RocketMQ高并发读写
RocketMQ的并发读写能力扛住了2016年双十一,每秒17.5万笔订单的创建(单笔订单衍生出N条消息,实际tps是17.5*n 万),下面对其高并发读写原理进行探讨。主要体现在两方面:客户端收发消息,服务器接收消息并持久化(重点)。
客户端(RocketMQ-client)
1,客户端发送消息有负载均衡,客户端内存中保存着当前所有的服务器列表,每次发送都切换一台服务器发送消息,使得每台服务器接收的消息量尽量均衡,避免热点问题。
2,发送代码为线程安全,当Producer实例就绪之后,完全可以死循环发送消息。一般业务方都会有N个数据源实例,所以从数据源方面就保证高并发写能力。
3,消费者端负载均衡集群消费模式下,同一个ID的所有消费者实例平均消费该Topic的所有队列。
服务器端(Broker)
服务端的高并发读写主要利用Linux操作系统的PageCache特性,通过Java的MappedByteBuffer直接操作PageCache。MappedByteBuffer能直接将文件直接映射到内存,其实就是Map把文件的内容被映像到计算机虚拟内存的一块区域,这样就可以直接操作内存当中的数据而无需操作的时候每次都通过I/O去物理硬盘写文件的。
这里先介绍RocketMQ的消息存储结构:由commitLog和consume queue 两部分组成。
commitLog
1,commitLog是保存消息元数据的地方,所有消息到达Broker后都会保存到commitLog文件。
这里需要强调的是所有topic的消息都会统一保存在commitLog中,举个例子:当前集群有TopicA, TopicB,这两个Toipc的消息会按照消息到达的先后顺序保存到同一个commitLog中,而不是每个Topic有自己独立的commitLog。
2,每个commitLog大小上限为1G,满1G之后会自动新建CommitLog文件做保存数据用。
3,CommitLog的清理机制:
- 按时间清理,rocketmq默认会清理3天前的commitLog文件;
- 按磁盘水位清理:当磁盘使用量到达磁盘容量75%,开始清理最老的commitLog文件。
4,文件地址:${user.home}/store/${commitlog}/${fileName}
ConsumerQueue:
1,ConsumerQueue相当于CommitLog的索引文件,消费者消费时会先从ConsumerQueue中查找消息的在commitLog中的offset,再去CommitLog中找元数据。如果某个消息只在CommitLog中有数据,没在ConsumerQueue中, 则消费者无法消费,Rocktet的事务消息就是这个原理。
2,consumequeue的数据结构包含3部分:
- 消息在commitLog文件实际偏移量(commitLogOffset)
- 消息大小
- 消息tag的哈希值
3,文件地址:${user.home}/store/consumequeue/${topicName}/${queueId}/${fileName}
得益于以上的数据结构,MQ在写数据过程是顺序写盘,读数据过程是跳跃读盘(尽量命中PageCache)。
消息顺序写
在单台服务器上,MQ元数据都落在单个文件上(即commitLog),大量数据IO都在顺序写同一个commitLog,满1G了再写新的,真正意义上的顺序写盘,再加上MQ默认是累计4K才强制从PageCache中刷到磁盘(缓存),所以高并发写性能突出。
消息跳跃读
MQ读取消息依赖系统PageCache,PageCache命中率越高,读性能越高,Linux平时也会尽量预读数据,使得应用直接访问磁盘的概率降低。
当客户端向Broker拉取消息时,Broker上系统读文件过程如下:
1,检查要读的数据是否在上次预读的cache中;
2,若不在cache,操作系统从磁盘中读取对应的数据页,并且系统还会将该数据页之后的连续几页(一般三页)也一并读入到cache中,再将应用需要的数据返回给应用。此情况操作系统认为是跳跃读取,属于同步预读。
3,若命中cache,相当于上次缓存的内容有效,操作系统认为顺序读盘,则继续扩大缓存的数据范围,将之前缓存的数据页往后的N页数据再读取到cache中,属于异步预读。
系统给cache的定义了一个数据结构,命名为window,window由 当前要读取的内容 + 预读取的内容(group)组成。
下面结合下图举例说明:
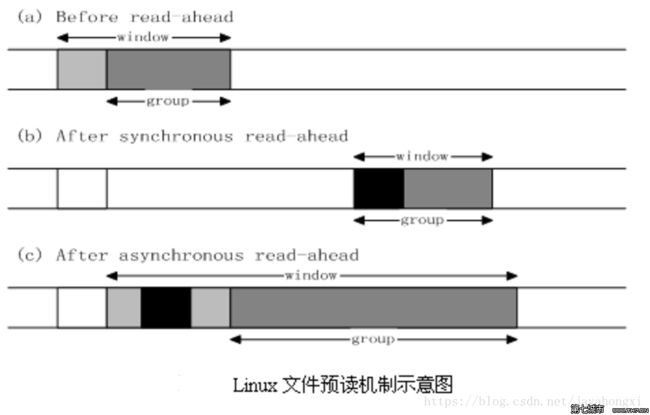
- a状态:操作系统等待应用读请求时的缓存状态。
- b状态:客户端发起读操作,broker发现所读数据不在Cache中,即不在前次预读的group中,则表明文件访问不是顺序访问(场景有可能是不消费中间的某部分消息,直接消费最新的消息),系统采用同步预读,直接从磁盘中读取页面+缓存页到内存。
- c状态:客户端继续发起读操作,系统发现所读数据在Cache中,则表明前次预读命中,操作系统把预读group扩大一倍,并让底层文件系统读入group中剩下尚不在Cache中的文件数据块,异步预读。
所以Broker的机器需要大内存,尽量缓存足够多的commitLog,让Broker读写消息基本在PageCache中操作。在运行时,如果数据量非常大,可以看到broker的进程占用内存比较多,其实大部分是被缓存住的commitlog。
缓存清理机制(PageCache)
Linux会缓存尽量多的消息数据到内存中,提高读数据缓冲命中率。当内存不够时,还是要清理没用的数据,将清理的空间用以缓存新的内容,这整个过程,Linux用一个双向链表来管理,如下图:
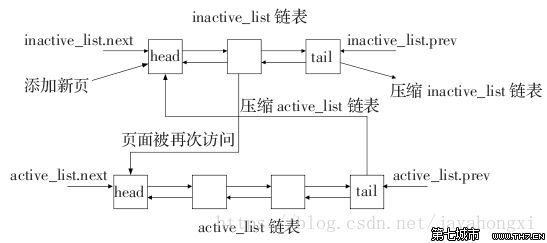
inactive_list代表访问冷数据,active_list代表访问热数据,新分配的数据页先链入到inactive_list头部,当其被引用时再将其移到active_list的头部。
当内存不足时,系统首先从尾部开始反向扫描 active_list并将状态不是referenced的项链入到inactive_list的头部,然后系统反向扫描inactive_list,如果所扫描的项的处于合适的状态就回收该项,直到回收了足够数目的Cache项,这就是系统回收内存的过程。
这里需要注意一点,如果内存回收速度比应用写缓存的速度慢,会导致写缓存的线程一直等待,体现到RocketMQ上就是写消息RT很高,这就是 “毛刺问题”。这时就需要结合GC参数和系统内核参数进行调整,此处不对此展开说明了。
demo演示:
git clone https://github.com/apache/rocketmq.git
创建配置文件conf.properties
rocketmqHome=/Users/javahongxi/github/rocketmq/distribution
namesrvAddr=127.0.0.1:9876
mapedFileSizeCommitLog=52428800
mapedFileSizeConsumeQueue=30000
-c conf.properties
依次启动NamesrvStartup,BrokerStartup,Consumer,Producer
扩展 https://github.com/apache/rocketmq-externals
rocketmq扩展:https://github.com/javahongxi/incubator-rocketmq-externals.git
rocketmq扩展:https://github.com/javahongxi/incubator-rocketmq-externals.git