机器学习之线性回归 Linear Regression(二)Python实现
一元线性回归
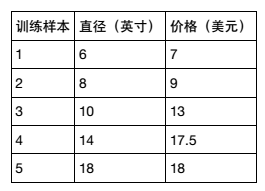
假设你想计算匹萨的价格。 虽然看看菜单就知道了,不过也可以用机器学习方法建一个线性回归模型,通过分析匹萨直径与价格的线性关系,来预测任意直径匹萨的价格。假设我们查到了部分匹萨的直径与价格的数据,这就构成了训练数据,如下表所示:
import matplotlib.pyplot as plt
def runplt():
plt.figure()
plt.title("Cost and diameter")
plt.xlabel("Diameter/inch")
plt.ylabel("Cost/dollar")
plt.axis([0,25,0,30])
plt.grid(True)
return plt
plt = runplt()
X = [[6],[8],[10],[14],[18]]
y = [[7],[9],[13],[17.5],[18]]
plt.plot(X,y,'k.')
plt.show()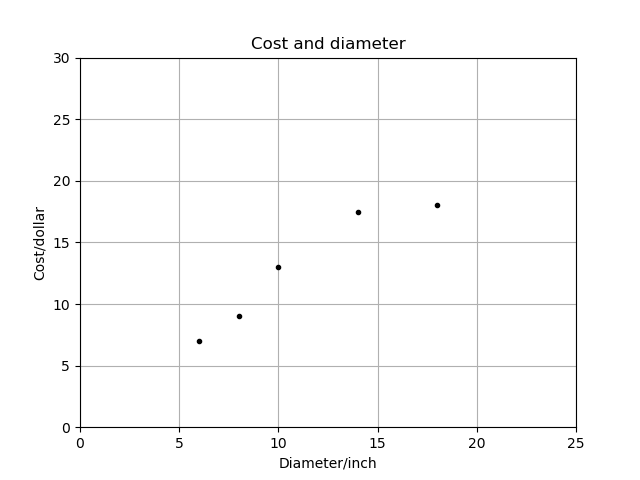
上图中,x轴表示匹萨直径,y轴表示匹萨价格。 能够看出,匹萨价格与其直径正相关,这与我们的日常经验也比较吻合,自然是越大越贵。
下面就用 scikit-learn 来建模
#创建并拟合模型
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X,y)
print("Predict 12 inch cost:$%.2f" % model.predict([[12]]))
>> Predict 12 inch cost:$13.68上述代码中 sklearn.linear_model.LinearRegression 类是一个估计器(estimator)。 估计器依据观测值来预测结果。 在 scikit-learn 里面,所有的估计器都带有 fit() 和 predict() 方法。 fit() 用来分析模型参数,predict() 是通过 fit() 算出的模型参数构成的模型,对解释变量进行预测获得的值。 因为所有的估计器都有这两种方法,所有 scikit-learn 很容易实验不同的模型。 LinearRegression 类的 fit() 方法学习下面的一元线性回归模型:
plt = runplt()
X = [[6],[8],[10],[14],[18]]
y = [[7],[9],[13],[17.5],[18]]
model = LinearRegression()
model.fit(X,y)
X2 = [[0], [10], [14], [25]]
y2 = model.predict(X2)
plt.plot(X, y, 'k.')
plt.plot(X2, y2, 'g-')
plt.show()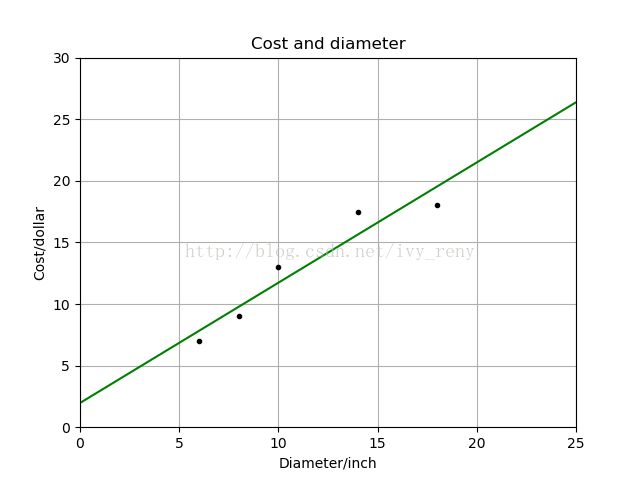
带成本函数的模型拟合评估
由若干参数生成的回归直线。 如何判断哪一条直线才是最佳拟合呢?
一元线性回归拟合模型的参数估计常用方法是普通最小二乘法(ordinary least squares )或线性最小二乘法(linear least squares)。 首先,我们定义出拟合成本函数,然后对参数进行数理统计。
成本函数(cost function)也叫损失函数(loss function),用来定义模型与观测值的误差。 模型预测的价格与训练集数据的差异称为残差(residuals)或训练误差(training errors)。 后面会用模型计算测试集,那时模型预测的价格与测试集数据的差异称为预测误差(prediction errors)或训练误差(test errors)。模型的残差是训练样本点与线性回归模型的纵向距离,如下图所示:
model = LinearRegression()
model.fit(X,y)
X2 = [[0], [10], [14], [25]]
y2 = model.predict(X2)
plt.plot(X, y, 'k.')
plt.plot(X2, y2, 'g-')
# 残差预测值
yr = model.predict(X)
for idx, x in enumerate(X):
plt.plot([x,x], [y[idx], yr[idx]], 'r-')
plt.show()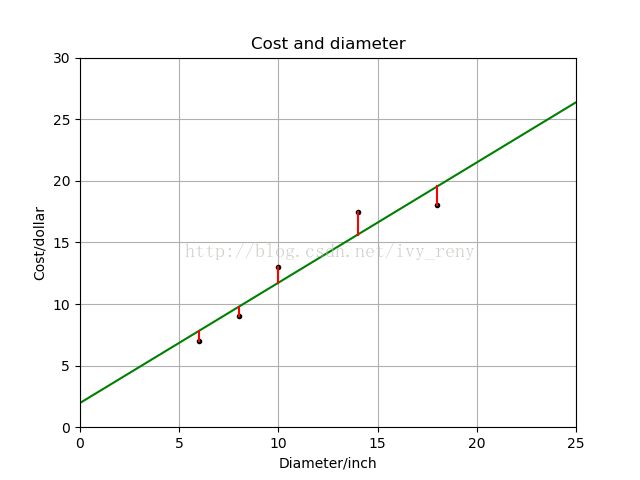
import numpy as np
print("残差平方和:%.2f" %np.mean((model.predict(X) - y)**2))解一元线性回归的最小二乘法
通过成本函数最小化获得参数,先求相关系数b。 按照频率论的观点,首先需要计算 x 的方差和 x 与 y 的协方差。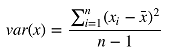
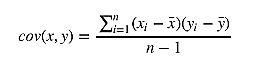

α = 12.9 − 0.9762931034482758 × 11.2 = 1.9655172413793114
这样就通过最小化成本函数求出模型参数了。 把匹萨直径带入方程就可以求出对应的价格了,如 11 英寸直径价格 $12.70,18 英寸直径价格 $19.54
print(np.var(X, ddof=1))模型评估
前面用学习算法对训练集进行估计,得出了模型的参数。 如何评价模型在现实中的表现呢?现在假设有另一组数据,作为测试集进行评估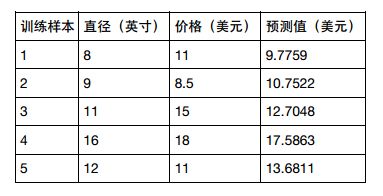

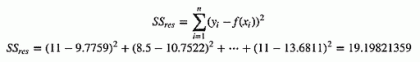
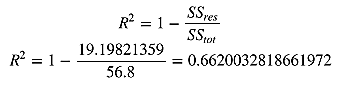
model = LinearRegression()
model.fit(X,y)
X_test = [[8], [9], [11], [16], [12]]
y_test = [[11], [8.5], [15], [18], [11]]
SStot = np.sum((y_test-np.mean(y_test))**2)
SSres = np.sum((y_test-model.predict(X_test))**2)
print("SStot=",SStot)
print("SSres=",SSres)
print("R2=", 1-SSres/SStot)
print("model score=", model.score(X_test, y_test))
>> SStot=56.8
SSres=19.1980
R2=0.66200
model score=0.66200多元线性回归
可以看出匹萨价格预测的模型 R 方值并不显著。 如何改进呢?匹萨的价格其实还会受到其他因素的影响。 比如,匹萨的价格还与上面的辅料有关。 让我们再为模型增加一个输入变量。 用一元线性回归已经无法解决了,我们可以用更具一般性的模型来表示,即多元线性回归
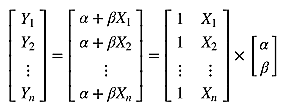
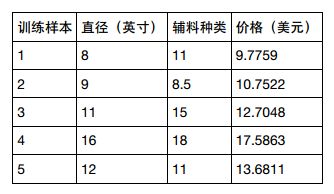
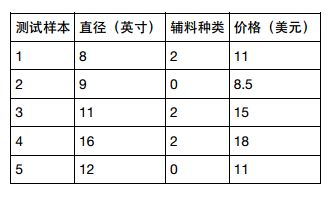
同时要升级测试集数据:
学习算法评估三个参数的值:两个相关因子和一个截距。可以通过矩阵运算来实现,因为矩阵没有除法运算,所以用矩阵的转置运算和逆运算来实现:
![]()
from numpy.linalg import inv
from numpy import dot, transpose
X = [[1,6,2],[1,8,1],[1,10,0],[1,14,2],[1,18,0]]
y = [[7],[9],[13],[17.5],[18]]
print(dot(inv(dot(transpose(X),X)),dot(transpose(X),y)))
>> [[1.1875][1.01041667][0.39583333]]利用矩阵的方法实现,可以得到同样的结果:
from numpy import *
xMat = mat(X)
yMat = mat(y)
xTx = xMat.T*xMat
print(xTx)
if linalg.det(xTx)==0.0:
print("The matrix is singular")
else:
ws = xTx.I * (xMat.T*yMat)
print(ws)更新价格预测模型
from numpy.linalg import inv
from numpy import dot, transpose
import numpy as np
from sklearn.linear_model import LinearRegression
X = [[6,2],[8,1],[10,0],[14,2],[18,0]]
y = [[7],[9],[13],[17.5],[18]]
model = LinearRegression()
model.fit(X,y)
X_test = [[8,2], [9,0], [11,2], [16,2], [12,0]]
y_test = [[11], [8.5], [15], [18], [11]]
predictions = model.predict(X_test)
for i, prediction in enumerate(predictions):
print("Predicted: %s, Target: %s" %(prediction, y_test[i]))
print("R2=%.2f"%model.score(X_test, y_test))
>> Predicted: [10.06250019], Target: [11]
Predicted: [10.28125019], Target: [8.5]
Predicted: [13.09375019], Target: [15]
Predicted: [18.14583353], Target: [18]
Predicted: [13.31250019], Target: [11]
R2=0.77多项式回归
下面用多项式回归,一种特殊的多元线性回归方法,增加了指数项( 次数大于 1)。 现实世界中的曲线关系全都是通过增加多项式实现的,其实现方式和多元线性回归类似。 本例还用一个输入变量,匹萨直径。 用下面的数据对两种模型做个比较: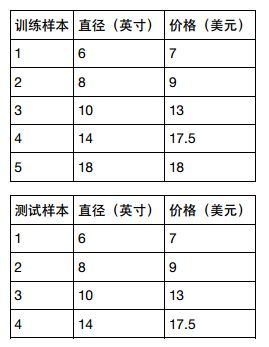
二次回归(Quadratic Regression),即回归方程有个二次项,公式如下:
model = LinearRegression()
model.fit(X_train,y_train)
xx = np.linspace(0,26,100)
yy = model.predict(xx.reshape(-1,1))
plt = runplt()
plt.plot(X_train, y_train, 'k.')
plt.plot(xx,yy)
quadratic_featurizer = PolynomialFeatures(degree=2)
X_train_quadratic = quadratic_featurizer.fit_transform(X_train)
X_test_quadratic = quadratic_featurizer.transform(X_test)
model_quadratic = LinearRegression()
model_quadratic.fit(X_train_quadratic, y_train)
xx_quadratic = quadratic_featurizer.transform(xx.reshape(-1,1))
plt.plot(xx, model_quadratic.predict(xx_quadratic), 'r-')
cubic_featurizer = PolynomialFeatures(degree=3)
X_train_cubic = cubic_featurizer.fit_transform(X_train)
X_test_cubic = cubic_featurizer.transform(X_test)
model_cubic = LinearRegression()
model_cubic.fit(X_train_cubic, y_train)
xx_cubic = cubic_featurizer.transform(xx.reshape(-1,1))
plt.plot(xx, model_cubic.predict(xx_cubic))
plt.show()
print("一元线性回归R2=", model.score(X_test, y_test))
print("二次回归 R2=", model_quadratic.score(X_test_quadratic, y_test))
print("三次回归 R2=", model_cubic.score(X_test_cubic, y_test))
>> 一元线性回归R2=0.8097
二次回归R2=0.8675
三次回归R2=0.8357
可以看出,三次拟合的 R 方值更低,虽然其图形经过了更多的点, 可以认为这是拟合过度(overfitting)的情况。 这种模型并没有从输入和输出中推导出一般的规律,而是记忆训练集的结果,这样在测试集的测试效果就不好了。
正则化
正则化(Regularization)是用来防止拟合过度的一堆方法。 正则化向模型中增加信息,经常是一种对抗复杂性的手段。 与奥卡姆剃刀原理(Occam's razor)所说的具有最少假设的论点是最好的观点类似。 正则化就是用最简单的模型解释数据。scikit-learn 提供了一些方法来使线性回归模型正则化。 其中之一是岭回归 (Ridge Regression,RR,也叫 Tikhonov regularization),通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法。 岭回归增加 L2 范数项(相关系数向量平方和的平方根)来调整成本函数(残差平方和):
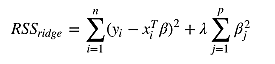
scikit-learn 也提供了最小收缩和选择算子 (Least absolute shrinkage and selection operator,LASSO),增加 L1 范数项来调整成本函数(残差平方和):
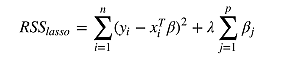
LASSO 方法会产生稀疏参数,大多数相关系数会变成 0,模型只会保留一小部分特征。 而岭回归还是会保留大多数尽可能小的相关系数。 当两个变量相关时,LASSO 方法会让其中一个变量的相关系数会变成 0,而岭回归是将两个系数同时缩小。
scikit-learn 还提供了弹性网(elastic net)正则化方法,通过线性组合 L1 和 L2 兼具 LASSO 和岭回归的内容。 可以认为这两种方法是弹性网正则化的特例。
下面对三次拟合的数据加入Lasso和岭回归正则化项。
# LASSO回归
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.05, normalize=True)
lasso.fit(X_train_cubic, y_train)
print("Lasso R2=", lasso.score(X_test_cubic, y_test))
#岭回归
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=0.05, normalize=True)
ridge.fit(X_train_cubic, y_train)
print("Ridge R2=", ridge.score(X_test_cubic, y_test))
>>三次回归R2=0.8357
Lasso R2=0.8482
Ridge R2=0.8358梯度下降法拟合模型
前面的内容全都是通过最小化成本函数来计算参数的:![]()
这里 X 是输入变量矩阵,当变量很多(上万个)的时候, 右边第一项计算量会非常大。 另外,如果右边第一项行列式为 0,即奇异矩阵,那么就无法求逆矩阵了。 这里我们介绍另一种参数估计的方法,梯度下降法(gradient descent)。 拟合的目标并没有变,我们还是用成本函数最小化来进行参数估计。
梯度下降法被比喻成一种方法,一个人蒙着眼睛去找从山坡到溪谷最深处的路。 他看不到地形图,所以只能沿着最陡峭的方向一步一步往前走。 每一步的大小与地势陡峭的程度成正比。 如果地势很陡峭,他就走一大步,因为他相信他仍在高处,还没有错过溪谷的最低点。 如果地势比较平坦,他就走一小步。 这时如果再走大步,可能会与最低点失之交臂。 如果真那样,他就需要改变方向,重新朝着溪谷的最低点前进。 他就这样一步一步的走啊走,直到有一个点走不动了,因为路是平的了,于是他卸下眼罩,已经到了谷底深处。
通常,梯度下降算法是用来评估函数的局部最小值的。 我们前面用的成本函数如下:
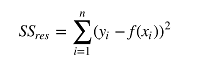
可以用梯度下降法来找出成本函数最小的模型参数值。 梯度下降法会在每一步走完后,计算对应位置的导数,然后沿着梯度(变化最快的方向)相反的方向前进, 总是垂直于等高线。需要注意的是,梯度下降法来找出成本函数的局部最小值。 一个三维凸(convex)函数所有点构成的图像一个碗,碗底就是唯一局部最小值。 非凸函数可能有若干个局部最小值,也就是说整个图形看着像是有多个波峰和波谷。 梯度下降法只能保证找到的是局部最小值,并非全局最小值。 残差平方和构成的成本函数是凸函数,所以梯度下降法可以找到全局最小值。
梯度下降法的一个重要超参数是步长(learning rate),用来控制蒙眼人步子的大小,就是下降幅度。 如果步长足够小,那么成本函数每次迭代都会缩小,直到梯度下降法找到了最优参数为止。 但是,步长缩小的过程中,计算的时间就会不断增加。 如果步长太大,这个人可能会重复越过谷底,也就是梯度下降法可能在最优值附近摇摆不定。
如果按照每次迭代后用于更新模型参数的训练样本数量划分,有两种梯度下降法。批量梯度下降(Batch gradient descent)每次迭代都用所有训练样本。 随机梯度下降(Stochastic gradientdescent,SGD)每次迭代都用一个训练样本,这个训练样本是随机选择的。 当训练样本较多的时候,随机梯度下降法比批量梯度下降法更快找到最优参数。 批量梯度下降法一个训练集只能产生一个结果。 而 SGD 每次运行都会产生不同的结果。 SGD 也可能找不到最小值,因为升级权重的时候只用一个训练样本。 它的近似值通常足够接近最小值,尤其是处理残差平方和这类凸函数的时候。
下面用 scikit-learn 的 SGDRegressor 类来计算模型参数。 它可以通过优化不同的成本函数来拟合线性模型,默认成本函数为残差平方和。 本例中,我们用波士顿住房数据的 13 个解释变量来预测房屋价格:
import numpy as np
from sklearn.datasets import load_boston
from sklearn.linear_model import SGDRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import cross_val_score
from sklearn.cross_validation import train_test_split
data = load_boston()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target)
X_scaler = StandardScaler()
y_scaler = StandardScaler()
X_train = X_scaler.fit_transform(X_train)
y_train = y_scaler.fit_transform(y_train.reshape(-1,1))
X_test = X_scaler.transform(X_test)
y_test = y_scaler.transform(y_test.reshape(-1,1))
model = SGDRegressor(loss='squared_loss')
scores = cross_val_score(model, X_train, y_train, cv=5)
print("交叉验证R方值:", scores)
print("交叉验证R方均值:", np.mean(scores))
model.fit(X_train,y_train)
print("测试集R方值:", model.score(X_test, y_test))