论文学习:《Deep Neural Networks for YouTube Recommendations》
最近在学习推荐系统的论文,仔细研读了《Deep Neural Networks for YouTube Recommendations》一文。这篇文章是2016年Youtube团队将深度学习应用到推荐系统上的一次尝试,下面详细介绍和解读下这篇文章:
《Youtube深度神经网络推荐系统》
一、 Youtube业务的需求
Youtube面临以下三方面的挑战:
规模大:用户和视频的数量都很大,传统适合小规模的算法无法满足;
更新快:对新出现的视频作出及时和合适的反馈;
噪音:YouTube上的历史用户行为由于稀疏性和各种不可观察的外部因素而不可预测,在实际中很少能获得真实的用户满意度,更多的是隐式反馈噪声信号。
二、 系统概述
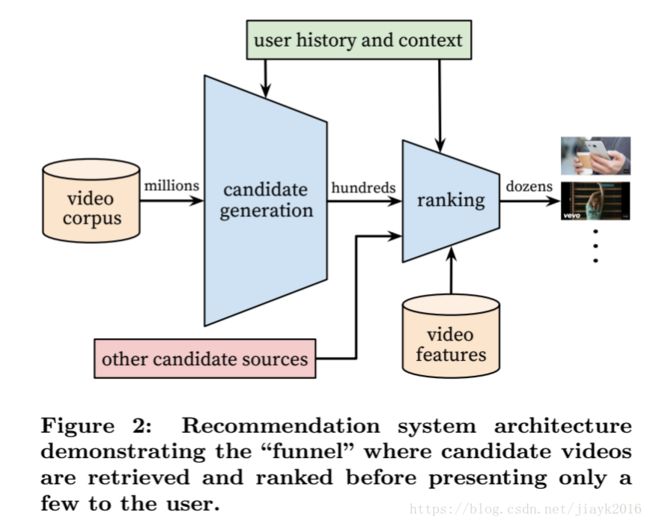
整个推荐系统的结构如下,由两个模型组成,一个是候选集生成网络(candidate generation),一个是排序网络(ranking)。候选集生成网络将用户的Youtube活动历史记录作为输入,然后从海量视频集中筛选出一小部分(数百个)视频。排序网络则使用更加丰富的描述视频和用户画像的特征,对数百个视频进行打分排名,做更精细化的推荐。
模型离线指标使用了精确度、召回率、排名损失等,线上指标考虑使用点击率、观看时间、用户参与度等。
三、 候选集生成网络
1、问题建模
论文把推荐问题建模成一个“超大规模多分类”问题,如下面公式所示:
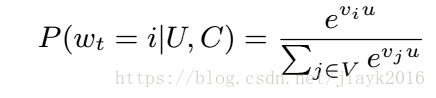
其中u为用户U的embedding表示,V为视频库集合,C是上下文信息,v_i为视频库中第i个视频的embedding表示。u和v_i为长度相等的向量,两者点积可以通过全连接层实现。
即在时刻t,在(用户U、上下文信息C)下从视频库V中精准的预测出视频i的类别(每个具体的视频视为一个类别),所以DNN的目标就是在用户信息和上下文信息为输入条件下学习用户的embedding向量u。
2、模型架构

这里说明一下,模型是把训练后的三层relu层的输出作为学习到的用户u的embedding。
3、主要特征说明
- 用户观看历史(视频ID)做embedding,取embedding向量的平均值;
- 用户历史搜索词记录做embedding;
- 用户人口学信息(如地理位置、用户登录设备)做embedding;
- 二值特征(如性别,是否登录)直接做神经网络的输入;
- 连续特征(如用户年龄);
- 还有一些数值类特征,可以利用经验知识,对其进行变换。如对视频上传时间特征进行平方操作,然后作为新的特征。
4、线上线下的训练
考虑到softmax分类的类别数非常多,为了保证一定的计算效率:
- 训练阶段,使用负样本类别采样将实际计算的类别数缩小至数千;
- 推荐(预测)阶段,忽略softmax的归一化计算(不影响结果),将类别打分问题简化为点积空间中的最近邻搜索问题,取与u最近的k个视频作为生成的候选。
5、标记和上下文选择
- 使用更广的数据源:不仅仅使用推荐场景的数据进行训练,其他场景比如搜索等的数据也要用到,这样也能为推荐场景提供一些探索;
- 为每个用户生成固定数量训练样本:在实践中发现,如果为每个用户固定样本数量上限,平等的对待每个用户,避免loss被少数active用户支配,能明显提升线上效果;
- 抛弃序列信息:在实现时去掉序列信息,对过去观看视频/历史搜索query的embedding向量进行加权平均;
- 不对称的共同浏览问题:实践发现利用上文信息预估下一次浏览的视频比利用上下文信息预估表现更佳。而实际上,传统的协同过滤类的算法,都是隐含的采用利用上下文信息预估下一次浏览的视频,忽略了不对称的浏览模式。
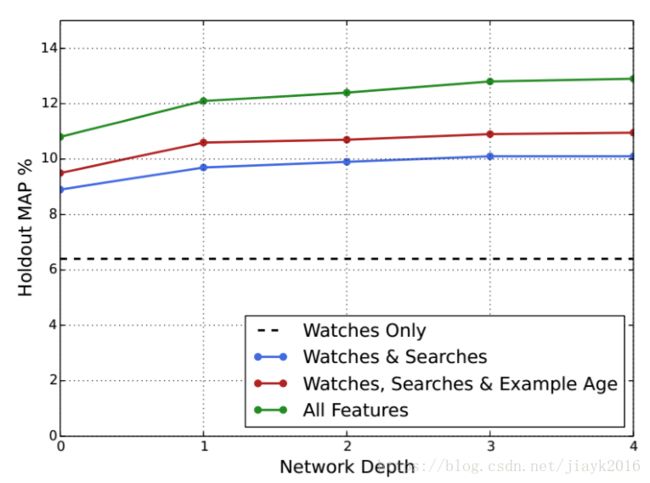
6、不同网络深度和特征的实验
- 网络构建过程,采用的经典的“tower”模式搭建网络
- 下图反映了不同网络深度(横坐标)下不同特征组合情况下的误差估计(纵坐标)
- 效果:a.增加了观看历史之外的特征很明显的提升了预测得准确率;
b.从网络深度看,随着网络深度加大,预测准确率在提升,但继续增加第四层网络已经收益不大了。

四、 排序网络
1、 模型架构

2、 主要特征
1) 特征工程
a. 论文发现最重要的信号是描述用户与商品本身或相似商品之间交互的信号,比如我们要度量用户对视频的喜欢,可以考虑用户与视频所在频道间的关系:
- 数量特征:浏览该频道的次数
- 时间特征:比如最近一次浏览该频道距离现在的时间
这两个连续特征的最大好处是具备非常强的泛化能力。另外除了这两个偏正向的特征,用户对于视频所在频道的一些页面浏览但不点击的行为,即负反馈信号同样非常重要。
b. 另外,论文还发现把Matching阶段的信息传播到Ranking阶段同样能很好的提升效果,比如推荐来源和所在来源的分数。
2) 分类特征的Embedding
NN更适合处理连续特征,因此稀疏的特别是高基数空间的离散特征需要embedding到稠密的向量中.
a.每个维度都有独立的embedding空间,实际并非为所有的id进行embedding,比如视频id,只需要按照点击排序,选择top N视频进行embedding,其余置为0向量。而对于像“过去点击的视频”这种特征,与Matching阶段的处理相同,进行加权平均即可;
b.另外一个值得注意的是,同维度不同feature采用的相同ID的embedding是共享的(比如“过去浏览的视频id”“seed视频id”),这样可以大大加速训练。
3) 归一化连续特征
a.NN对输入特征的尺度和分布都是非常敏感的
论文发现归一化方法对收敛很关键,推荐了一种排序分位归一到[0,1]区间的方法,即
![]()
其中f是分布位
b.除此之外,模型还把归一化后的x的根号√x和平方x^2作为网络输入,以期能使网络能够更容易得到特征的次线性和超线性函数。
3、建模期望观看时长
- 论文的目标是预测期望观看时长;
- 有点击的为正样本,有页面浏览无点击的为负样本,正样本需要根据观看时长进行加权。因此,训练阶段网络最后一层用的是 weighted logistic regression;
- 正样本的权重为观看时长T_i,负样本权重为1。在线上serving的预测阶段,模型采用e^x作为激活函数。
4、不同隐层的实验

上图是离线利用hold-out一天数据在不同NN网络结构下的结果。如果用户对模型预估高分的反而没有观看,论文认为是预测错误的观看时长。weighted, per-user loss就是预测错误观看时长占总观看时长的比例
论文对网络结构中隐层的宽度和深度方面都做了测试,从上图结果看增加隐层网络宽度和深度都能提升模型效果
参考文献:
[1] Covington P, Adams J, Sargin E. Deep Neural Networks for YouTube Recommendations[C]// ACM Conference on Recommender Systems. ACM, 2016:191-198.
[2] 用深度学习(DNN)构建推荐系统 - Deep Neural Networks for YouTube Recommendations论文精读
https://zhuanlan.zhihu.com/p/25343518
[3] Deep Neural Networks for YouTube Recommendations
https://blog.csdn.net/free356/article/details/79445823