SpringBatch+SpringBoot+MySql的简单应用
Batch俗称批处理。
现在任何一个互联网产品,随着长时间的积累,数据的会随着时间的推移会增长到海量。对于这些海量数据,任何企业应用或者产品都需要在对于关键数据中进行批量处理来操作业务逻辑。
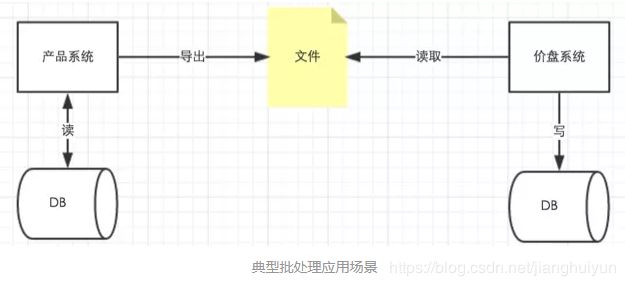
典型的批处理应用有如下几个特点:
1)自动执行,根据系统定制的工作步骤自动完成
2)数据量大,少则百万,多则千万甚至上亿
3)定时执行,例如每天执行,每周执行或者每月执行
从这些特点可以看出,批处理的整个流程可以明显的分为3大阶段
1)读取数据,数据可以来自文件,数据库,或者消息队列等等
2)处理数据,处理读取的数据并且形成输出结果,如银行对账系统的资金对账处理
3)写数据,将输出结果写入文件,数据库或者消息队列。
回归正题:
Spring Batch是一个轻量级的框架,完全面向Spring的批处理框架,用于企业级大量的数据读写处理系统。以POJO和Spring 框架为基础, 包括日志记录/跟踪,事务管理、 作业处理统计工作重新启动、跳过、资源管理等功能。
Spring Batch官网是这样介绍的自己:一款轻量的、全面的批处理框架,用于开发强大的日常运营的企业级批处理应用程序。
框架主要有以下功能:
- Transaction management(事务管理)
- Chunk based processing(基于块的处理)
- Declarative I/O(声明式的输入输出)
- Start/Stop/Restart(启动/停止/再启动)
- Retry/Skip(重试/跳过)
如果你的批处理程序需要使用上面的功能,那就大胆地使用它吧。
一图胜千言,如下是对整个框架的概览:

框架一共有5个主要角色:
- JobRepository是用户注册Job的容器,就是存储数据的地方,可以看做是一个数据库的接口,在任务执行的时候需要通过它来记录任务状态等等信息。
- JobLauncher是任务启动器,通过它来启动任务,可以看做是程序的入口。
- Job代表着一个具体的任务。
- Step代表着一个具体的步骤,一个Job可以包含多个Step(想象把大象放进冰箱这个任务需要多少个步骤你就明白了)。
- Item就是输出->处理->输出,一个完整Step流程。
废话不多说,上代码:
1、新建数据库springbatch,执行如下sql:
CREATE TABLE `t_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`address` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`nation` VARCHAR(255) DEFAULT null,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME NOT NULL,
START_TIME DATETIME DEFAULT NULL ,
END_TIME DATETIME DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME,
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME NOT NULL ,
END_TIME DATETIME DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME,
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);2、新建springboot项目,引入maven依赖,pom文件如下:
org.springframework.boot
spring-boot-starter-batch
org.hsqldb
hsqldb
org.hibernate
hibernate-validator
org.springframework.boot
spring-boot-starter-web
mysql
mysql-connector-java
org.springframework.boot
spring-boot-starter-data-jpa
org.springframework.boot
spring-boot-starter-jdbc
org.springframework.boot
spring-boot-starter-test
test
org.springframework.batch
spring-batch-test
test
org.projectlombok
lombok
1.18.4
3、application.yml配置文件如下:
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3309/springbatch?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
main:
allow-bean-definition-overriding: true
batch:
job:
enabled: true
names: importJob,importJob2
4、在resource目录下新建user.csv文件用作数据源,内容如下:
王某某,111,汉族,北京
李某莫,212,汉族,上海
张丹丹,133,回族,甘肃
大幅度,111,汉族,深圳
是的发送,132,汉族,石家庄5、新建对应的POJO类:
import lombok.Data;
import javax.validation.constraints.Size;
/**
* @Description:
* @Author devin.jiang
* @CreateDate 2019/5/11 21:34
*/
@Data
public class UserBean {
private Integer id;
@Size(min = 2,max = 4)
private String name;
private String address;
private String nation;
private Integer age;
}6、新建自定义Validate验证类:
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.batch.item.validator.Validator;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Component;
import javax.validation.ConstraintViolation;
import javax.validation.Validation;
import javax.validation.ValidatorFactory;
import java.util.Set;
/**
* @Description:
* @Author devin.jiang
* @CreateDate 2019/5/11 21:34
*/
@Component
public class CsvBeanValidator implements Validator,InitializingBean {
private javax.validation.Validator validator;
@Override
public void afterPropertiesSet() throws Exception {
ValidatorFactory validatorFactory = Validation.buildDefaultValidatorFactory();
validator =validatorFactory.usingContext().getValidator();
}
@Override
public void validate(T t) throws ValidationException {
Set> constraintViolations = validator.validate(t);
if(constraintViolations.size()>0){
StringBuilder message = new StringBuilder();
for (ConstraintViolation constraintViolation : constraintViolations) {
message.append(constraintViolation.getMessage()+"\n");
}
throw new ValidationException(message.toString());
}
}
} 7、新建Processor处理类
import cn.fish.springbatch.bean.UserBean;
import org.springframework.batch.item.validator.ValidatingItemProcessor;
import org.springframework.batch.item.validator.ValidationException;
/**
* @Description:
* @Author devin.jiang
* @CreateDate 2019/5/11 21:34
*/
public class CsvItemProcessor extends ValidatingItemProcessor {
@Override
public UserBean process(UserBean item) throws ValidationException {
super.process(item);
if(item.getNation().equals("汉族")){
item.setNation("01");
}else {
item.setNation("02");
}
return item;
}
} 8、新建JobListener类
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.stereotype.Component;
/**
* @Description:
* @Author devin.jiang
* @CreateDate 2019/5/11 21:34
*/
@Component
public class CsvJobListner implements JobExecutionListener {
long startTime;
long endTime;
@Override
public void beforeJob(JobExecution jobExecution) {
startTime = System.currentTimeMillis();
System.out.println("任务处理开始");
}
@Override
public void afterJob(JobExecution jobExecution) {
endTime = System.currentTimeMillis();
System.out.println("任务结束");
System.out.println("耗时:"+(endTime-startTime)+"ms");
}
}
9、新建Batch配置配
import cn.fish.springbatch.bean.UserBean;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.launch.support.SimpleJobLauncher;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.repository.support.JobRepositoryFactoryBean;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.batch.item.validator.Validator;
import org.springframework.batch.support.DatabaseType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.transaction.PlatformTransactionManager;
import javax.sql.DataSource;
/**
* @Description:
* @Author devin.jiang
* @CreateDate 2019/5/11 21:34
*/
@Configuration
@EnableBatchProcessing
public class CsvBatchConfig {
@Autowired
DataSource dataSource;
@Autowired
PlatformTransactionManager platformTransactionManager;
@Bean
public ItemReader reader() throws Exception{
FlatFileItemReader reader = new FlatFileItemReader<>();
reader.setName("readCsv");
reader.setResource(new ClassPathResource("user.csv"));
DefaultLineMapper defaultLineMapper = new DefaultLineMapper<>();
reader.setLineMapper(defaultLineMapper);
DelimitedLineTokenizer tokenizer ;
defaultLineMapper.setLineTokenizer((tokenizer =new DelimitedLineTokenizer()));
tokenizer.setNames(new String[]{"name","age","nation","address"});
BeanWrapperFieldSetMapper setMapper;
defaultLineMapper.setFieldSetMapper((setMapper = new BeanWrapperFieldSetMapper<>()));
setMapper.setTargetType(UserBean.class);
return reader;
}
@Bean
public ItemProcessor processor(){
CsvItemProcessor processor = new CsvItemProcessor();
processor.setValidator(csvBeanValidator());
return processor;
}
@Bean
public ItemWriter writer(){
JdbcBatchItemWriter writer = new JdbcBatchItemWriter<>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider());
String sql = "insert into person (name,age,nation,address) values (:name,:age,:nation,:address)";
writer.setSql(sql);
writer.setDataSource(dataSource);
return writer;
}
@Bean
public JobRepository jobRepository() throws Exception{
JobRepositoryFactoryBean jobRepositoryFactoryBean = new JobRepositoryFactoryBean();
jobRepositoryFactoryBean.setDataSource(dataSource);
jobRepositoryFactoryBean.setTransactionManager(platformTransactionManager);
jobRepositoryFactoryBean.setDatabaseType(DatabaseType.MYSQL.name());
return jobRepositoryFactoryBean.getObject();
}
@Bean
public SimpleJobLauncher jobLauncher()throws Exception{
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository());
return jobLauncher;
}
@Bean
public Job importJob(JobBuilderFactory jobs, Step step1){
return jobs.get("importJob")
.incrementer(new RunIdIncrementer())
.flow(step1)
.end()
.listener(csvJobListner())
.build();
}
@Bean
public Job importJob2(JobBuilderFactory jobs, Step step1,Step step2,Step step3,Step step4){
return jobs.get("importJob2")
.incrementer(new RunIdIncrementer())
.flow(step1)
.next(step2)
.next(step3)
.next(step4)
.end()
.listener(csvJobListner())
.build();
}
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory,ItemReader reader,ItemWriter writer,
ItemProcessor processor){
return stepBuilderFactory.get("step1")
.chunk(1)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public Step step2(StepBuilderFactory stepBuilderFactory,ItemReader reader,ItemWriter writer,
ItemProcessor processor){
return stepBuilderFactory.get("step2")
.chunk(1)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public Step step3(StepBuilderFactory stepBuilderFactory,ItemReader reader,ItemWriter writer,
ItemProcessor processor){
return stepBuilderFactory.get("step3")
.chunk(1)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public Step step4(StepBuilderFactory stepBuilderFactory,ItemReader reader,ItemWriter writer,
ItemProcessor processor){
return stepBuilderFactory.get("step4")
.chunk(1)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public CsvJobListner csvJobListner(){
return new CsvJobListner();
}
@Bean
public Validator csvBeanValidator(){
return new CsvBeanValidator();
}
} 10、最后运行SpringbatchApplication主程序入口类
运行截图如下:
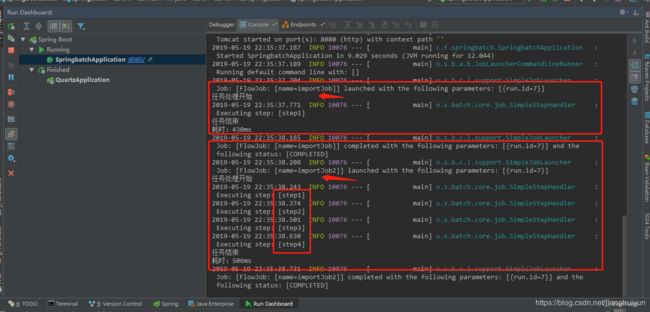
代码git地址:https://github.com/380682174/springBootBuket
参考:https://www.xncoding.com/2017/08/01/spring/sb-batch.html
https://www.jianshu.com/p/6f350131d6a7
https://gitee.com/dataMaNong/springbatch
https://zhuanlan.zhihu.com/p/46744316