FAIR 开放了一个大规模数据集
朋友们,我是床长! 如需转载请标明出处:http://blog.csdn.net/jiangjunshow
随着深度学习的进一步发展,我们对数据集的依赖也越来越强。就在最近,FAIR 开放了 LVIS,一个大规模细粒度词汇集标记数据集,该数据集针对超过 1000 类物体进行了约 200 万个高质量的实例分割标注,包含 164k 大小的图像。

LVIS 数据集概述
计算机视觉的核心目标是赋予算法智能描述图像的能力;目标检测是规范的图像描述任务,这在应用程序中实用性很强,并且可以直接在现有设置中进行基准测试。而物体检测器的精确度已经得到了显著提高,并且已经开发出新功能,例如:图像分割和 3D 表示。
从少数例子中有效地学习是机器学习和计算机视觉中一个重要的开放性问题,从科学和实践的角度来看,这个机会是非常令人振奋的。但要开放这个领域进行实证研究,需要一个合适的、高质量的数据集和基准。我们的目标就是通过设计和收集 LVIS,一个用于大规模词汇量对实例分割研究基准数据集来实现这一新的研究方向,并在最终完成 164k 大小的包含 1000 类物体的约 200 万个高质量的实力分割标注图像数据集。

图 1 示例注释。我们提供了一个新的数据集lvis,用于在 1000+ 类别图像中基准化大型词汇实例分割,以及找出具有挑战性的稀有对象长尾分布
我们的标注流程从一组图像开始,这些图像在未知标记类别的情况下所收集。我们让注标器完成迭代对象定位过程,并找出图像中自然存在的长尾分布,来代替机器学习算法对自动化数据标记过程。
我们设计了一个众包标注流程,可以收集大型数据集,同时还可以生成高质量的标注。标注质量对于未来的研究非常重要,因为相对粗糙的标注,例如 COCO 数据集,它会限制算法对于标注预测质量的提高。与 COCO 和 ADE20K 相比,我们的数据标注具有更大的重叠面积和更好的边界连续性。
为了构建这个数据集,我们采用了评估优先的设计原则。该原则指出,我们应该首先确定如何执行定量评估,然后再设计和构建数据集收集流程,以满足评估所需数据的需求。我们选择类似与 COCO 风格的实例分段评测基准,并且使用了相同风格的平均精度(AP)度量标准。
虽然 COCO 的任务和指标连续性降低了数据集设计难度,但这个任务选择中依旧存在着直接的技术挑战:当一个物体可以合理地用多个类别标记时,我们如何公平地评估检测器性能?当使用来自 1000 多个类别的 164k 标注图像时,我们如何使标注工作量变得可行?
解决这些挑战的基本设计选择是构建联合数据集:由大量较小的组成数据集联合形成的单个数据集,每个数据集看起来与单个类别的传统目标检测数据集完全相同。每个小数据集为单个类别提供详尽标注的基本保证,即该类别的所有实例都被标注。多个组成数据集可以重叠,因此图像中的单个对象可以用多个类别标记。此外,由于详尽的标注保证仅存在于每个小数据集中,因此我们不需要对整个联合数据集的所有类别进行详尽地标注,这将大大减少标注工作量。至关重要的是,在测试时每个图像相对于组成数据集的子集衡量标准是算法未知的,因此它必须进行预测,使得所有类别都将被评估。
目前,我们已经标注了两次的图像 val 子集。我们也标注了额外的 77k 图像(在 train,val 和 test 之间划分),占最终数据集的~50%;我们将其称为 LVIS v0.5。第一个基于 v0.5 的 LVIS 挑战赛将在 ICC 2019 年的 COCO 研讨会上举行。
相关数据集
数据集塑造了研究人员研究的技术问题,因此也是科学发现的途径。我们目前在图像识别方面的成功很大程度上归功于 MNIST(http://yann.lecun.com/exdb/mnist/ )、BSDS、Caltech 101、PASCAL VOC、ImageNet 和 COCO 等先驱数据集。这些数据集支持开发检测边缘、执行大规模图像分类以及通过边界框和分割蒙版定位对象的算法。它们还被用于发现重要的方法,如卷积网络、残余网络和批量标准化 。LVIS 的灵感来自这些以及其他相关数据集,包括关注街景(Cityscapes 和 Mapillary)和行人(Caltech Pedestrians)的数据集。

图 2 lvis示例注释(为了清晰起见,每个图像对应一个类别);更多信息请参阅http://www.lvisdataset.org/explore
数据集设计
我们遵循评估优先设计原则:在任何数据收集之前,我们精确定义了将执行的任务以及如何评估的标准。这个原则很重要,因为在评估大型词汇数据集上的检测器时会出现技术挑战,而这些问题在数据类别很少时不会发生。我们必须首先解决这些问题,因为它们对数据集的结构有深远的影响,我们将在下面讨论。
任务和评估准则
任务和指标。我们的数据集基准是实例分割任务,即给定一组固定的已知类别,然后设计一种算法。当出现之前没有的图像时,该算法将为图像中出现的每个类别中的每个实例输出一个标注以及类别标签与置信度分数。而给定算法在一组图像上的输出,我们使用 COCO 数据集中的定义和实现计算标注平均精度(AP)。
评估挑战。像 PASCAL VOC 和 COCO 这样的数据集使用手动选择的成对不相交类别,例如:当标注汽车时,如果检测到的目标是盆栽植物或沙发,则不会出现错误。但增加类别数量时,则不可避免会出现其他类型的成对关系,例如:部分视觉概念的重叠、父子分类关系的界定、同义词识别等。如果这些关系没有得到妥善解决,那么评估标准将是不公平的。
例如:大多数玩具不是鹿,大多数鹿不是玩具,但是玩具鹿却既是玩具也是鹿。如果检测器输出鹿的同时物体仅标记为玩具,则目标检测算法为错误的标记;如果汽车仅被标记为 vehicle,而算法输出 car,则也是错误的标注。因此,提供公平的基准对于准确反映算法性能非常重要。
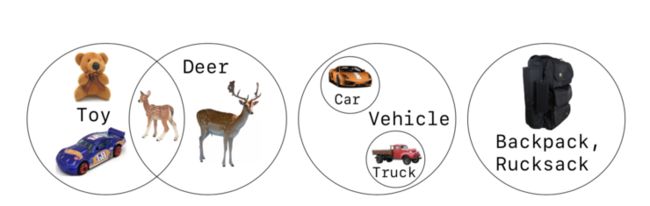
图 3 从左到右的类别关系:部分视觉概念的重叠、父子分类关系、等效(同义词)关系;这意味着单个对象可能具有多个有效标签;目标探测器的公平评估必须考虑到多个有效标签的问题
当 GT 标注缺少目标的一个或多个真实标签时,则会出现这些问题。如果算法恰好预测了其中一个正确但不完整的标签,将得到错误的结果。而现在,如果所有目标都是详尽且正确地标记了所有类别,那么问题就可以解决了。
联合数据集
解决问题的关键在于:评估标准不要求我们详尽地标注所有图像与所有类别。相反,对于每个类别 c,必须存在整个数据集 D 的两个不相交的子集,存在图像的正例集 Pc⊆D,使得 Pc 中的所有 c 的类别都被标注;存在图像负例集 Nc⊆D,使得在这些图像中的任何一个中都不包含 c 的实例。给定类别 c 的这两个子集,Pc∪Nc 可用于执行 c 的标准 COCO 样式 AP 评估。评估 oracle 仅在图像子集上的类别 c 上判断算法,其中 c 已被详尽地标注;如果检测器报告图像上的类别 c 的检测结果 i 不属于 Pc∪Nc,则不评估检测。通过将每类别集合汇集到单个数据集中,D =∪c(Pc∪Nc),最后我们得出联合数据集的概念。
联合数据集是通过多个小数据集联合构建大规模的完整数据集,而每一个子数据集则聚焦于某个单一类别的传统数据集。在标注过程中,每一个小数据集将集中标注某一个特定的类别,并将图中某个特定类别的所有信息进行标注;这一方法也有助于大大减少工作量。
最后,我们发现一些未公开测试标注的正集和负集数据集,所以算法没有关于在这些图像中评估的辅助信息;因此,算法需要对每个测试图像中的所有类别进行最佳预测。
评估细节
挑战评估服务器将仅返回整体 AP,而不是每类别 AP,这是因为:
-
避免露出测试集中存在的类别信息;
-
鉴于长尾类别很少,所以在某些情况下评估的例子则更少,这使得 AP 类别不稳定;
-
通过对大量类别求平均,整体类别平均 AP 具有较低的方差,使其成为排序算法的稳健度量。
非穷举标注(Non-Exhaustive Annotations)。我们收集了一个图像级别的布尔标签 eci,指示图像 i∈Pc 是否在类别 c 中被详尽地标注。在大多数情况下(91%),此标志为 true,表示标注确实是详尽的。在其余情况下,图像中至少有一个未标注的实例。缺少标注通常发生在「crowds」类别中,其中存在大量实例所以我们难以进行描绘。在评估期间,我们不计算在该标签设置为 false 的图像上的类别 c 的误报。我们测量对这些图像的记忆:期望检测器预测标记实例的准确分割标注。
层次结构。在评估期间,我们将所有类别视为相同;我们对层次关系没有做任何特殊处理。为了得到最佳表现,对于每个检测到的物体 o,检测器应输出最具体的正确类别以及所有更一般的类别,例如:独木舟应标记为独木舟和船。
同义词。将同义词分成不同类别的联合数据集是有效的,但是不必要分得很细致;我们避免使用 WordNet 将同义词拆分为单独的类别。具体而言,在 LVIS 中每个类别 c 都是一个 WordNet 同义词,即由一组同义词和定义指定的词义。
数据集构建
数据集的标注主要分为了六个阶段,包括目标定位、穷尽标记、实例分割、验证、穷尽标注验证以及负例集标注。

图 4 数据集标注流程的六个阶段
第 1 阶段的目标定位是一个迭代过程,其中每个图像被访问可变次数。在第一次访问时,要求标注器用一个点标记一个对象,并使用自动完成文本输入将其命名为类别 c∈V;在每次后续访问时,显示所有先前发现的对象,并且要求标注器标记先前未标记的类别的对象,或者如果不能发现 V 中的更多类别则跳过图像;当图像被跳过 3 次时,将不再访问该图像。总结阶段 1 的输出:对于词汇表中的每个类别,我们有一组(可能是空的)图像,其中每个图像都标记了该类别的一个目标;这一步骤为每个类别 c 定义了初始正集 Pc。
阶段 2 的穷尽标记目标则是:验证阶段 1 标注和用点标记每个图像 i∈Pc 中的所有 c 实例。在这个阶段,来自阶段 1 的(i,c)对被发送到了 5 个标注器中;首先,它们显示了类别 c 的定义,并验证它是否描述了点标记的目标;如果匹配,则要求标注器标记同一类别的所有其他实例;反之,则终止第二步。因此,从第 2 阶段开始,我们为每个图像提供详尽的实例标注。
在第 3 阶段的实例分割中,我们的目标是:验证第 2 阶段中每个标记对象的类别,以及将每个标记对象从点标注升级到完整分段标注。为此,将图像 i 和标记对象实例 o 的每对(i,o)呈现给一个标注器,该标注器被要求验证 o 的类别标签是否正确,并为它绘制详细的分割标注。从第 3 阶段开始,我们为每个图像和被发现的实例对分配一个分割标注。
第 4 阶段验证时,我们的目标是验证第 3 阶段的分段标注质量。我们将每个分段显示为最多 5 个标注器,并要求它们使用量规对其质量进行评级。如果两个或多个标注器不通过,那么我们将该实例重新排队以进行阶段 3 分段;如果 4 个标注者同意它是高质量的,我们接受该分割标注。我们在第 3 和第 4 阶段之间迭代共四次,每次只重新标注被拒绝的实例。总结第 4 阶段的输出(在第 3 阶段来回迭代之后):我们有超过 99%的所有标记对象的高质量分割标注。
第 5 阶段是穷尽标注验证,它将确定最终的正例集。我们通过询问标注器是否在 i 中存在类别 c 的任何未分段实例来执行此操作。我们要求至少 4 个标注器同意标注是详尽的,而只要有两个人不通过,我们就会将详尽的标注标记 eci 标记为 false。
在最后阶段的负例集标注,它将为词汇表中的每个类别 c 收集负集 Nc。我们通过随机采样图像 i∈D\ Pc 来做到这一点,其中 D 是数据集中的所有图像。对于每个采样图像 i,如果图像 i 中出现类别 c,我们最多询问 5 个标注器,其中任何一个标注器显示不通过,我们则拒绝该图像。否则将其添加到 Nc。我们采样过程将持续到负例集 Nc 达到数据集中图像的 1%的目标大小。从阶段 6 开始,对于每个类别 c∈V,我们具有负例集 Nc,使得该类别不出现在 Nc 中的任何图像中。
词汇建构
我们使用迭代过程构建词汇表 V,该过程从大型超级词汇表开始,并使用目标定位过程(阶段 1)将其缩小。我们将从 WordNet 中选择的 8.8k 同义词进行明确词汇的删除(例如:专有名词),然后找到了高度具体的常用名词交集。
这产生了一个穷尽的具体组合,因此能得到一些视觉上的入门级同义词;然后,我们将目标定位应用于具有针对这些超级词汇表自动完成的 10k COCO 图像。这将减少词汇量,然后我们再次重复这一过程,最后,我们执行次要的手动编辑,得到了包含 1723 个同义词的词汇表,这也是可以出现在 LVIS 中的类别数量的上限。
LVIS 数据集标注结果
通过使用 LVIS,我们能够将很多图像中对于某一类别图像进行完整的标注,包括一些小的、被遮盖的、难以辨认的,都能够通过这一方法实现标注。

图 5 LVIS 上标注得到的分类数据展示(1)
在 LVIS 的网站上,我们可以看到大量的标注结果,包括一些小工具(剪刀、桶),小配饰(太阳镜、腰带),餐盘里的黄瓜,甚至是披萨上的菠萝粒,都能够完整的标注出来。

图 6 LVIS 上标注得到的分类数据展示(2)
正如 FAIR 自己所说:LVIS 是一个新的数据集,旨在首次对实例分割算法进行严格的研究,它可以识别不同对象类别的大量词汇(> 1000)。虽然 LVIS 强调从少数例子中学习,但数据集并不小;它将跨越 164k 图像并标记~2 百万个对象实例。每个对象实例都使用高质量的蒙版进行分割,该蒙版超过了相关数据集的标注质量。