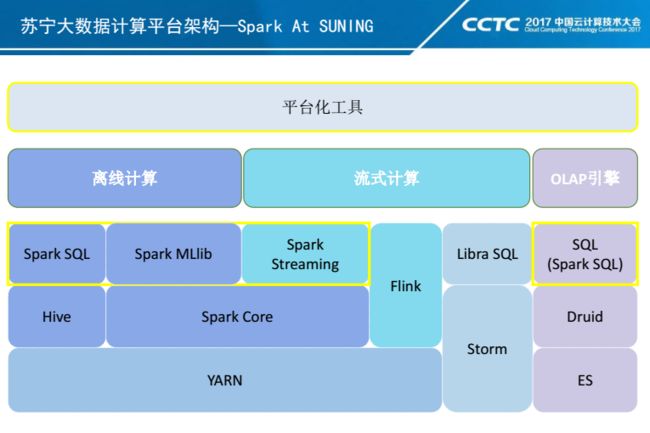
- 离线这块目前主要是依赖Spark和Hive来提供离线数据的分析和挖掘能力。
- 流式计算这块分为准实时计算和实时流计算。准实时计算主要基于Spark Streaming来满足数秒至分钟级的业务需求,对于实时流这块,目前我们苏宁大概有1200台Openstack虚拟机(400台实体机)组成的 39个Storm集群,并且在2014年就自研了Storm SQL引擎Libra,为Storm业务提供SQL接口。从今年年初开始,我们开始逐步去强化Flink在我们架构中的位置,我们希望利用Flink的强大窗口计算以及EventTime的处理能力来解决我们一些业务上的需求。
- OLAP这块目前我们主推Druid和ES两款引擎。我们利用Druid的实时计算能力,来解决我们指标聚合计算上的一些需求;利用ES快速数据索引定位能力来解决明细查询上的一些需求。
在我们整个架构中,Spark处于一个非常重要的位置。同时我们也为了Spark的平台化服务化,做了很多平台级工具。
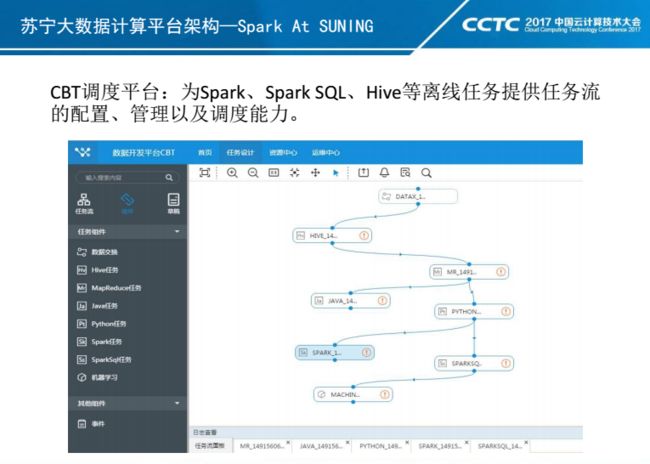
这个是CBT任务流调度平台。它针对目前包括Spark、Spark SQL、数据交换在内多种类型任务提供一个任务和任务流管理以及调度的能力。目前我们CBT平台集群规模在98台虚拟机,每天完成5W+任务的调度和执行。
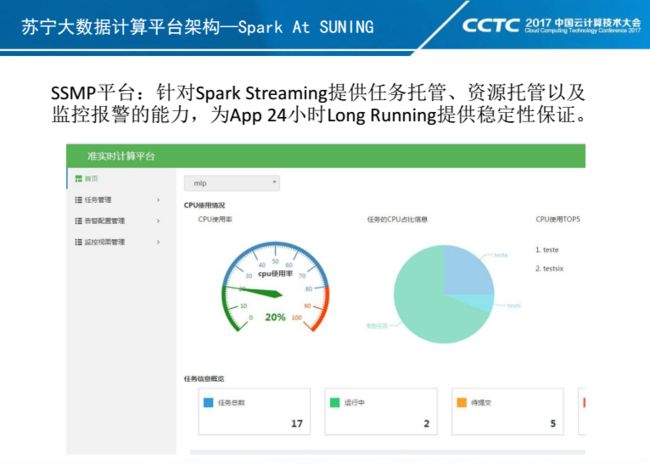
这是SSMP平台。专门针对Spark Streaming任务提供的一个任务管理和调度的平台,为任务提供24小时LongRunning的保障。
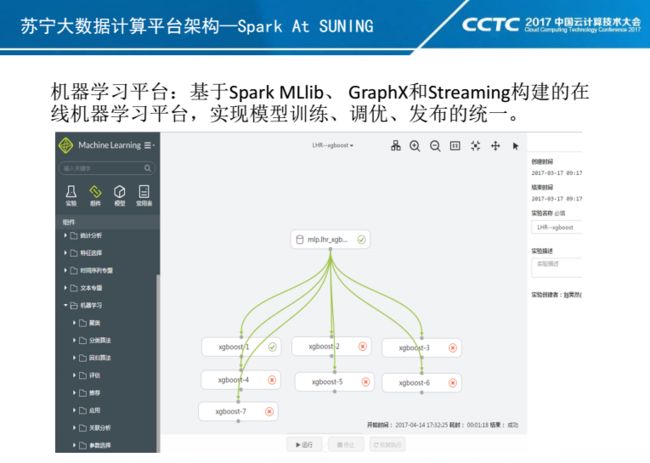
这是我们在线机器学习平台。目前该平台主要是基于Spark MLlib实现的,对GPU环境下深度学习算法的支持我们也正在开发。目前我们支持业务在线的进行Pipeline构建、模型训练、调优,并且支持对训练后的模型一键发布到Spark Streaming应用环境。
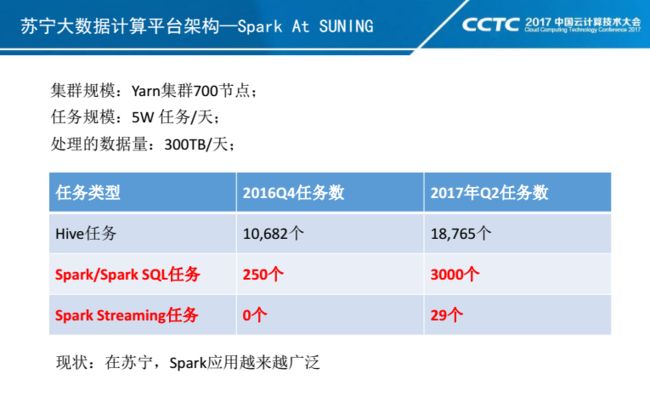
这是我们离线大集群的相关数据。目前我们离线这块集群节点数为700多个,每天通过CBT调度任务大概在5W+,每天处理的数据量在300T左右。
上面表格是我们2016年Q4中期以及最近统计的《Spark和Hive任务分布情况》。当前我们苏宁业务对Hive的依赖还是比较重,对Hive迁移到Spark SQL的工作我们也在逐步推进。另外我们单看Spark 任务变化情况:在这半年时间里,Spark任务数增速非常快,Spark任务新增3000+,Spark Streaming任务从0增长到29个。这里要强调一下,目前这3000个Spark任务里面,只有少少的200个任务是Spark SQL任务,在我们后续Hive迁移过程,Spark SQL任务数增速是会远远超过当前这个数字。
整体上来说,通过我们平台化以及服务化工作的开展,我们业务已经接受Spark作为它们数据分析链路上一个核心引擎。
Spark平台化遇到的问题
但是在我们整个平台化和服务化的过程中,也遇到很多很多的问题。这些问题一部分是因为业务自身对Spark理解和应用经验不够,还有一部分是因为我们服务化做的不够好。

在业务推广中,一般情况下业务遇到性能问题和故障时,都是直接反馈到平台组这边,由我们平台配合业务去定位和解决这些问题。
我们平台解决这些问题的思路:利用经验对任务执行过程和日志进行分析,尽最大可能去收集有效数据(但由于任务已经结束,一些运行时的数据可能无法收集),并且利用这些数据来定位和解决问题。但是这整个工作的效率非常低,而且存在很多同质化问题。
Spark自动化分析和故障诊断
从服务化角度出发,我们希望可以利用平台化的思路去解决这些问题,因此我们就做了这个Spark自动化分析和故障诊断系统,内部代号-华佗。
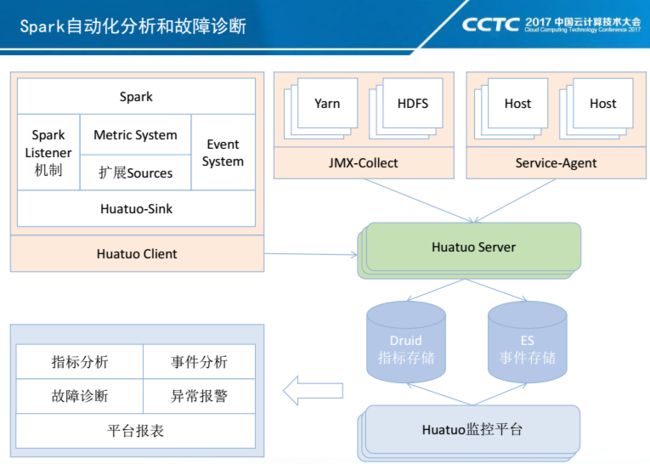
系统架构主要包括数据采集、华佗server、数据存储以及监控分析平台几个模块。数据采集目前主要采集了Spark,Yarn、宿主机器等数据。其中Spark这块,我们扩展了Spark的Metric System以及Event System,并通过新增MetricSource来收集我们需要的信息;HDFS和Yarn是通过JMX-Collect来收集Metric信息;宿主机器利用Service-Agent来收集机器的CPU,内存,IO等Metric信息。数据通过华佗Server分别落地到Druid和ES两个存储中,其中Druid用来存储指标数据,ES用来存储事件数据。华佗监控平台,通过这两类数据来实现平台的指标分析,事件分析,故障诊断,异常报警以及任务报表等功能。

Druid是一种适用于时序化数据的OLAP分析引擎,特别适合于统计分析、系统监控等业务场景。而我们这里场景就是系统监控。
在Druid里面,数据是按照时间、维度、指标三种元素进行组织,支持TopN、GroupBy等聚合查询以及简单明细查询。关于明细查询这块,Druid的索引可以实现快速记录定位。但是相比ES,它的可控性要差点,所以我们目前整体OLAP这块是计划使用Druid+ES组合来为业务提供服务。其中Druid目前是作为主要的OLAP引擎进行推广,支撑销售报表、金融自助分析、风控平台以及平台监控等十多个业务场景。
下面我们具体看一下,我们系统针对Spark提供哪些分析和故障诊断的能力,主要是从资源、性能、故障三个角度出发。

首先看一下资源方面,我们对Spark的资源把控分为三个层面:1)站在Spark外部, 任务所使用的Yarn、HDFS以及宿主机器等外部资源的稳定性;2)站在Spark Linux进程本身,来分析任务进程资源的利用率;3)站在Spark内部,主要考虑Cache以及Shuffle的资源使用情况。
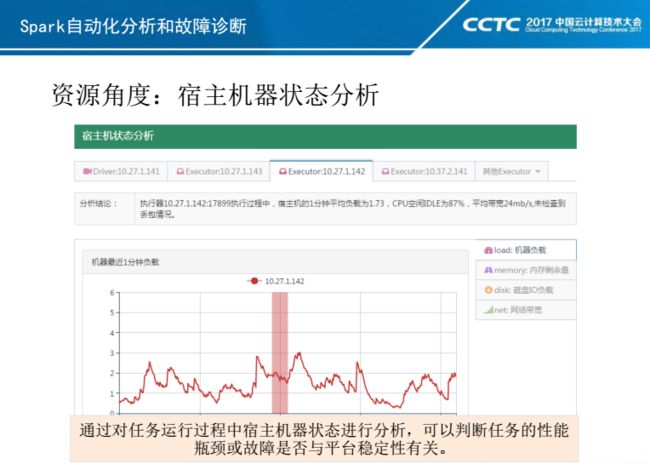
如果站在Spark服务使用角度来说:我们希望我们从Yarn上申请到的虚拟资源和实际运行的物理资源是匹配的。实际运行过程中,不应该出现Driver和Executor的宿主机器存在性能瓶颈,比如系统负载过高,网卡打满,甚至丢包。因为物理环境稳定性对Spark App的稳定性和性能是有非常大的影响的。
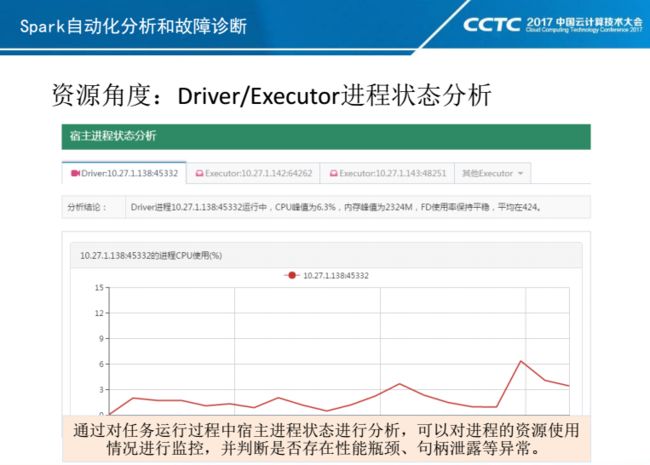
如果站在App进程角度,可以通过分析Driver和Executor的Linux进程是否存在瓶颈来发现App的性能和稳定性情况,比如Executor CPU利用率是否达到100%,或者Executor的FD是否保持持续增长,是否存在句柄泄露。
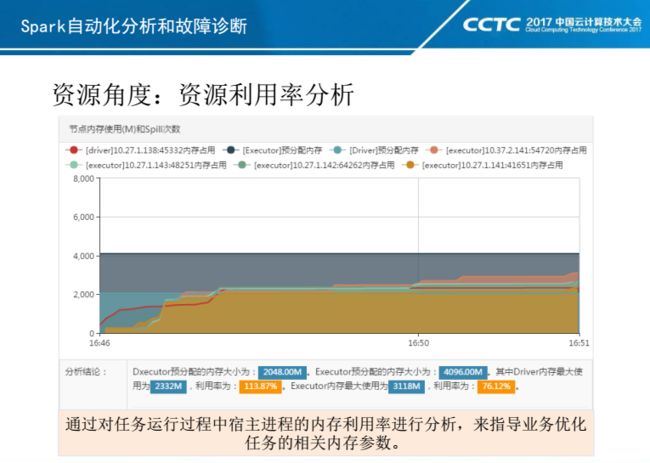
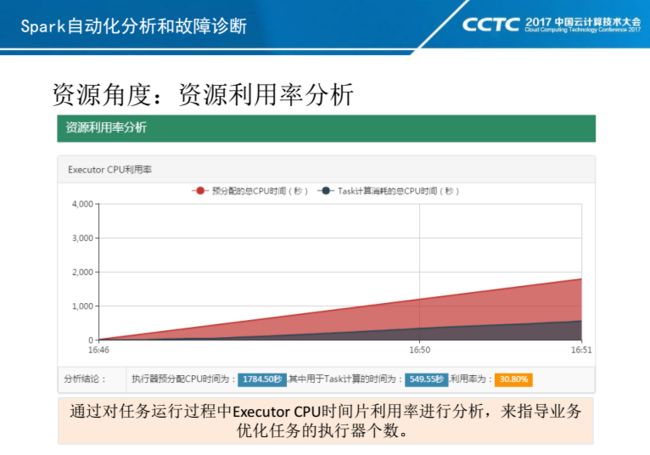
另外,相比Hive,Spark On Yarn有三个重要参数需要设置:Executor个数和内存,以及Driver内存。特别是Executor个数及内存,设置是否合理将很大程度上决定任务是否可以正常执行,以及资源是否合理利用。
上面两张PPT可以看出:Driver和Executor预分配内存以及实际占用内存的使用情况,以及Executor预分配的CPU时间片利用率情况,通过它们可以快速定位业务的资源利用率。
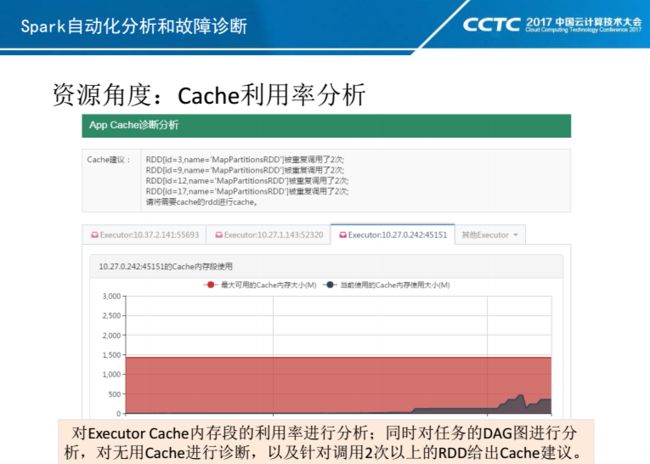
最后是站在Spark内部,来看Cache以及Shuffle资源使用情况。Spark 1.5.2版本中的Cache和Shuffle内存还是分段管理,对分段比例参数的调优是一件非常头疼事情。因此我们针对Cache和Shuffle内存做了图表可视化分析,可以快速指导业务进行参数调优。
另外对Cache机制,Spark开发新手可能会存在误解,有时直接对所有的RDD进行Cache。但实际上只有RDD/Dataset使用两次以上,才有必要进行Cache。因此我们对DAG图进行分析,针对是否需要Cache给出建议。
对于性能,主要从两个角度进行分析:1)站在Task角度,对Task耗时链和长尾Task进行分析;2)站在Stage角度,对任务调度Overhead以及并行度进行分析。
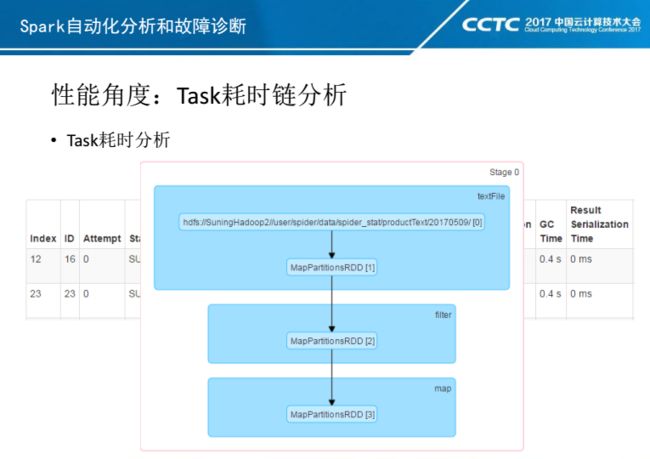
对于Task耗时,目前Spark页面已经提供了一些统计,比如调度延迟,GC耗时,反序列化耗时,Shuffle耗时等。但是业务还需要了解更多的耗时情况,比如每一步操作的耗时情况。假如业务逻辑其中一个map操作需要与外部数据源进行IO操作,那么对它的耗时统计会非常重要,因此我们做了耗时链的统计。
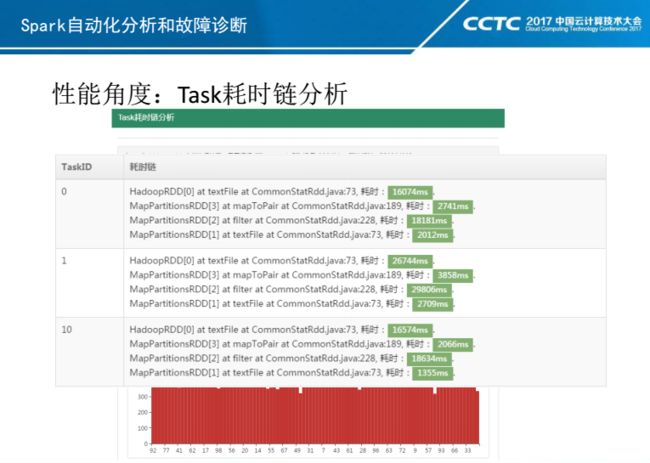

目前Task耗时链是基于RDD-Itertor来实现的,对于Spark 2.0+引入的Whole Stage Code Genaretion目前我们还未支持。
在RDD-Itertor模型中,RDD Transfer操作就是Itertor的连接操作,每一个Itertor的next和hasnext就是耗时源头,我们通过对Spark中的Itertor进行二次封装来收集每步耗时。另外有些情况下Itertor的next和hasnext不存在耗时,或者很小,主要耗时集中在Itertor对象的构造上,比如flatmap操作或者mappartition操作,先构造一个List,然后再做一个toItertor操作。这种情况下,需要统计Itertor的构造耗时,但是Itertor构造耗时涵盖了Parent耗时,统计时需要剔除Parent耗时情况。

长尾Task是Spark中非常常见的性能问题。长尾原因可能是业务数据倾斜,也有可能机器丢包,网卡CPU等资源存在瓶颈。目前我们做了长尾Task的报警和实时监控,并结合耗时链分析、进程和宿主机状态分析,以及后面谈到的数据倾斜来对长尾Task进行分析。

任务调度Overhead是平台比较伤感的问题,看着那些细碎任务,几十M数据用几百Task去跑,每个Task只执行几十毫秒。因此我们对任务Stage进行分析,统计任务实际计算时间与等待调度时间,从而判断是否存在调度Overhead。

造成任务调度Overhead的一个原因就是Reduce个数设置不合理,而且这是一个滚雪球效应,Reduce放大原始数据分区数,计算后写回HDFS,造成HDFS小文件,然后再反复的迭代,产生更多小文件,从而导致更加严重的Overhead。
在Spark 2.0+版本,新增Reduce个数自动适应是一个非常棒的功能,很大程度上解决了这个问题,但是对于1.5.2版本,这个问题还是依然存在。因此我们对Reduce操作进行分析,如上图,全局最大的Reduce操作数据量只有13M,使用默认40并发是不合理,强烈建议业务优化。
性能这块还做了一些其他的优化分析,比如JDBC并发度分析以及Kafka并发度分析。JDBC默认的API是可以不设置分区和并发度,这样单线程读JDBC会导致任务耗时较长;对于Kafka Direct API,默认是一个Spark分区读取Kafka一个分区,但是在很多业务场景下可能会成为瓶颈。
最后就是故障诊断,其实前面分析的结果可以直接用于故障诊断,但我们针对一些常见故障,单独提炼出来,从而可以更加直接发现问题,比如:Shuffle数据倾斜、HDFS Commit阻塞、执行器丢失、高维Parquet写性能阻塞等。
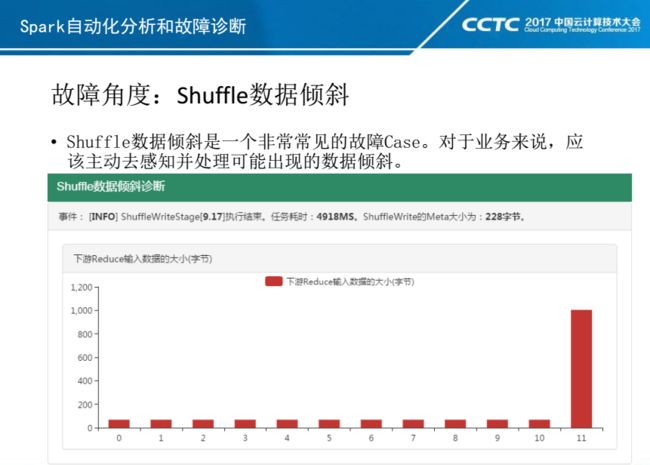
我们在Shuffle Write任务结束以后,提前对后续Read的数据量进行计算,判断后续的Shuffle Read操作是否存在倾斜,从而可以直接给业务一个结论:是否需要优化业务逻辑或参数。

HDFS Commit阻塞是出现频率比较高的故障。目前CBT任务调度平台有一个很密集的任务执行时间,大概是0点-7点。在这个时间段,HDFS性能显著下降,最大rpc延迟可能达几百ms。
其次如MAPREDUCE-4815描述:HDFS Commit操作是在Driver中串行执行,如果计算生成几千个小文件,那么整体Commit耗时就会增加几百秒,这是一个很大的性能损耗。
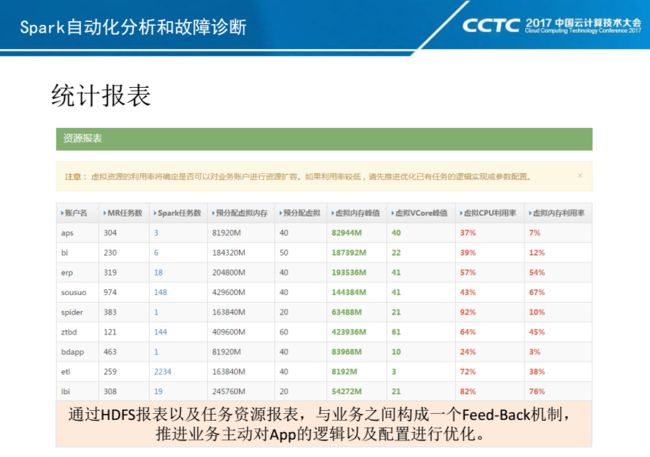
最后就是资源报表,通过它与业务之间构成一个Feed-Back机制,推进业务主动对App的逻辑以及配置进行优化。
对于Spark及其他组件平台化服务化,将是一个持续经验积累和优化的过程,大家有好的想法欢迎讨论和交流。
更多精彩,欢迎关注CSDN大数据公众号!
