老规矩,先导入及设置各种参数。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
df = pd.read_table('smoking_cancer.txt')
print(df.head())
print(df.describe())
STATE CIG BLAD LUNG KID LEUK
0 AL 18.20 2.90 17.05 1.59 6.15
1 AZ 25.82 3.52 19.80 2.75 6.61
2 AR 18.24 2.99 15.98 2.02 6.94
3 CA 28.60 4.46 22.07 2.66 7.06
4 CT 31.10 5.11 22.83 3.35 7.20
CIG BLAD LUNG KID LEUK
count 44.000000 44.000000 44.000000 44.000000 44.000000
mean 24.914091 4.121136 19.653182 2.794545 6.829773
std 5.573286 0.964925 4.228122 0.519080 0.638259
min 14.000000 2.860000 12.010000 1.590000 4.900000
25% 21.230000 3.207500 16.437500 2.457500 6.532500
50% 23.765000 4.065000 20.320000 2.845000 6.860000
75% 28.097500 4.782500 22.807500 3.112500 7.207500
max 42.400000 6.540000 27.270000 4.320000 8.280000
1. 抽烟的趋势与分布
我是不抽烟的。我体会不了那抽的是寂寞的感觉。与其来一些烟的数据,来点酒的数据其实更和酒鬼东哥之意哈,不过估计这样的数据很难找……
先看看抽烟的大体情况。
plt.hist(df.CIG, bins=20,rwidth=0.9)
(array([ 1., 1., 3., 0., 4., 7., 7., 1., 5., 4., 6., 1., 1.,
1., 0., 0., 0., 0., 1., 1.]),
array([ 14. , 15.42, 16.84, 18.26, 19.68, 21.1 , 22.52, 23.94,
25.36, 26.78, 28.2 , 29.62, 31.04, 32.46, 33.88, 35.3 ,
36.72, 38.14, 39.56, 40.98, 42.4 ]),
)
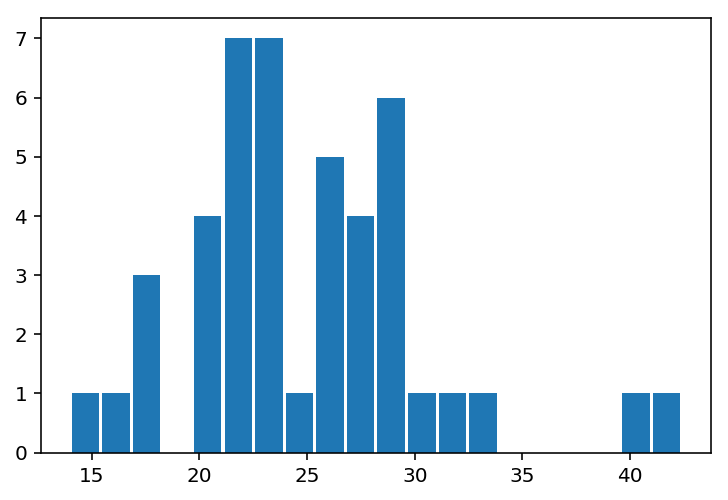
说实话,这个分布很怪异……
比如说,19附近凭什么没有值?25左边凭什么就很少?难道大家都不约而同的跳过去了吗?
其实这是样本偏差的问题。我们可以看到
len(df)
44
统计学的一个基本原则是大数定律。规律只能在数据量大的时候显示其规律性,数越大结果越倾向于其期望。44个州的样本明显无法满足「大数」的要求,反而可以满足小数定律:
“如果统计数字很少,就很容易出现特别不均匀的情况。这个现象被诺贝尔经济学奖得主丹尼尔·卡尼曼戏称为“小数定律”。卡尼曼说如果我们不理解小数定律,我们就不能真正理解大数定律。
而小数定律说如果样本不够大,那么它就会表现为各种极端情况,而这些情况可能跟本性一点关系没有。”
—— Excerpt From: 万维钢(同人于野). “万万没想到:用理工科思维理解世界.”
so,我们还是继续往下分析罢。样本不够的情况下,这样的分析没有意义。
print('Median value of CIG is %.2f.' % df.CIG.median())
print('Mean value of CIG is %.2f.' % df.CIG.mean())
cig = df.CIG.copy()
cig.name = 'Cig'
plt.boxplot(cig, vert=False,labels=[cig.name])
print('STD value of CIG is %.2f.' % cig.std())
Median value of CIG is 23.77.
Mean value of CIG is 24.91.
STD value of CIG is 5.57.
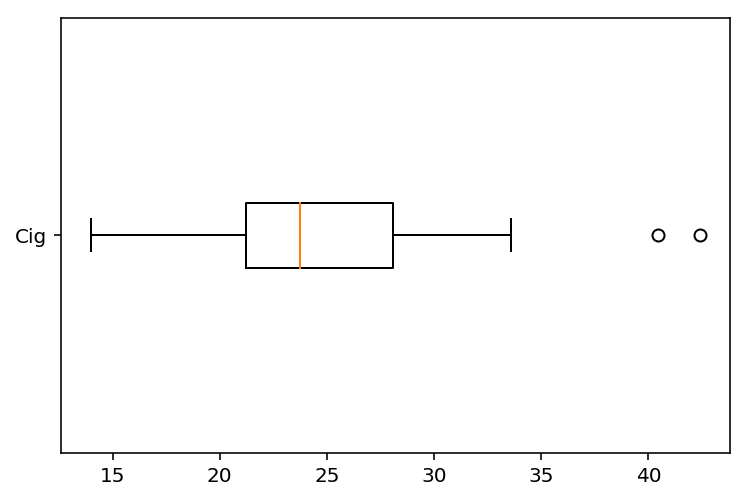
好吧,这样依然看不出什么有意义的结果……话说做数据分析,背景知识很重要,要不然得到了分析结果也不知道代表了什么……
还是接着看看抽烟和疾病的关系吧,这个貌似不用太多的背景知识。
2. 抽烟与疾病的关系
依次对比一下各种疾病
print('The Correlation Value of CIG and disease is:')
print(df.corr())
The Correlation Value of CIG and disease is:
CIG BLAD LUNG KID LEUK
CIG 1.000000 0.703622 0.697403 0.487390 -0.068481
BLAD 0.703622 1.000000 0.658501 0.358814 0.162157
LUNG 0.697403 0.658501 1.000000 0.282743 -0.151584
KID 0.487390 0.358814 0.282743 1.000000 0.188713
LEUK -0.068481 0.162157 -0.151584 0.188713 1.000000
plt.scatter(df.CIG, df.BLAD)
plt.show()
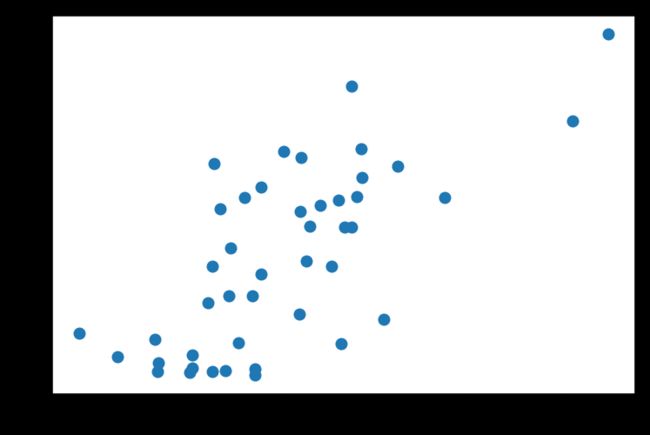
BLAD是膀胱癌,相关系数高达0.7,而且从图上明显可以看出有相关趋势。这让我感觉很尴尬,膀胱是贮尿器官,用来贮藏和排泄小便;抽烟按说最直接影响的应该是呼吸器官,比如气管、肺之类的啊……这个让人怎么解释?
plt.scatter(df.CIG, df.LUNG)
plt.show()
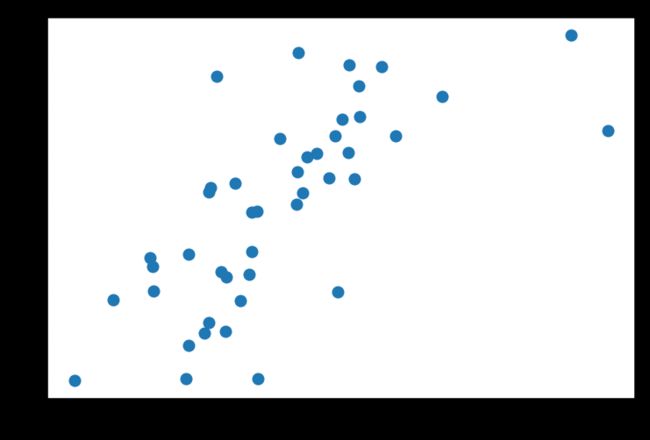
LUNG是肺癌,相关系数为0.69,按说也不错,只是有了前面的膀胱癌作比较,就未免尴尬了一些……
plt.scatter(df.CIG, df.KID)
plt.show()
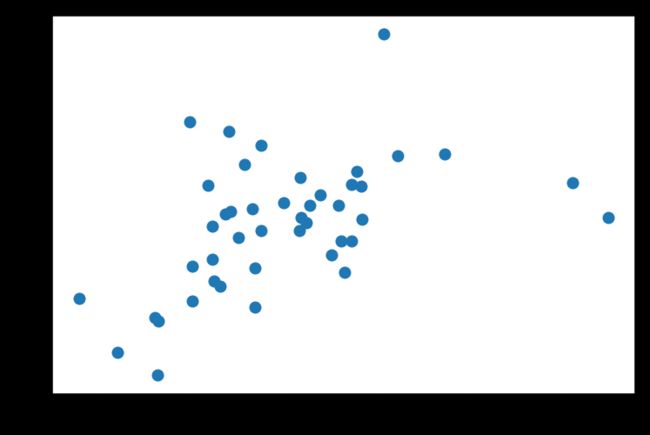
KID是肾癌,相关系数0.48。从图上也能明显看出,肾癌的高发区域集中在CIG 20-30之间。但这个数据并不能说明什么,因为CIG 20-30之间的州本来就占了大多数
df2030 = df[(df.CIG > 20) & (df.CIG <30)]
print('The NO. of states between 20 and 30 is %i.' % len(df2030))
print('The NO. of total states is %i.' % len(df))
p = (len(df2030)*1.0)/(len(df)*1.0)*100.0
print('The percentage of df20-30 is %.2f%%.' % p)
The NO. of states between 20 and 30 is 33.
The NO. of total states is 44.
The percentage of df20-30 is 75.00%.
所以,这些数据说明不了太多东西。
plt.scatter(df.CIG, df.LEUK)
plt.show()
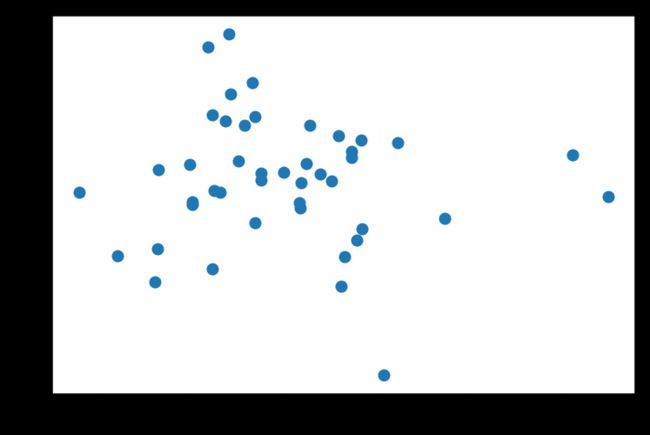
如果说前三个好歹还有点关联的话,最后这个 LEUK 白血病,和抽烟就干脆一点关系没有了,相关系数仅-0.068。不过在维基百科上查了查白血病此条,赫然发现
白血病发生的真正原因尚未知晓,目前相信环境与遗传因素都扮演了重要角色[5]。风险因子包括:吸烟、游离辐射、部分化学物质如苯、曾接受化疗、唐氏综合症、家族史有白血病。
白血病 - 维基百科,自由的百科全书
呃,这个……以我的水平,维基百科就等于科学结论,所以这个结果也让我很尴尬啊……
学点和现实相关的东西果然不是什么容易的事情。
最后,作为好事者,我看了看各种癌的数据有没有什么相关性。
df = df.drop('CIG',axis=1)
df.corr()
BLAD LUNG KID LEUK
BLAD 1.000000 0.658501 0.358814 0.162157
LUNG 0.658501 1.000000 0.282743 -0.151584
KID 0.358814 0.282743 1.000000 0.188713
LEUK 0.162157 -0.151584 0.188713 1.000000
按说一个人没法死于两个癌症,所以这个数据并什么用我也不知道……
不过还是可以分析出一些东西。从表中可以看出,BLAD 和 LUNG 的相关性比较高一点。考虑到这个数据是每州死因数据,是否可以认为,膀胱癌和肺癌可能有相似的诱因?维基百科了一下:
罹患膀胱癌最主要的危险因子是来自基因的影响,另外吸烟、长期接触某种染料(含苯胺(aniline)成分者,如纺织厂员工就可能接触到)、汽油或其他化学物质者也有较高的风险。
大多数(80-90%)肺癌患者患病的原因为长期吸烟,然而大约10-15%的患者从不吸烟,这部分人患上肺癌往往是由于遗传因素和吸入空气污染物共同导致,污染物包括氡气、石棉或其它形式的空气污染,包括二手烟。
排除基因和吸烟,更多更主要的因素貌似都在污染上。染料(含苯胺(aniline))汽油或其他化学物质者,氡气、石棉或其它形式的空气污染,差不多可以归为一类。
壮哉,我大中华,雾霾威武!