提升方法AdaBoost算法完整python代码
提升方法AdaBoost算法完整python代码
提升方法简述
俗话说,“三个臭皮匠顶个诸葛亮”,对于一个复杂的问题,一个专家的判断往往没有多个专家的综合判断来得好。通常情况下,学习一个弱学习算法比学习一个强学习算法容易得多,而提升方法研究的就是如何将多个弱学习器转化为强学习器的算法。
- 强学习算法:如果一个多项式的学习算法可以学习它,而且正确率很高,那就是强可学习的。
- 弱学习算法:如果一个多项式的学习算法可以学习它,正确率仅仅比随机猜测略好,那就是弱可学习的。
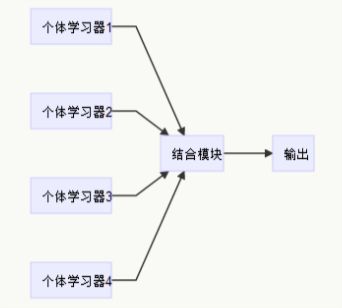
AdaBoost算法简述
AdaBoost是adaptive boosting(自适应boosting)的缩写,运行过程如下:赋予训练集中的每个样本一个权值D,一开始权值都是相等的,然后训练一个弱分类器并计算错误率,分类正确的样本会降低权重,而分类错误的样本会提高权重,接着再次根据权重训练一个弱分类器,这么做是为了让新的弱分类器在训练中更加关注未被分类正确的样本。为了综合所有弱分类器的结果,每个分类器都有一个权重α,基于错误率ε计算的。
如果某个样本被正确分类,权重更改为:
如果某个样本被分类错误,权重更改为:
直到训练错误率为0或者达到指定的训练次数为止。
单层决策树弱分类器
单层决策树(decision stump)也叫决策树桩,是一种简单的决策树,仅基于单个特征做决策。
伪代码
将最小错误率minError设为+∞
对数据集中的每一个特征(第一层循环):
对每个步长(第二层循环):
对每个不等号(第三层循环):
建立一棵单层决策树并利用加权数据集对它进行测试
如果错误率低于minError,则将当前单层决策树设为最佳单层决策树
返回最佳单层决策树
代码实现
弱分类器核心部分
from numpy import *
#通过比较阈值进行分类
#threshVal是阈值 threshIneq决定了不等号是大于还是小于
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = ones((shape(dataMatrix)[0],1)) #先全部设为1
if threshIneq == 'lt': #然后根据阈值和不等号将满足要求的都设为-1
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
#在加权数据集里面寻找最低错误率的单层决策树
#D是指数据集权重 用于计算加权错误率
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix) #m为行数 n为列数
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf #最小误差率初值设为无穷大
for i in range(n): #第一层循环 对数据集中的每一个特征 n为特征总数
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1): #第二层循环 对每个步长
for inequal in ['lt','gt']: #第三层循环 对每个不等号
threshVal = rangeMin + float(j) * stepSize#计算阈值
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#根据阈值和不等号进行预测
errArr = mat(ones((m,1)))#先假设所有的结果都是错的(标记为1)
errArr[predictedVals == labelMat] = 0#然后把预测结果正确的标记为0
weightedError = D.T*errArr#计算加权错误率
#print 'split: dim %d, thresh %.2f, thresh inequal: %s, \
# the weightederror is %.3f' % (i,threshVal,inequal,weightedError)
if weightedError < minError: #将加权错误率最小的结果保存下来
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst准备了一个简单的数据集来测试算法
#加载数据集
def loadSimpleData():
dataMat = matrix([[1.,2.1],
[2.,1.1],
[1.3,1.],
[1.,1.],
[2.,1.]])
classLabels = [1.0,1.0,-1.0,-1.0,1.0]
return dataMat,classLabels
#绘制数据集
def pltData(dataMat,classLabels):
for index,item in enumerate(dataMat): #enumrate的参数为一个可以遍历的东西,返回值为索引和该项
if classLabels[index] > 0:
plt.plot(item[0,0],item[0,1],'or') #'or' 表示 画红点
else:
plt.plot(item[0,0],item[0,1],'ob') #'ob' 表示 画蓝点
plt.show()导入数据集并绘制
dataMat, classLabels=loadSimpleData()
pltData(dataMat, classLabels)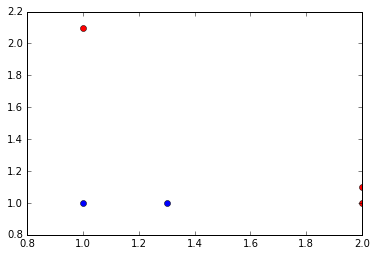
测试算法
D = mat(ones((5,1))/5)
buildStump(dataMat, classLabels, D)
完整AdaBoost算法实现
基于上面写的树桩弱分类器,实现完整的AdaBoost算法。
伪代码
对每次迭代:
利用buildStump()函数找到最佳的单层决策树
将最佳单层决策树加入到单层决策树数组
计算alpha
计算新的权重向量D
更新累计类别估计值
如果错误率等于0.0,则退出循环
代码实现
训练函数
#基于单层决策树的AdaBoost训练函数
#numIt指迭代次数 默认为40 当训练错误率达到0就会提前结束训练
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = [] #用于存储每次训练得到的弱分类器以及其输出结果的权重
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #数据集权重初始化为1/m
aggClassEst = mat(zeros((m,1))) #记录每个数据点的类别估计累计值
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#在加权数据集里面寻找最低错误率的单层决策树
#print "D: ",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#根据错误率计算出本次单层决策树输出结果的权重 max(error,1e-16)则是为了确保error为0时不会出现除0溢出
bestStump['alpha'] = alpha#记录权重
weakClassArr.append(bestStump)
#print 'classEst: ',classEst.T
#计算下一次迭代中的权重向量D
expon = multiply(-1*alpha*mat(classLabels).T,classEst)#计算指数
D = multiply(D,exp(expon))
D = D/D.sum()#归一化
#错误率累加计算
aggClassEst += alpha*classEst
#print 'aggClassEst: ',aggClassEst.T
#aggErrors = multiply(sign(aggClassEst)!=mat(classLabels).T,ones((m,1)))
#errorRate = aggErrors.sum()/m
errorRate = 1.0*sum(sign(aggClassEst)!=mat(classLabels).T)/m#sign(aggClassEst)表示根据aggClassEst的正负号分别标记为1 -1
print 'total error: ',errorRate
if errorRate == 0.0:#如果错误率为0那就提前结束for循环
break
return weakClassArr分类函数
#基于AdaBoost的分类函数
#dataToClass是待分类样例 classifierArr是adaBoostTrainDS函数训练出来的弱分类器数组
def adaClassify(dataToClass,classifierArr):
dataMatrix = mat(dataToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)): #遍历所有的弱分类器
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha']*classEst
#print aggClassEst
return sign(aggClassEst)自适应数据加载函数
#自适应数据加载函数
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t'))
dataMat = []; labelMat = []
for line in open(fileName).readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat-1): #最后一项为label
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(curLine[-1])
return dataMat,labelMat利用马疝病数据集测试算法,下载地址http://pan.baidu.com/s/1o7IcNCQ
#训练分类器
dataArr,labelArr=loadDataSet('horseColicTraining2.txt')
classifierArray = adaBoostTrainDS(dataArr,labelArr,10)
#测试
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
prediction10 = adaClassify(testArr,classifierArray)
print 1.0*sum(prediction10!=mat(testLabelArr).T)/len(prediction10)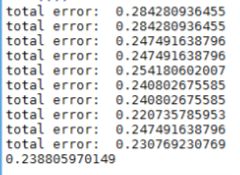
扩展
弱分类器选择
本文使用的是单层决策树,也可以使用别的分类器作为AdaBoost的弱分类器,而且作为弱分类器,简单分类器的效果会更好些。
多类别分类
可以尝试一对多的方法,训练时把某个类别视为正例,其余类都视为负例,如果一共有k类,那就训练k个AdaBoost,测试时选类别估计值最高的那一类。
参考内容
《机器学习实战》
《统计学习方法》