Bert---ELMo、GPT
接上一篇:结合上下文的 word embedding — ELMo
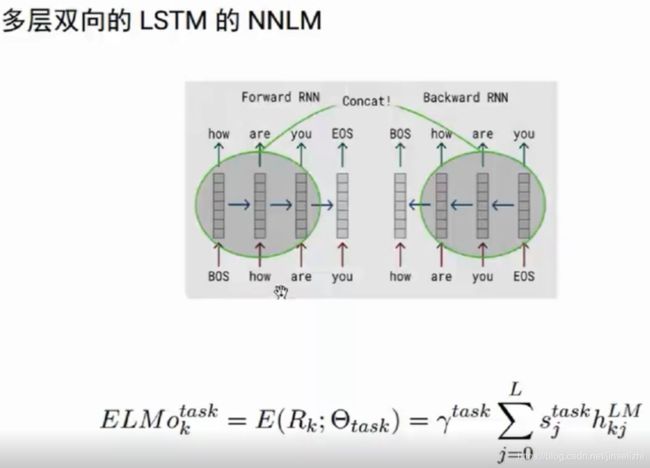
首先通过 pre-train 学习 一个语言模型(前面的预测后面的:我要去北京玩,用“我要去”预测“北京”…),
多层双向LSTM编码,上下文的
每个词都可以得到 2*n个向量(n是层数)
ELMo 是一种特征提取的方法:
通过pre-train的方法学习了 一个双向的语言模型,
来了一个句子,就可以把它变成序列的向量,而且这个向量是考虑了上下文的,做了消歧的,做了指代消解的,所以它是一种比word embedding更好的方法。
编码完了,这个向量就定住了,后面改怎么建模就怎么基于此建模。
ELMo解决和未解决的问题
ELMo 把上下文 word embedding作为特征, 毕竟无监督的语料和真实的特定任务领域的上下文还是有差距,所以并不适合特定任务。
在此基础上 OpenAI GPT 应运而生。
OpenAI GPT
两个改进:
(1)根据任务 Fine-Tuning(微调)
(2)使用 Transformer 替代 RNN / LSTM
解释:通过transformer学习一个语言模型,但是模型不是固定的,会根据任务的上下文进行fine-tuning.
使用的是Transformer的 decoder,即没有encoder 的 transformer

对于语言模型,只有一个句子,没有办法是使用完整的 encoder+ decoder的 transformer。
所以gpt 只使用 transformer 的 decoder 。
特点是: 在编码第二个的时候 不能看后面,只能看前面的。即 带了mask的 self-attention。
只能 attend 之前的词, 不能attend 之后的词。
所以gpt的每一层只有 带了 mask的 self-attention 和全连接层, 共12层。
怎么 fine-tuning?
训练语言模型只是一个句子,但是很多任务不只一个句子,比如 对话问答,句子相似度计算。
多个句子在 训练的时候如何变成一个句子呢?
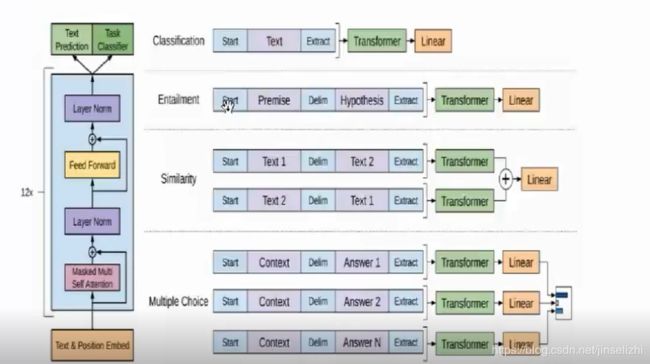
上图的解释:
把两个句子通过 分隔符(标识符) 进行拼接。 delim, start, extract…
如:对于文本分类任务:
句子前加 start、句子后加 extract,再接上之前 预训练的 tranformer ,在接上线性的层 softmax 输出。
再用 监督的数据 fine-tuning tranformer的参数,也包括线性层的参数。
OpenAI GPT未解决的问题
使用了transformer,能够训练更深,效果会比 elmo好很多
留下了两个问题:
- 使用的带mask的self-attention,编码的时候还是只能看前面,不能看后面,所以还是
单向信息流的问题。
训练语言模型的任务要求只能看前面的信息,这是openai gpt最大的一个问题。
2)pretraining 和 fine-tuning不匹配
训练的时候一个句子,fine-tuning的时候 是两个或多个句子。
解决方法
1)masked LM 解决单向信息流的问题
2)nsp multi-task learning
nsp:next sentence predict 预测下一个句子的任务
变成两个句子的输入,使得 pretraining 和 fine-tuning 都是两个句子,解决了GPT的第二个不匹配的问题了
3)encoder again
Bert 详情
bert 输入表示
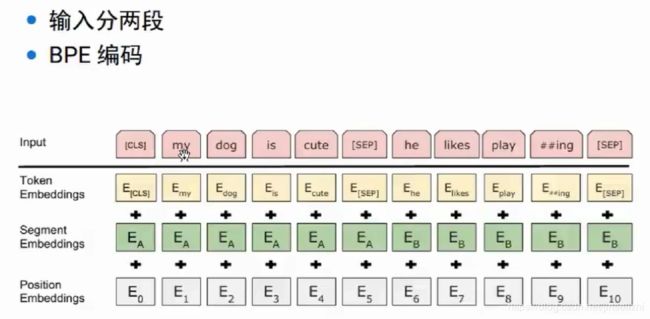
bert的输入是两个句子,使用了分隔符 sep 进行分割,另外使用了 特殊字符 cls 表示句子的开始。
使用 bpe 进行分词,啥事bpe ??
另外,其中segment embedding是指:知道词是前面一个句子,还是后面一个句子的。
其实这点是可以通过 cls ,sep ,sep 进行判断,但是bert 直接通过 segment embedding显示的给出来词
所在句子,可以让预训练模型学习得更加容易。
那如何解决单项信息流的问题呢?
其实再重复一遍,单项信息流的问题主要是 pre-training 的task的一个约束:因为我们要训练一个语言模型,显然只能用前面的词来训练后面的词。当然也可以用后面的预测前面,但是总的还是说 不能看全部的信息。
那么怎么办呢?
bert的办法是 换一个task: 用mask LM。
什么是mask LM?
有点类似与 完形填空
把一个词遮住,来猜这个词。

猜dog的时候明显要用到 前后的信息, 所以这样学习的模型能够考虑前后 双向的信息模型。
预测句子关系-- 解决 GPT的第二个问题
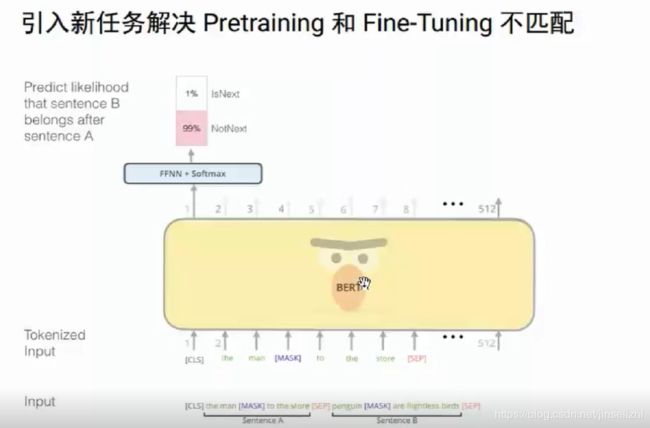
bert的解决方法:随机的抽取两个句子,50%的概率是 连续的句子。
通过对这种两个句子关系的预测,输出为1 表示是连续的句子,如果为0,表示两个句子不是连续的。
能够学习到两个句子的关系,从而在问答等 任务很有作用。
通过联合多任务的学习 从而能够 学习到 一个很好的 pre-training 的模型。
bert使用
有了这个预训练模型之后,具体怎么用呢?
fine-tuning
(1)场景1: 单个句子的任务
比如文本分类,或者情感分类
首先来了一个句子,我用bert进行编码,编码出很多向量,每一个时刻都输出很多向量,
我拿第一个词 cls 的向量 上面再接一些全连接层,再来做一个分类,再用标注监督的数据
fine-tuning这个bert和全连接的参数。
选第一个词的embedding的原因是:bert 还是编码的词的向量,用别的词的向量,不具备其他太多语义 是不行;而cls 没什么语义,
所以它的语义是编码了整个句子的语义,当然也是可以把所有时刻的输出拼起来,再接lstm再接全连接进行分类。

(2)两个句子的任务

(3)问答类的任务
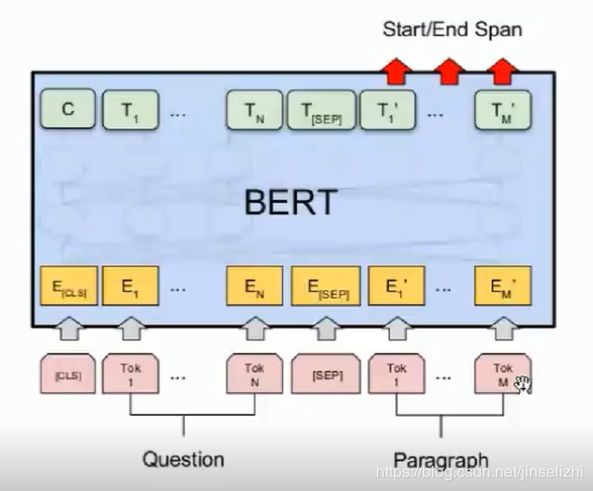
预测的是这个词是不是答案的开始或者结束
(4)序列标注
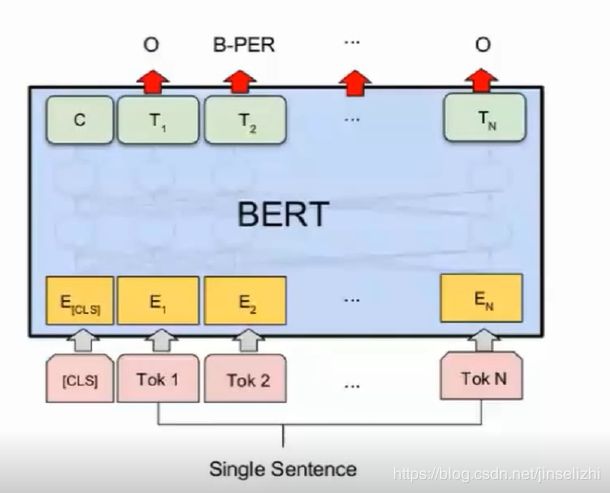
小结
bert 模型 通过 mask LM 可以解决 双向的上下文的语义 表征的问题;同时 两个句子的预测 训练两个句子的语义关系,
从而pre-training和 fine-tuning不匹配的问题,因此bert 比 gpt 的效果 提升了许多。
代码和实际应用
一般来说,用户无需自己训练pre-training,以下是一些 pretrained models。
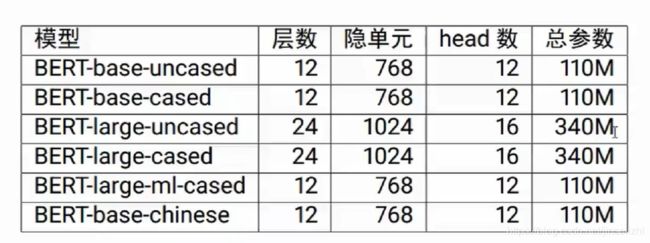
前四个是英语,第5个是多国语言,第6个是中文版本 。
uncased 是不区分大小写,不做大小写归一化。
我们通常需要做 fine-tuning。
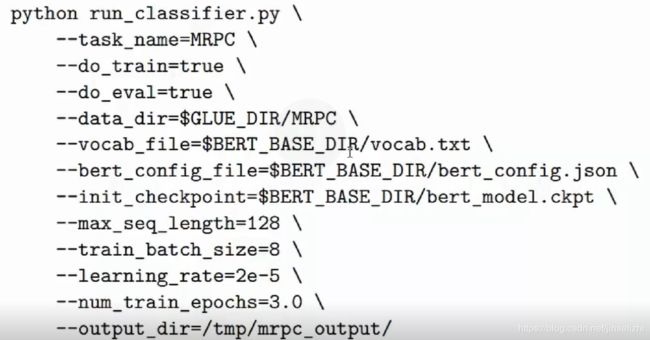
如果数据很多,想要更好的效果,就需要做 pretraining :
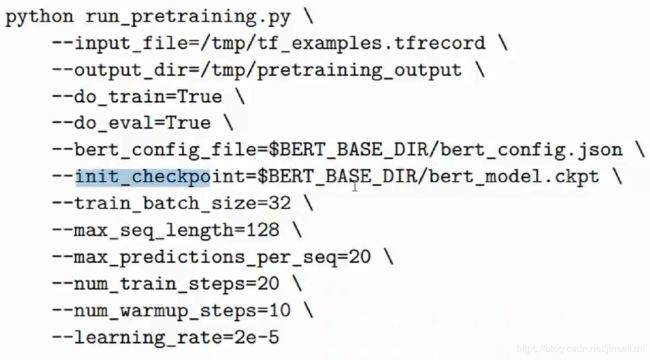
案例分析

FAQ 几千几万的问答对
两个解决方法:
(1)相似度计算(KNN):简单、快捷
如果FAQ很多,就会比较慢
(2)意图分类:短文本分类
需要比较多的分类数据,需要训练模型,每增加一个意图,就需要重新训练
相似度计算
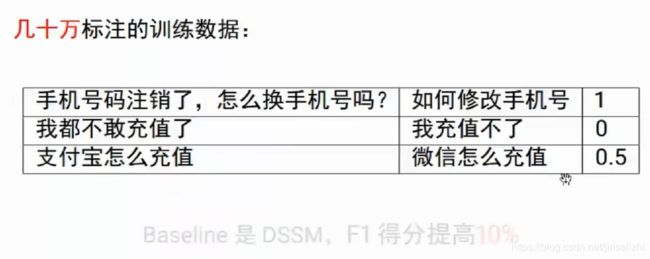
意图分类

F1 得分提高 3%!
使用bert 注意事项
- 使用中文模型,不要使用多语言模型! (偶尔有一两个英文单词,也要用中文模型)
- max_seq_length 可以小一点,提高效率
- 内存不够,需要调整 train_batch_size (调小一点)
- 有足够多的领域数据,可以尝试 pretraining
总结
word embedding
rnn/lstm/gru
seq2seq, attention 和self-attention
contextual word embedding
elmo
openai apt
bert 原理
bert 实战
学习资料
https://v.qq.com/x/page/j0855zl9a9r.html
作者博客:
http://fancyerii.github.io/
