案例一、估计房屋价格
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn import datasets
from sklearn.metrics import mean_squared_error, explained_variance_score #导入评估方法
from sklearn.utils import shuffle #打乱顺序
import matplotlib.pyplot as plt
#加载数据
house_data = datasets.load_boston()
# print(house_data.feature_names)
#打乱数据,random_state来控制打乱的顺序
x, y = shuffle(house_data.data, house_data.target, random_state=7)
#划分训练集和测试集
num_training = int(0.8*len(x))
x_train, y_train = x[:num_training], y[:num_training]
x_test, y_test = x[num_training:], y[num_training:]
#采用决策树回归模型
dt_regression = DecisionTreeRegressor(max_depth=4)
dt_regression.fit(x_train, y_train)
#采用adaboost回归模型
ab_regression = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4), n_estimators=400, random_state=7)
ab_regression.fit(x_train, y_train)
#决策树训练效果
y_pre_dt = dt_regression.predict(x_test)
mse = mean_squared_error(y_test, y_pre_dt) #均方误差,公式是(预测-测试)平方再开方
evs = explained_variance_score(y_test, y_pre_dt) #解释方差得分
print("\n###Decision tree performance###")
print("Mean squared error = ", round(mse, 2))
print("Explain variance score = ", round(evs, 2))
#adaBoost训练效果
y_pre_ab = ab_regression.predict(x_test)
mse = mean_squared_error(y_test, y_pre_ab)
evs = explained_variance_score(y_test, y_pre_ab)
print("##AbBoost tree performance##")
print("Mean squared error = ", round(mse, 2))
print("Explain variance score = ", round(evs, 2))
def plot_feature_importances(feature_importances, title, feature_names):
'''
#画出特征的相对重要性
:param feature_importances:
:param title:
:param feature_names:
:return:
'''
#将重要性值标准化
feature_importances = 100.0* (feature_importances / max(feature_importances))
#将得分从高到低排序
index_sorted = np.flipud(np.argsort(feature_importances))
#让x坐标轴上的标签居中
pos = np.arange(index_sorted.shape[0])+0.5
#画条形图
plt.figure()
plt.bar(pos, feature_importances[index_sorted], align='center')
plt.xticks(pos, feature_names[index_sorted])
plt.ylabel('Relative Importance')
plt.title(title)
plt.show()
plot_feature_importances(dt_regression.feature_importances_, 'Decission Tree Regressor', house_data.feature_names)
plot_feature_importances(ab_regression.feature_importances_, 'AdaBoost regression', house_data.feature_names)
结果:
###Decision tree performance###
Mean squared error = 14.79
Explain variance score = 0.82
##AbBoost tree performance##
Mean squared error = 7.64
Explain variance score = 0.91
图形:

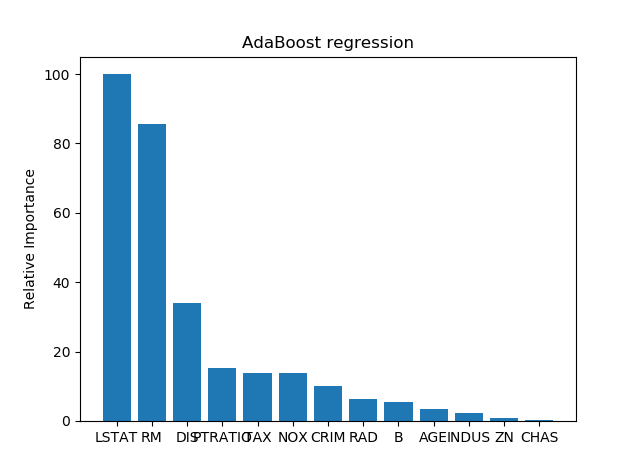
解释:采用AdaBoost算法和决策树做对比,可以看出用AdaBoost结果更好。回归决策树的最重要特征是RM,而AdaBoost最重要特征是LSTAT
涉及内容:
(1)AdaBoost算法:
点击打开链接
(2)metric
点击打开链接
(3)round(原数字,位数)函数作用是保留原数字小数点后几位
(4)feature_importances_属性是得出每个特征的占比
print(dt_regression.feature_importances_)0. 0.10473383 0. 0. 0.00460542 0.
0.20020548]
下面代码:目的是让每个特征在100范围内展示
feature_importances = 100.0* (feature_importances / max(feature_importances)) (5)
index_sorted = np.flipud(np.argsort(feature_importances))flipud():作用是让矩阵上下翻转
import numpy as np
a = [
[1,2,3],
[4,5,6],
[7,8,9]
]
m = np.array(a)
#翻转90度,k是翻转的次数
mt = np.rot90(m, k=1)
print(mt)
#左右翻转
mr = np.fliplr(m)
print(mr)
#上下翻转
md = np.flipud(m)
print(md)