字体文件反反爬-- 起点中文网
工作中遇到一个,以前没有遇到的问题是,网站把重要的数字都转换成 其他的东西
爬取网站https://book.qidian.com/info/1011454545 起点女生网
通过审查元素是这样的:
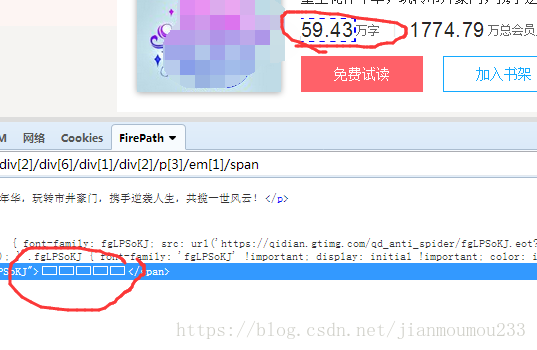
查看网页源码:
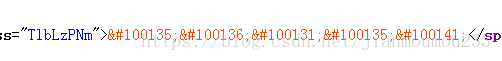
通过搜索查找,原来网站做了反扒的措施,正好前几天看个关于这样的文章,教怎样反爬的。通过搜索引擎查找相关的资料,原来有人做过类似的反反爬,猫眼,汽车之家都是这种方式.
参考:
1. Python爬虫杂记 - 字体文件反爬(二)https://www.jianshu.com/p/0e2e1aa6d270
2. Python爬虫杂记 - 字体文件反爬(一)https://www.jianshu.com/p/5a626b3422ac
2. 思路:
我本来按着上面的来的,原来不行,主要是网站不同。那我就换个思路,我找到源码里面𘜧𘜨𘜣𘜧𘜭 对应的数字不就行了,不用去解析字体库了,多简单啊。
我分析了几个网页,发现是动态的 例如2对应的是𘜧 可是在另外一个网页就不是了。原来他们的字体库是变化的

![]()
网页不用,链接不同,真坑。所以上面的,找对应关系就不行了,还得去解析 字体库;
那就找到字体库的链接,通过分析链接,发现前面的链接都是一样的,就是后面不一样,找到不同部分拼接就省事多了
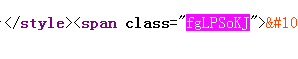
只需要找到这个就可以了
3. 起点这个网站真坑:
采坑之路开始:
查看源码:

用python解析网页出来变成了:
"\U00018721\U00018725\U00018726\U0001871e\U00018729\U00018729"
真坑啊。
4. 解析font 库
font_type = "zNUreUJW"
font_url = "https://qidian.gtimg.com/qd_anti_spider/%s.woff" % font_type
woff = requests.get(font_url).content
with open('fonts.woff', 'wb') as f:
f.write(woff)
online_fonts = TTFont('fonts.woff')
online_fonts.saveXML("text.xml")打开text.xml看一下里面的东西
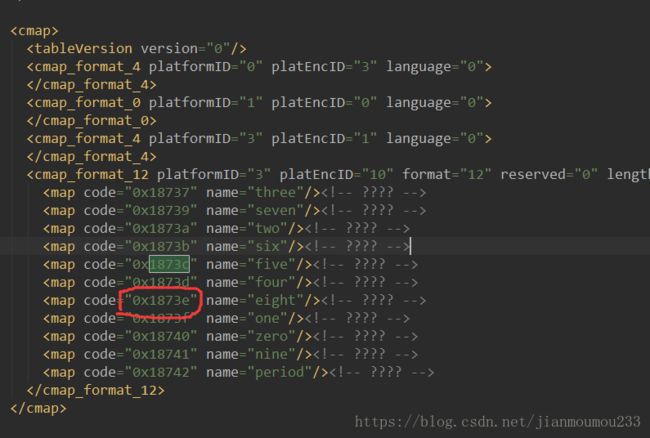
这个值可能和上面的截图对应不上,也从侧面说明了,这个值是变化的.
解决了这个对应关系往下继续;
想要把"\U00018721\U00018725\U00018726\U0001871e\U00018729\U00018729"分割出来,真是费了老大的劲了详情查看分析之路:https://blog.csdn.net/jianmoumou233/article/details/81234882
5. 继续:
with open('fonts.woff', 'wb') as f:
f.write(woff)
online_fonts = TTFont('fonts.woff')
online_fonts.saveXML("text.xml")
_dict = online_fonts.getBestCmap()
print(_dict)结果是这样的
![]()
和
然后写:
_dic = {
"six": "6",
"three": "3",
"period": ".",
"eight": "8",
"zero": "0",
"five": "5",
"nine": "9",
"four": "4",
"seven": '7',
"one": "1",
"two": "2"
}
就可以转成数字了。到此大体的分析结束了.
6.结果:
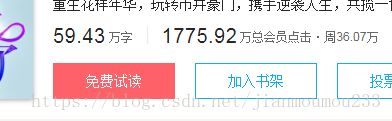
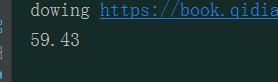
完美解决.
附代码,不给代码的分析都是耍流氓:
import os
import requests
from fontTools.ttLib import TTFont
from parsel import Selector
def download(urls, rain_num=2):
print("dowing", urls)
heads = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'max-age=0',
'Proxy-Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58'
}
try:
html = requests.get(urls, headers=heads, verify=True).text
except Exception as e:
print("Downing error", e.reason)
html = None
if rain_num > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
return download(urls, rain_num - 1)
return html
def get_num():
url = 'https://book.qidian.com/info/1011454545'
body = download(url)
xbody = Selector(text=body)
font = get_font(xbody)
text = xbody.xpath(
"//div[contains(@class,'book-information')]/div[contains(@class,'book-info')]/p/em[1]/span/text()").extract_first()
print(jiexi(text, font))
def get_font(xbody):
path = os.path.dirname(os.path.realpath(__file__))
font_type = xbody.xpath(
"//div[contains(@class,'book-information')]/div[contains(@class,'book-info')]/p/em[1]/span/@class").extract_first()
font_url = "https://qidian.gtimg.com/qd_anti_spider/%s.woff" % font_type
woff = requests.get(font_url).content
with open(path + '/fonts.woff', 'wb') as f:
f.write(woff)
online_fonts = TTFont(path + '/fonts.woff')
online_fonts.saveXML("text.xml")
_dict = online_fonts.getBestCmap()
return _dict
def jiexi(text, _dict):
_dic = {
"six": "6",
"three": "3",
"period": ".",
"eight": "8",
"zero": "0",
"five": "5",
"nine": "9",
"four": "4",
"seven": '7',
"one": "1",
"two": "2"
}
df = r"%s" % text
df = str(df.split(" "))
df = df.split("\\U000")
_df = []
for i in df:
i = i.replace("['", "").replace("']", "")
if i:
_df.append(int("0x" + i, 16))
num = list()
for i in _df:
_da = _dict.get(i)
num.append(_dic[_da])
return "".join(num)
if __name__ == '__main__':
get_num()感谢:
1. Python爬虫杂记 - 字体文件反爬(二)https://www.jianshu.com/p/0e2e1aa6d270
2. Python爬虫杂记 - 字体文件反爬(一)https://www.jianshu.com/p/5a626b3422ac