Python爬虫之静态网页—中英文翻译(搜狗翻译为例)
一、使用谷歌浏览器打开搜狗翻译网页。
二、分析翻译按钮请求过程。
1、右击点击审查元素进入Network
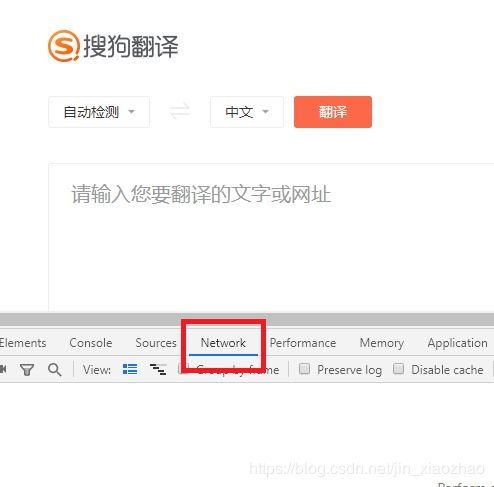
2、在翻译框内输入翻译内容,点击翻译按钮;在Method列表找到最新的POST,点击Name列表的同一行部分。
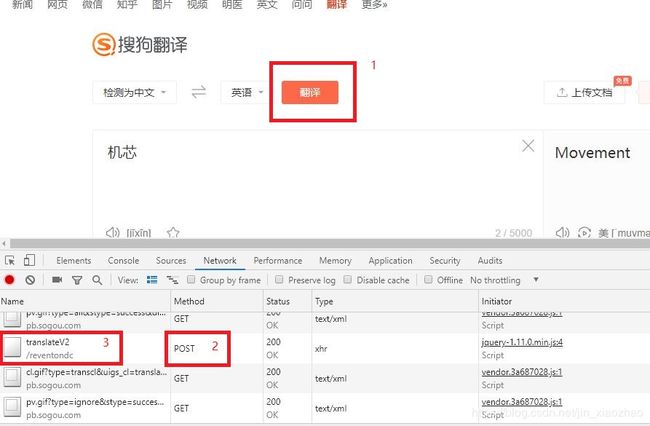
3、找到Headers中的Form Data表单。
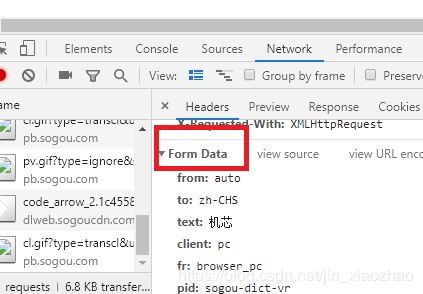
4、多次使用网页翻译功能,观察发现表单中三项有变化。
form:auto—>自动检测翻译内容的语言
to:zh-CHS—>翻译为汉译英(en代表英译汉)
uuid和s存在变化。
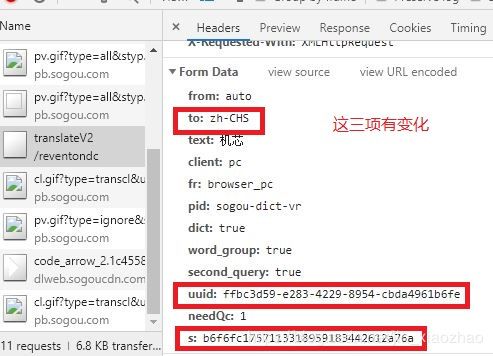
5、从请求的JS中找到uuid及s的变化规律,进行仿制。
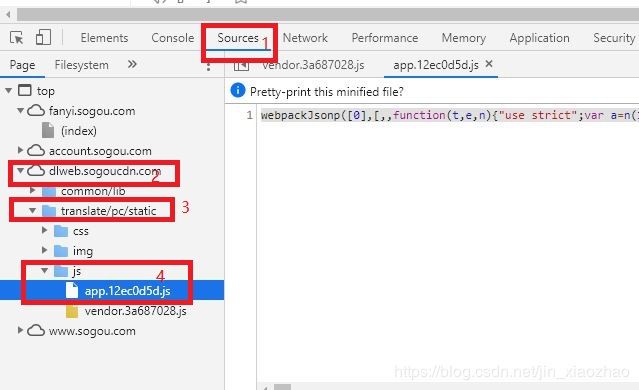
首先,在.JS的内容中进行搜索uuid,找到如下图所示的代码部分。
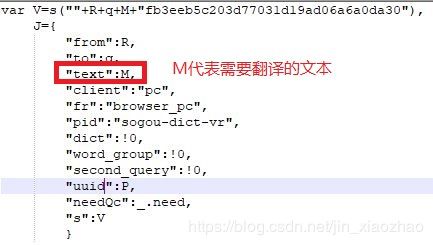
从而得到s的的构成组成。
#构建加密算法
sign = '' + 'auto' + q + content + 'fb3eeb5c203d77031d19ad06a6a0da30'
m = hashlib.md5()
m.update(sign.encode('utf-8'))搜索下图所示代码,解析uuid构成

#构建uuid
B = []
for i in range(9):
B.append(hex(math.floor((random.random() + 1) * 65536)).split('0x1')[1])
uuid = B[0] + B[1] + '-' + B[2] + '-' + B[3] + '-' + B[4] + '-' + ''.join(B[-3:])三、Python实现基本翻译功能

import urllib.request
import urllib.parse
import time
import re
import math
import random
import hashlib
import json
content = input('请输入翻译的内容:')
url = '此部分为上图中红框内网址'
head = {
'User-Agent':'此部分从下图中的相应部分查找'
}
# 判断输入是中文还是英文
zhPattern = re.compile(u'[\u4e00-\u9fa5]+') # 匹配中文
match = zhPattern.search(content) #判断用户输入的是不是中文
if match:
q = 'en'
else:
q = 'zh-CHS'
#构建uuid
B = []
for i in range(9):
B.append(hex(math.floor((random.random() + 1) * 65536)).split('0x1')[1])
uuid = B[0] + B[1] + '-' + B[2] + '-' + B[3] + '-' + B[4] + '-' + ''.join(B[-3:])
#构建加密算法
sign = '' + 'auto' + q + content + 'fb3eeb5c203d77031d19ad06a6a0da30'
m = hashlib.md5()
m.update(sign.encode('utf-8'))
#Form Data中的内容(表单内容)
data = {}
data['from'] = 'auto'
data['to'] = q #有变化
data['text'] = content#输入的翻译内容
data['client'] = 'pc'
data['fr'] = 'browser_pc'
data['pid'] = 'sogou-dict-vr'
data['dict'] = 'true'
data['word_group'] = 'true'
data['second_query'] = 'true'
data['uuid'] = uuid
data['needQc'] = 1
data['s'] = m.hexdigest()
data = urllib.parse.urlencode(data).encode('utf-8')
#访问网址
req = urllib.request.Request(url,data,head)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
#print(html)#通过分析网页内容将翻译结果提取出来
target = json.loads(html)
print('翻译结果为:%s'%(target['translate']['dit']))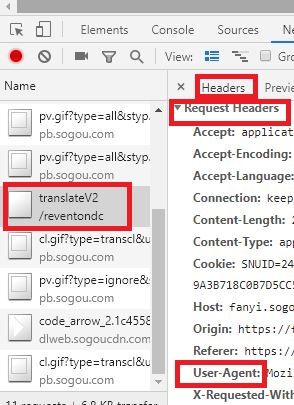
四、参考链接:https://blog.csdn.net/m0_37886429/article/details/84938045