2. 基于 Mac 平台 VMware 虚拟机的 Spark 安装(2)- 安装 Hadoop
接上篇文章,1. 基于 Mac 平台 VMware 虚拟机的 Spark 安装(1)- 安装 CentOS
https://blog.csdn.net/jiangmengya1/article/details/87379865
这篇文章里,2. 基于 Mac 平台 VMware 虚拟机的 Spark 安装(2)- 安装 Hadoop
以下所有操作, root 账户
一、安装 Hadoop (基于 master 机器)
在官网下载 hadoop-2.6.5.tar.gz 到 master 机器的 /app/soft 目录
使用命令 # tar -zxvf hadoop-2.6.5.tar.gz 进行解压缩
二、配置 Hadoop (基于 master 机器)
1. 配置 HADOOP 环境变量配置文件 /app/soft/hadoop-2.6.5/etc/hadoop/hadoop-env.sh
将 Hadoop 环境变量修改成上篇文章中Java 的安装根目录

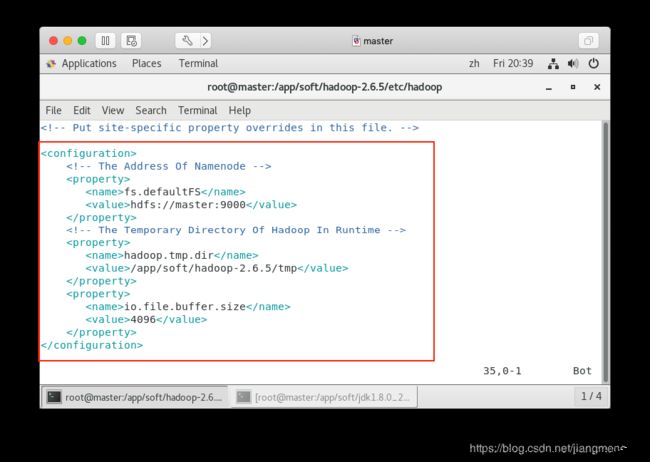
2. 配置 HADOOP 核心配置项配置文件 /app/soft/hadoop-2.6.5/etc/hadoop/core-site.xml
将该文件中增加如下配置内容
3. 首先在目录 /app/soft/hadoop-2.6.5 目录下创建两个子目录
/app/soft/hadoop-2.6.5/hdfs/name
/app/soft/hadoop-2.6.5/hdfs/data
然后,使用上面生成的这两个目录
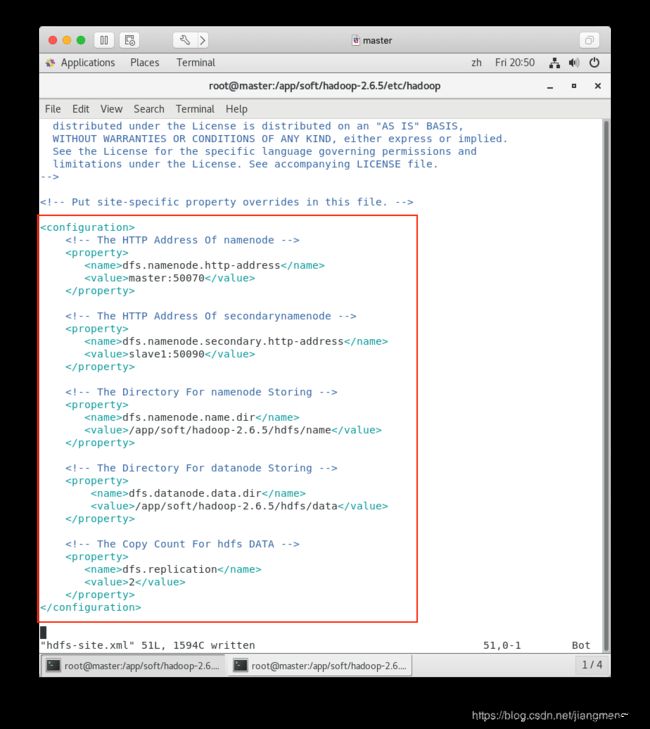
配置 HDFS 文件系统配置文件 /app/soft/hadoop-2.6.5/etc/hadoop/hdfs-site.xml
4. 首先,执行命令 # cp /app/soft/hadoop-2.6.5/etc/hadoop/mapred-site.xml.template /app/soft/hadoop-2.6.5/etc/hadoop/mapred-site.xml
由模板生成 Map-Reduct 配置文件 mapred-site.xml
然后配置生成的 mapred-site.xml
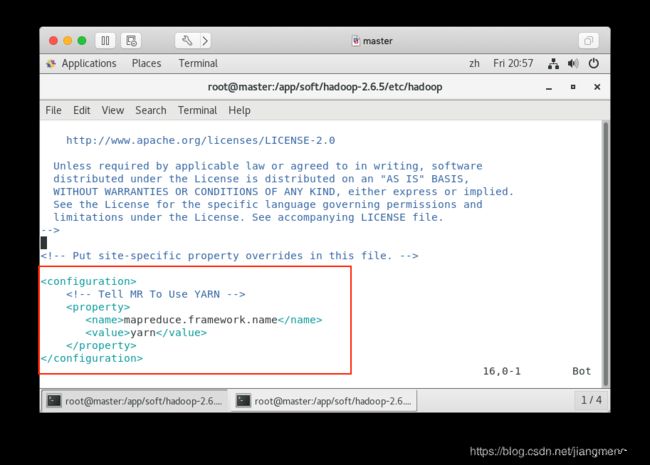
5. 配置资源管理 Yarn 配置文件 /app/soft/hadoop-2.6.5/etc/hadoop/yarn-site.xml

6. 配置 masters 文件 /app/soft/hadoop-2.6.5/etc/hadoop/masters
在该文件中增加主机名称 master

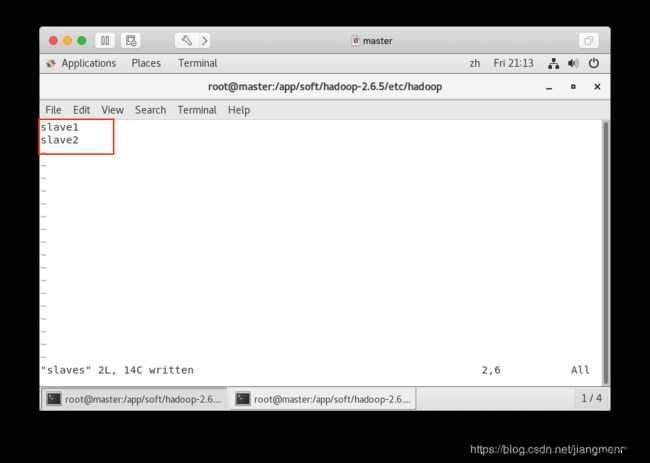
7. 配置 slaves 文件 /app/soft/hadoop-2.6.5/etc/hadoop/slaves
修改该文件内容为主机名称 slave1、slave2
至此、Hadoop 的主要配置完成。
三、部署 Hadoop (基于 master 机器、slave1 机器、slave2 机器)
至此、master 机器上的 Hadoop 配置完成,
现在、在 master 机器上执行如下两条命令,将配置 OK 的 Hadoop 部署到 slave1 机器和 slave2 机器上
# scp -r /app/soft/hadoop-2.6.5 root@slave1:/app/soft
# scp -r /app/soft/hadoop-2.6.5 root@slave2:/app/soft
分别编辑 master 机器、slave1 机器、slave2 机器的 /etc/profile 文件,增加如下配置
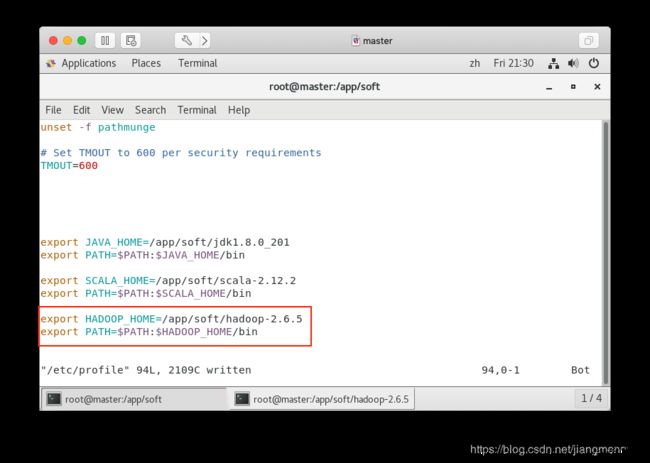
保存后,执行命令 # source /etc/profile 使配置生效
四、格式化 Hadoop
部署完成后,在使用 Hadoop 之前,还需要对其进行格式化
在 master 机器上,执行如下命令
# /app/soft/hadoop-2.6.5/bin/hadoop namenode -format
等待片刻,会如图提示格式化成功

在 master 机器上、执行启动 Hadoop 的命令
# /app/soft/hadoop-2.6.5/sbin/start-all.sh
五、文件上传测试
上传一个本地文件到 HDFS 上 , 并查看上传是否成功

六、Map-Reduce 程序测试
执行命令,并查看执行结果
# hadoop jar /app/soft/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /input/README.txt /output
这里,读取文件 /input/README.txt , 进行单词计数,输出统计结果到 /output
等待命令执行完毕
查看单词统计结果

七、其他
对应于启动 Hadoop 命令: # /app/soft/hadoop-2.6.5/sbin/start-all.sh
关闭 Hadoop 的命令是: # /app/soft/hadoop-2.6.5/sbin/stop-all.sh