asm基础——nasm使用简介
nasm编译
编译命令如下:
nasm −f [−o 参数介绍:
-f:用来指定编译出来的.o文件的格式。下面是nasm支持的格式,可以通过nasm -hf来查看:

要查看本机支持的格式,可以先进入nasm所在的目录,并执行file nasm命令来查看:

结合两张图,可以确定本机编译时需要指定的格式是macho64。
-o:用来指定编译后的文件的名称。如果不加参数,则使用原来的.asm的文件名,后缀则根据-f指定的文件格式有所不同,windows系统是.obj,unix系统是.o。
-l:编译时生成list文件,里面包含代码和对应的机器码等内容。
-M:打印编译时的依赖文件,它有各种不同形式的-Mx,这里不多做介绍,光是-M的话会直接打印出来。
-Ox:优化代码,x表示优化的级别,0表示不优化,1-n优化等级依次提高。
-d:定义一个宏,比如:
nasm myfile.asm −dFOO=100-u:取消宏定义,比如:
nasm myfile.asm −dFOO=100 -uFOO-E:不进行编译,只是展开所有的宏,如果没有接参数来指定文件,则展开后的代码直接打印出来,用-o可以指定展开后的文件。
其它还有很多的参数,不一一介绍了,可以参考nasmdoc.pdf文档。
nasm中的分段
nasa中使用section关键字来分段,后面接的参数有:
1).data,用来定义常量;
2).bbs,用来存放变量;
3).text,用来存放代码;
具体的使用例子可以参考http://blog.csdn.net/jiangwei0512/article/details/51629146。
另外,nasm通过global来指定入口。
nasm中的有效地址:
在nasm中,有效地址都需要用[]括起来以获取其中的内容,下面是一个例子:
var dw 0x55AA
mov ax, [qword var]对于64位的编译系统,这里必须要加上qword,否则编译会报错。在nasmdoc.pdf有如下的解释:
The only instructions which take a full 64−bitdisplacementis loading or storing, usingMOV,AL,AX,EAXorRAX(but no other registers) to an absolute 64−bit address. Since this is a relatively rarely used instruction(64−bit code generally uses relative addressing), the programmer has to explicitly declare the displacement size asQWORD:
这里除了qword,也可以有byte、word等,表示的实际上是一种偏移,比如[byte eax],就是指大小为0的byte偏移。
nasm中的伪指令:
1)声明已初始化的变量:
db 0x55
dw 0x55AA
dd 0x55AAAA552)声明未初始化的变量:
buffer1: resb 64
buffer2: resw 32
buffer3: resq 16使用nasm -f bin的格式编译,得到的二进制如下:

3)包含二进制文件的伪指令:incbin;
4)定义常量:equ:
message db 'hello, world'
msglen equ $−message5)重复执行指令或者声明数据:times:
例如下面的代码:
times 16 db 0x5A得到的结果如下:

常用预处理指令:
所有预处理指令都以%开头。
1)单行宏定义指令%define:
%define ctrl 0x1F &
%define param(a,b) ((a)+(a)*(b))
mov byte [param(2,ebx)], ctrl 'D'使用%define会遇到一些问题,比如下面的例子:
%define TRUE 1
%define FALSE TRUE
%define TRUE 0
val1: db FALSE
%define TRUE 1
val2: db FALSE使用nasm -f bin的格式进行编译,得到的结果用vim -b打开,并通过:%!xxd -g 1来查看,得到的结果如下:

产生这结果的原因是nasm中单行的宏只有在使用的时候才会展开,对于val1,FALSE的值等于TRUE,而此时TRUE的值是0,所以得到的值也是0;同样的就得到了val2的值是1。
如果需要在单行宏定义的时候就展开宏,可以使用%xdefine这个伪指令,这里的x就表示expend,“展开”。
同样是上面的例子,使用%xdefine代替%define,得到的结果就是

使用%xdefine可以立即展开后面接的代码中的宏。
还有一种方法可以得到相同的结果,就是使用%[xxx],它显式地用来展开宏。
%define TRUE 1
%define FALSE %[TRUE] ; 注意这里
%define TRUE 0
val1: db FALSE
%define TRUE 1
val2: db FALSE它跟使用上例使用%xdefine产生相同的结果。
无论是%define还是%xdefine都有一个加i的版本:%idefine和%ixdefine,这里的i表示case insensitive,不区分大小写。
2)用于连接宏字符串和参数的%+,下面是一个例子:
%define BDASTART 400h
%define BDA(x) BDASTART + tBIOSDA. %+ x
struc tBIOSDA
.COM1addr resw 1
.COM2addr resw 1
endstruc
mov ax, BDASTART + tBIOSDA.COM1addr
mov bx, BDA(COM1addr)两句mov指令传递的数据是一致的,后者使用了宏定义,看起来更清晰,这就是因为使用了%+的缘故。下面是是宏展开的结果:
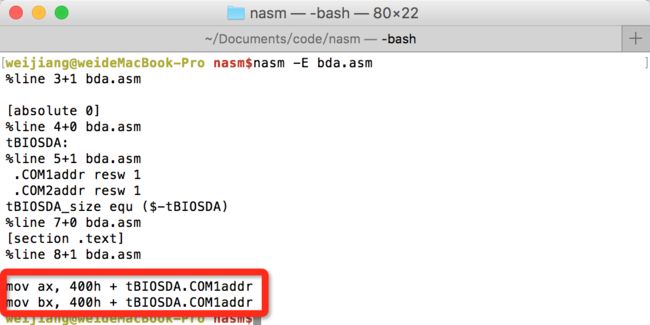
需要注意一点,这里的%+之后有一个空格。
3)表示宏名字的%?和%??。
4)%undef,用来取消宏。
5)%assign与%define相似,用来处理单行的宏,但要求宏不带参数,值是数值。
6)对于多行的宏,使用%macro,下面是一个例子:
%macro prologue
push rax
push rbx
%endmacro
section .text
prologue宏展开后的结果:
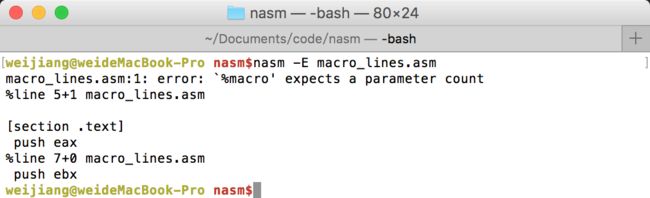
从结果看展开是没有问题的,但是有一个报错,这是因为nasm中使用%macro时需要指定参数个数,上例中没有参数,那么就是0,正确的代码应该是这样的:
%macro prologue 0
push rax
push rbx
%endmacro
section .text
prologue当参数个数不为0,则在宏内部使用%1、%2等来访问参数,下面是一个例子:
%macro prologue 2
push %1
push %2
%endmacro
section .text
prologue rax, rbx两个prologue相当于是一个重载。默认的指令似乎也可以重载,但是最好不要。
上例中一是要注意%1%2等使用,另外还需要注意rax,rbx作为参数的传递,两个参数之间使用逗号分隔。但是存在一种情况是单个参数之间本身就包含逗号,这个时候就可以通过用{}将参数包围起来的方法,下面是一个例子:
%macro silly 2
%2: db %1
%endmacro
section .data
silly {0xd, 0xa}, clrf这里定义了一个回车,第一个参数包含两个值。
上面的代码还有另一种写法,这种写法使用了"Greedy Parameters",它类似于c语言中的不定参数,修改上面的代码:
%macro silly 2+
%1: db %2
%endmacro
section .data
silly clrf, 0xd, 0xa这里的2+就是"Greedy Parameters"的声明方式。上例还需要了一下参数的位置,因为"Greedy Parameters"需要放在最后。
在多行宏里面可以添加标签,且这个标签只在当前的宏中有效,因此多次调用该宏不会因为标签问题受到影响。
使用%%xx来定义宏中的标签,xx是标签名,下面是一个例子:
%macro retz 0
jnz %%skip
ret
%%skip:
%endmacro
section .text
retz
retz展开后就可以看出为什么标签不会冲突了:

nasm中的宏还可以指定默认参数,格式如下:
%macro prologue 0-1 rax
push %1
%endmacro
section .text
prologue上例中的0-1表示宏可以有0个或者1个参数,如果是0个,则使用后接的默认的rax。
上例还比较简单,下面可能稍微复杂一点:
%macro prologue 1-3 rax, rbx
上面的代码表示,prologue必须要带至少一个参数,最多3个参数,如果第2、3个参数不存在,则分别由rax和rbx代替。
还有几个特殊的参数可以在多行宏中使用:
a. %0表示参数的个数;
b. %rotate类似shell脚本中的shift,用来遍历参数;
最后,%unmacro用来取消多行宏定义。
7)nasm中可以使用的条件判断:
%if
; some code which only appears if is met
%elif
; only appears if is not met but is
%else
; this appears if neither nor was met
%endif