原文首发:http://www.zhoulujun.cn/zhoulujun/html/theory/model/8026.html
谈前后端分工,接口设计,resetful啥,不得不谈谈web的发展史。
在web元年,每个web开发工程师都是真正的全栈工程师。哪有什么前后不搭边的事儿!
到MVC时代,术业开始专工了。有最流行的Spring,有了iBatis这样的数据持久层框架,即ORM,对象关系映射,有……%……
于是,package就会有这样的几个文件夹:
|____mappers
|____model
|____service
|____utils
|____controller
在mappers这一层,我们所做的莫过于如下所示的数据库相关查询:
@Insert(
"INSERT INTO users(username, password, enabled) " +
"VALUES (#{userName}, #{passwordHash}, #{enabled})"
)
@Options(keyProperty = "id", keyColumn = "id", useGeneratedKeys = true)
void insert(User user);
model文件夹和mappers文件夹都是数据层的一部分,只是两者间的职责不同,如:
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
而他们最后都需要在Controller,又或者称为ModelAndView中处理:
@RequestMapping(value = {"/disableUser"}, method = RequestMethod.POST)
public ModelAndView processUserDisable(HttpServletRequest request, ModelMap model) {
String userName = request.getParameter("userName");
User user = userService.getByUsername(userName);
userService.disable(user);
Map map = new HashMap();
Map usersWithRoles= userService.getAllUsersWithRole();
model.put("usersWithRoles",usersWithRoles);
return new ModelAndView("redirect:users",map);
}
在多数时候,Controller不应该直接与数据层的一部分,而将业务逻辑放在Controller层又是一种错误,这时就有了Service层,如下图:
3
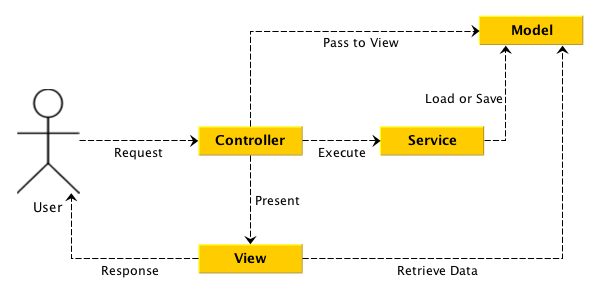
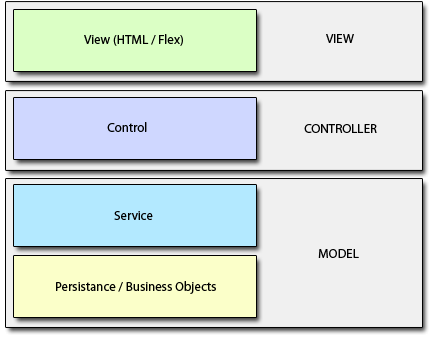
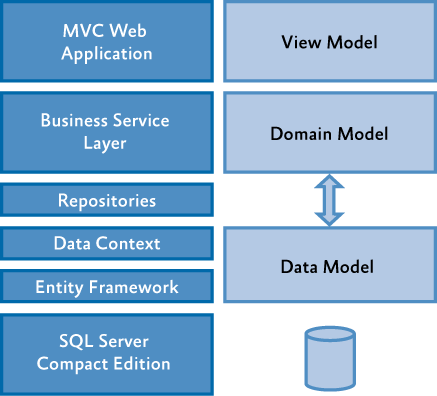
Domain(业务)是一个相当复杂的层级,这里是业务的核心。一个合理的Controller只应该做自己应该做的事,它不应该处理业务相关的代码:
if (isNewnameEmpty == false && newuser == null){
user.setUserName(newUsername);
List myPosts = postService.findMainPostByAuthorNameSortedByCreateTime(principal.getName());
for (int k = 0;k < myPosts.size();k++){
Post post = myPosts.get(k);
post.setAuthorName(newUsername);
postService.save(post);
}
userService.update(user);
Authentication oldAuthentication = SecurityContextHolder.getContext().getAuthentication();
Authentication authentication = null;
if(oldAuthentication == null){
authentication = new UsernamePasswordAuthenticationToken(newUsername,user.getPasswordHash());
}else{
authentication = new UsernamePasswordAuthenticationToken(newUsername,user.getPasswordHash(),oldAuthentication.getAuthorities());
}
SecurityContextHolder.getContext().setAuthentication(authentication);
map.clear();
map.put("user",user);
model.addAttribute("myPosts", myPosts);
model.addAttribute("namesuccess", "User Profile updated successfully");
return new ModelAndView("user/profile", map);
}
我们在Controller层应该做的事是:
处理请求的参数
渲染和重定向
选择Model和Service
处理Session和Cookies
业务是善变的,昨天我们可能还在和对手竞争谁先推出新功能,但是今天可能已经合并了。我们很难预见业务变化,但是我们应该能预见Controller是不容易变化的。在一些设计里面,这种模式就是Command模式。
View层是一直在变化的层级,人们的品味一直在更新,有时甚至可能因为竞争对手而产生变化。在已经取得一定市场的情况下,Model-Service-Controller通常都不太会变动,甚至不敢变动。企业意识到创新的两面性,要么带来死亡,要么占领更大的市场。但是对手通常都比你想象中的更聪明一些,所以这时开创新的业务是一个更好的选择。
高速发展期的企业和发展初期的企业相比,更需要前端开发人员。在用户基数不够、业务待定的情形中,View只要可用并美观就行了,这时可能就会有大量的业务代码放在View层:
${errors.username} ${errors.password}
Woohoo, User ${user.userName} has been created successfully!
不同的情形下,人们都会对此有所争议,但只要符合当前的业务便是最好的选择。作为一个前端开发人员,在过去我需要修改JSP、PHP文件,
到了web2.0,阿贾克斯(ajax)这玩意蹦的挺欢,把交互玩high了,
各种流氓架构师,把Server Side Render 提到Client Side Render
总的来说,从原来的cs到bs,到app,h5,前端, 只是gui程序而已,他应该只是负责数据层面的展示和反馈。
但是,我们还是基于类MVC模式。只是数据的获取方式变成了Ajax,我们就犯了一个错误——将大量的业务逻辑放在前端。这时候我们已经不能再从View层直接访问Model层,从安全的角度来说有点危险。
离开了JSP,将View层变成了Template与Controller。而原有的Services层并不是只承担其原来的责任,这些Services开始向ViewModel改变。
于是,在本来就脆弱的网络上,加载 巨无霸的 页面请求。
前端,后端,都得熟悉业务。但是,业务的需求总是在变,而且一个人做好多项目。如果来了一个新人接手,将业务就是半天。
业务,也分拆从数据流,有清晰数据走向图。前后台接口并联开发,业务整合串联调试。
为了前后端更好的分工,接口文档是必须的,前后端都根据接口文档写代码,然后对接接口就行了。
但是,后端跟不上前端节奏,接口跟不上来怎么办?即便接口跟上来了,大后端数据跟不上又怎么办?
第一种想到的方法就是模拟返回数据,根据接口文档定义好的返回数据格式,新建一个json文件夹,里面放一堆*.json文件,像这样:
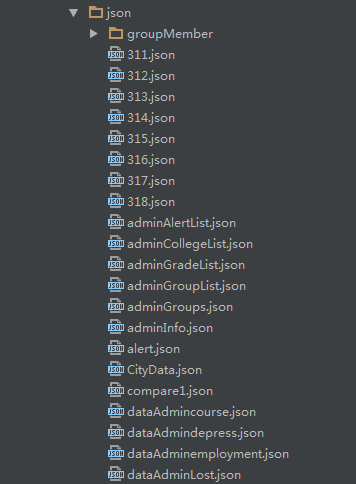
然后请求json数据,像这样:
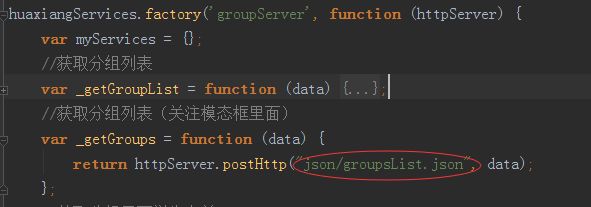
所以为了前端有数据,就会有很多很多的请求json文件。当后端接口上来后,又要一个一个挨着去把json请求改为真实接口名,这就要求代码需要写的比较规范,不然接口的对接真的很难受,而且在修改某些复杂逻辑的地方的时候还必须的小心翼翼,不然就只有等测试发来bug单了。
造json文件模拟请求对于小的项目确实还是挺方便的,但是项目大了呢,上百个接口甚至更多呢?
一堆一堆的json看着都烦,还不说前后端对接了。
2.第二,写好接口,返回假数据,但是,这个比直接写json延后的工期更长……
……………………………………………………华丽的等等等
目前大部分公司都实行了前后端分离开发。在项目开发过程当中,经常会遇到以下几个尴尬的场景;
1、没有文档的库。就好像在操纵一个黑盒一样,预期不了它的正常行为是什么。比如:输入了一个 A,预期返回的是一个 B,结果它什么也没有。有的时候,还抛出了一堆异常,导致你的应用崩溃。对此你是狗咬乌龟
2、文档老旧,并且不够全面。这个问题相比于没有文档来说,愈加的可怕。我们需要的接口不在文档上,文档上的接口不存在库里,又或者是少了一行关键的代码。
3、前端开发依赖于后端接口数据,需要与后端接口联调才能获得数据展示,从而拖慢了开发进度;
4、没有一个很好的结构化接口文档管理工具,能够对项目中所用到的接口进行管理。如一个请求的地址、有几个参数、参数名称及类型含义等等。同时支持项目、历史版本的切换。
5、没有一个号的接口管理、版本控制工具。
……………………………………………………华丽的等等等
API 都搞不好,还怎么当程序员?如果 API 设计只是后台的活,为什么还需要前端工程师。
在前后端分离的项目里,API 也是这样一个烦人的存在。我们就经常遇到各种各样的问题:
*API 的字段更新了
*API 的路由更新了
*API 返回了未预期的值
*API 返回由于某种原因被删除了
……………………………………………………华丽的等等等
**API 的维护是一件烦人的事,所以最好能一次设计好 API。**可是这是不可能的,API 在其的生命周期里,应该是要不断地演进的。它与精益创业的思想是相似的,当一个 API 不合适现有场景时,应该对这个 API 进行更新,以满足需求。也因此,API 本身是面向变化的,问题是这种变化是双向的、单向的、联动的?还是静默的?
API 设计是一个非常大的话题,这里我们只讨论:演进、设计及维护
新的业务需求来临时,前端、后台是一起开始工作的。而不是后台在前,又或者前端先完成。他们开始与业务人员沟通,需要在页面上显示哪些内容,需要做哪一些转换及特殊处理。
然后便配合着去设计相应的 API:请求的 API 路径是哪一个、请求里要有哪些参数、是否需要鉴权处理等等。对于返回结果来说,仍然也需要一系列的定义:返回哪些相应的字段、额外的显示参数、特殊的 header 返回等等。除此,还需要讨论一些异常情况,如用户授权失败,服务端没有返回结果。
整理出一个相应的文档约定,前端与后台便去编写相应的实现代码。
最后,再经历痛苦的集成,便算是能完成了工作。
可是,API 在这个过程中是不断变化的,因此在这个过程中需要的是协作能力。它也能从侧面地反映中,团队的协作水平。
API 的协作设计
API 设计应该由前端开发者来驱动的。后台只提供前端想要的数据,而不是反过来的。后台提供数据,前端从中选择需要的内容。
我们常报怨后台 API 设计得不合理,主要便是因为后台不知道前端需要什么内容。这就好像我们接到了一个需求,而 UX 或者美工给老板见过设计图,但是并没有给我们看。我们能设计出符合需求的界面吗?答案,不用想也知道。
因此,当我们把 API 的设计交给后台的时候,也就意味着这个 API 将更符合后台的需求。那么它的设计就趋向于对后台更简单的结果,比如后台返回给前端一个 Unix 时间,而前端需要的是一个标准时间。又或者是反过来的,前端需要的是一个 Unix 时间,而后台返回给你的是当地的时间。
与此同时,按前端人员的假设,我们也会做类似的、『不正确』的 API 设计。
因此,API 设计这种活动便像是一个博弈。
使用文档规范 API的糟点
不论是异地,或者是坐一起协作开发,使用 API 文档来确保对接成功,是一个“低成本”、较为通用的选择。在这一点上,使用接口及函数调用,与使用 REST API 来进行通讯,并没有太大的区别。
先写一个 API 文档,双方一起来维护,文档放在一个公共的地方,方便修改,方便沟通。慢慢的再随着这个过程中的一些变化,如无法提供事先定好的接口、不需要某个值等等,再去修改接口及文档。
可这个时候因为没有一个可用的 API,因此前端开发人员便需要自己去 Mock 数据,或者搭建一个 Mock Server 来完成后续的工作。
因此,这个时候就出现了两个问题:
维护 API 文档很痛苦
需要一个同步的 Mock Server
而在早期,开发人员有同样的问题,于是他们有了 JavaDoc、JSDoc 这样的工具。它可以根据代码文件中注释信息,生成应用程序或库、模块的API文档的工具。
然而,它并不能解决没有人维护文档的问题,并且无法及时地通知另外一方。当前端开发人员修改契约时,后台开发人员无法及时地知道,反之亦然。但是持续集成与自动化测试则可以做到这一点。
然而,它并不能解决没有人维护文档的问题,并且无法及时地通知另外一方。当前端开发人员修改契约时,后台开发人员无法及时地知道,反之亦然。但是持续集成与自动化测试则可以做到这一点。
契约测试:基于持续集成与自动化测试
当我们定好了这个 API 的规范时,这个 API 就可以称为是前后端之间的契约,这种设计方式也可以称为『契约式设计』。(定义来自维基百科)
这种方法要求软件设计者为软件组件定义正式的,精确的并且可验证的接口,这样,为传统的抽象数据类型又增加了先验条件、后验条件和不变式。这种方法的名字里用到的“契约”或者说“契约”是一种比喻,因为它和商业契约的情况有点类似。
按传统的『瀑布开发模型』来看,这个契约应该由前端人员来创建。因为当后台没有提供 API 的时候,前端人员需要自己去搭建 Mock Server 的。可是,这个 Mock API 的准确性则是由后台来保证的,因此它需要共同去维护。
与其用文档来规范,不如尝试用持续集成与测试来维护 API,保证协作方都可以及时知道。
在 2011 年,Martin Folwer 就写了一篇相关的文章:集成契约测试,介绍了相应的测试方式:
其步骤如下:
编写契约(即 API)。即规定好 API 请求的 URL、请求内容、返回结果、鉴权方式等等。
根据契约编写 Mock Server。可以采用 Moco
编写集成测试将请求发给这个 Mock Server,并验证
前端测试与 API 适配器
因为前端存在跨域请求的问题,我们就需要使用代理来解决这个问题,如 node-http-proxy,并写上不同环境的配置:
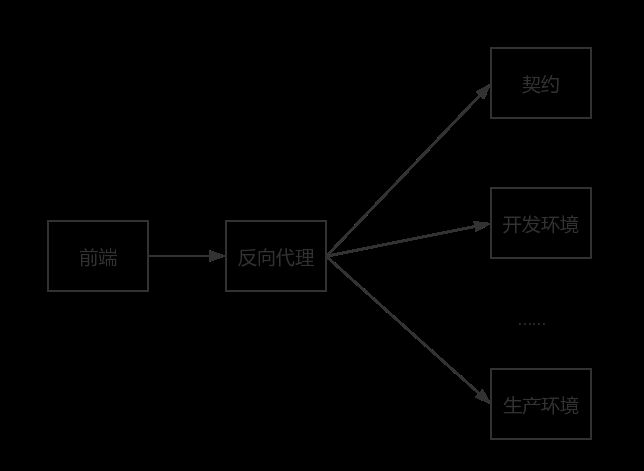
这个代理就像一个适配器一样,为我们匹配不同的环境。
在前后端分离的应用中,对于表单是要经过前端和后台的双重处理的。同样的,对于前端获取到的数据来说,也应该要经常这样的双重处理。因此,我们就可以简单地在数据处理端做一层适配。
写前端的代码,我们经常需要写下各种各样的:
if(response && response.data && response.data.length > 0){}
即使后台向前端保证,一定不会返回 null 的,但是我总想加一个判断。刚开始写 React 组件的时候,发现它自带了一个名为 PropTypes 的类型检测工具,它会对传入的数据进行验证。而诸如 TypeScript 这种强类型的语言也有其类似的机制。
而后台,单没有数据的时候,比如数组,返回空素组,对象,返回空对象。
比如,
总之,API 使用的第一原则:不要『相信』前端提供的数据,不要『相信』后台返回的数据。
什么是RAP?
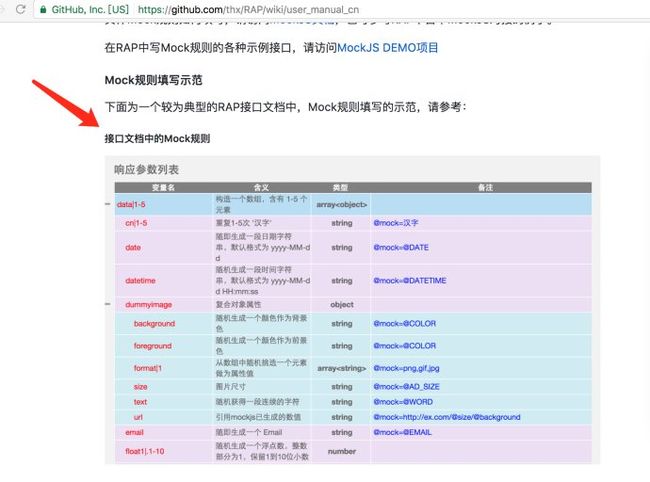
RAP是阿里团队出的一款WEB接口管理工具,帮助开发人员更高效的管理接口文档,同时通过分析接口结构自动生成Mock数据、校验真实接口的正确性,使接口文档成为开发流程中的强依赖。
引用官方文档上的说明:
在前后端分离的开发模式下,我们通常需要定义一份接口文档来规范接口的具体信息。如一个请求的地址、有几个参数、参数名称及类型含义等等。RAP 首先方便团队录入、查看和管理这些接口文档,并通过分析结构化的文档数据,重复利用并生成自测数据、提供自测控制台等等... 大幅度提升开发效率
为什么要使用RAP?
1.在实际开发中,前后端的协作往往存在一些不可避免的问题,影响工作效率;
2.RAP提供Mock服务,自动根据接口文档生成Mock接口,这些接口会自动生成模拟数据,支持复杂的生成逻辑;
3.面对需求不断变更或需求拿捏不定的客户,可以使用RAP模拟数据,前端快速对接,将其作为演示用途供客户参考,避免一些后台开发的无用功;
4.RAP提供团队管理,项目管理,可视化编辑,以及完善的版本控制;
5.Mock接口和实际接口的切换,仅一句js代码引用与否,十分方便;
6.接口先于开发,接口驱动开发,前后端开发互不干扰,互不依赖,能够更好的利于团队协作
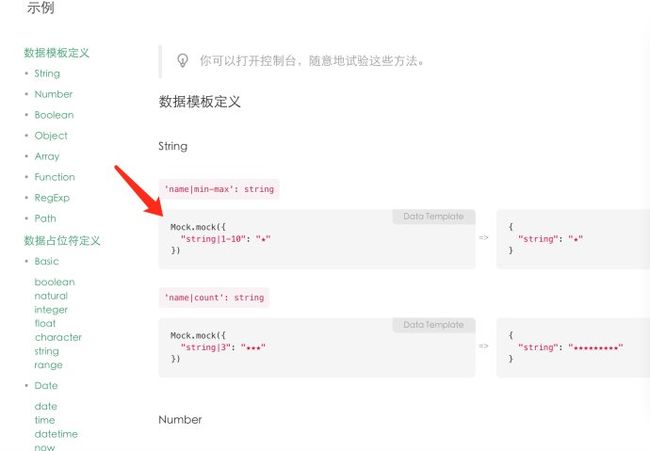
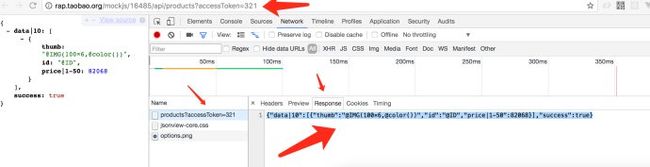
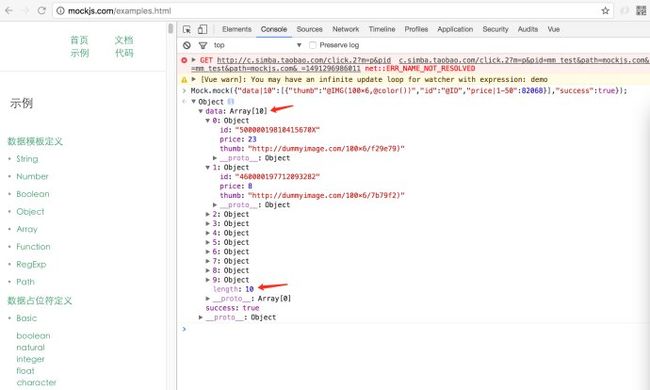
RAP集中解决了两个问题:1、出色的接口文档化处理; 2、完善mock接口数据,支持自定义拓展mock.js;
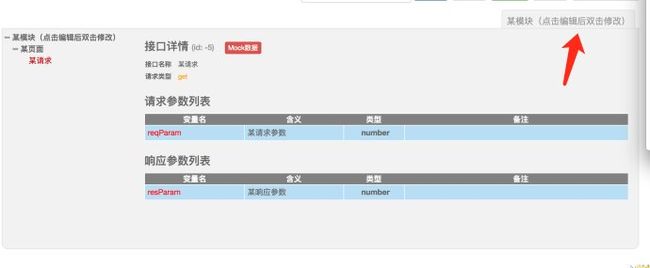
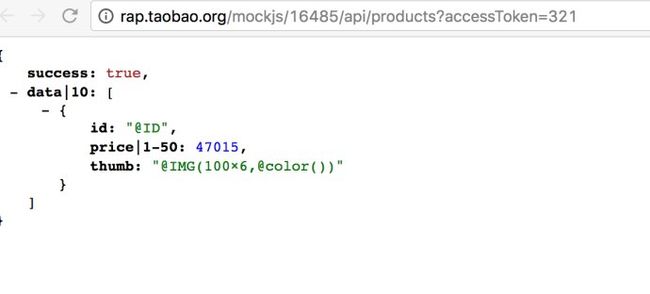
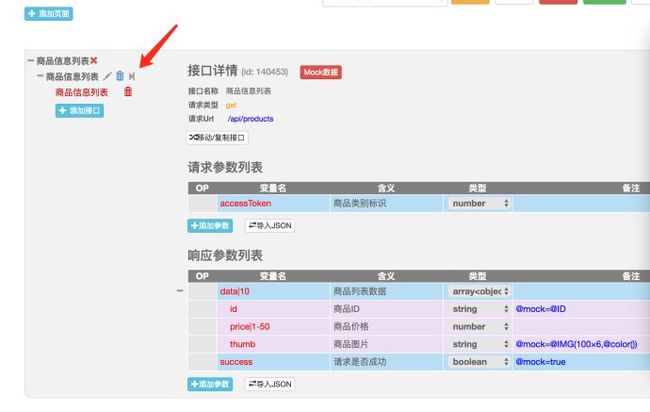
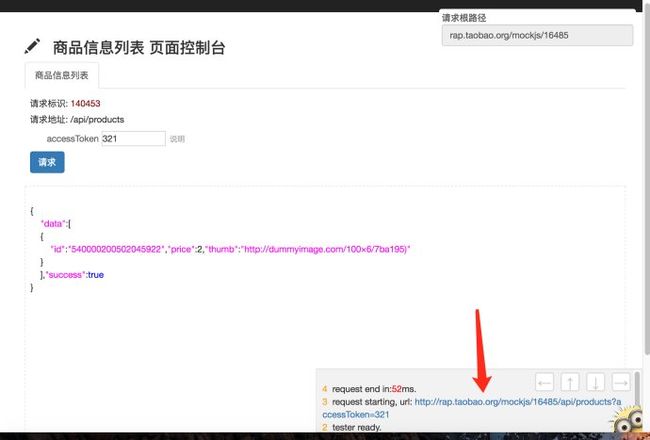
具体操作步骤:4
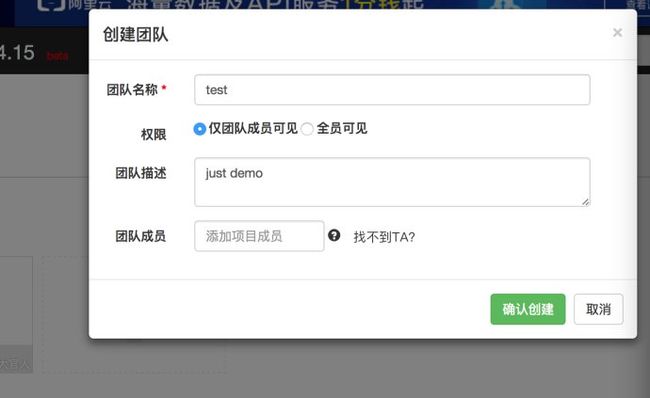
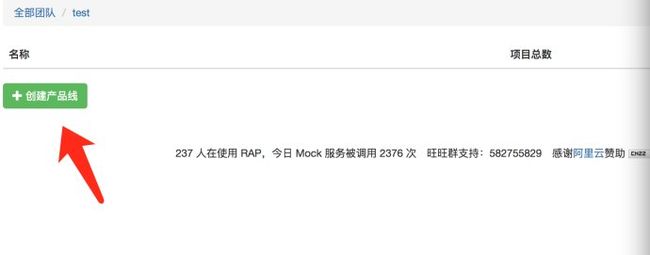
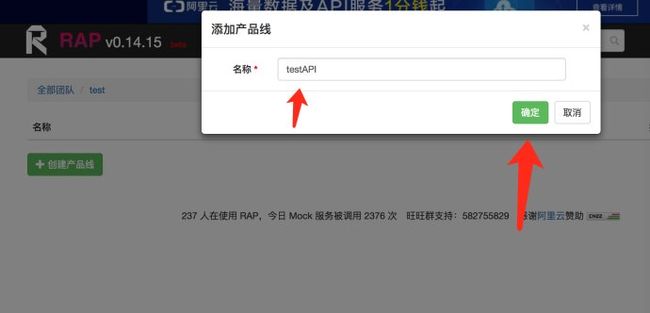
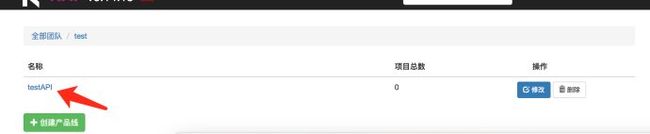
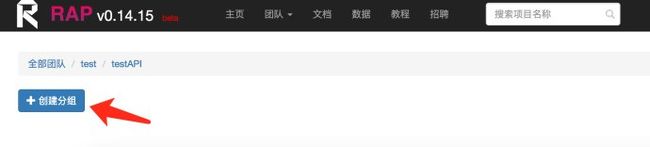
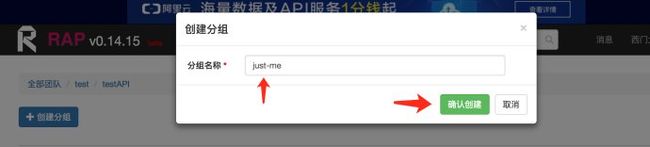
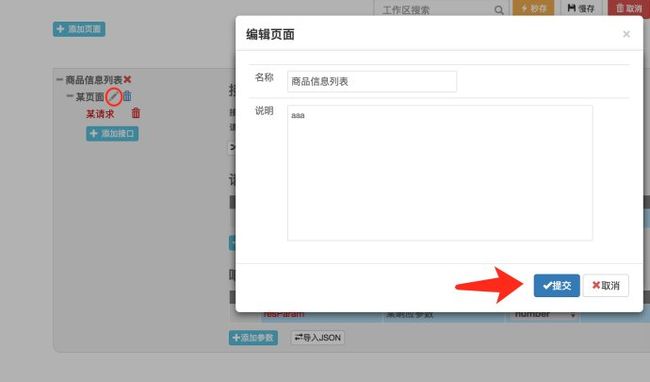
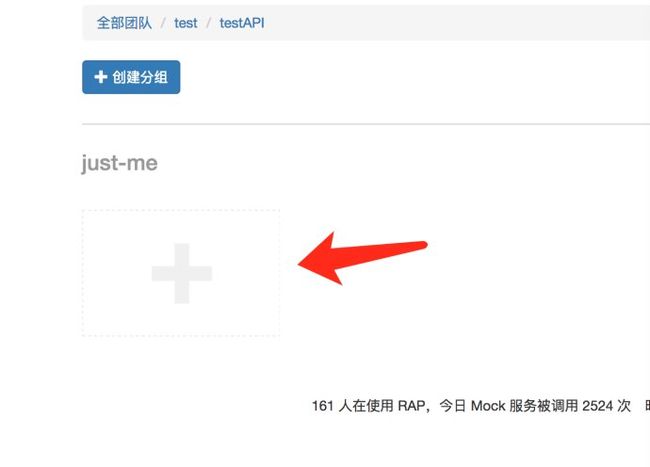
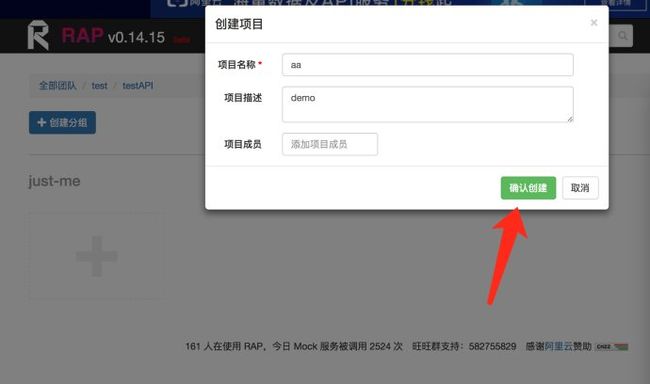
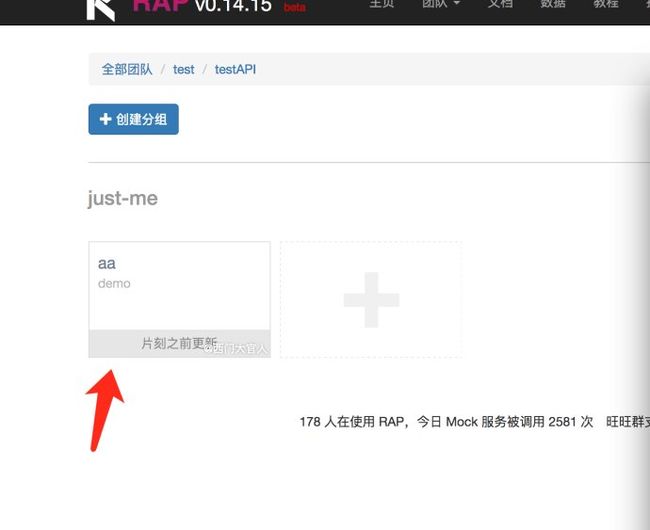
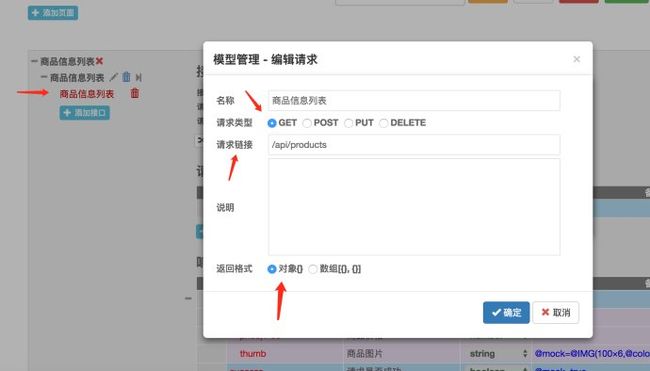
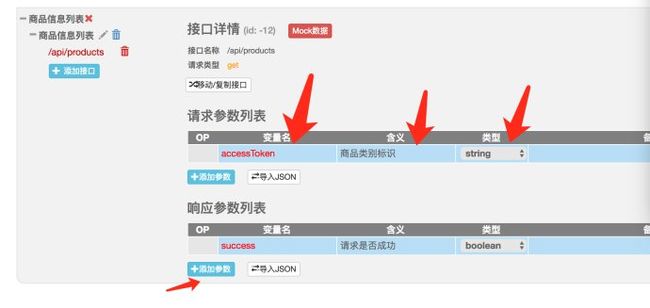


原文首发:http://www.zhoulujun.cn/zhoulujun/html/theory/model/8026.html
参考文章:
如何处理好前后端分离的 API 问题
使用RAP搭建前端Mock Server