TensorFlow学习笔记(二)之可视化(Tensorboard)
一、Tensorboard简介
Tensorboard是TensorFlow自带的一个强大的可视化工具,也是一个web应用程序套件。通过将tensorflow程序输出的日志文件的信息可视化使得tensorflow程序的理解、调试和优化更加简单高效。支持其七种可视化:
- SCALARS:展示训练过程中的准确率、损失值、权重/偏置的变化情况
- IMAGES:展示训练过程中及记录的图像
- AUDIO:展示训练过程中记录的音频
- GRAPHS:展示模型的数据流图,以及各个设备上消耗的内存和时间
- DISTRIBUTIONS:展示训练过程中记录的数据的分布图
- HISTOGRAMS:展示训练过程中记录的数据的柱状图
- EMBEDDINGS:展示词向量后的投影分布
界面展示:
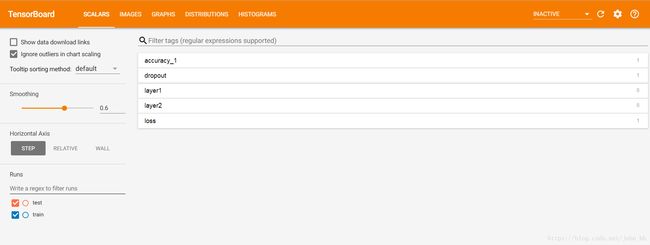
那如何启动tensorboard呢?使用是手写体识别的例子,源码如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
config = tf.ConfigProto(allow_soft_placement=True)
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.33)
config.gpu_options.allow_growth = True
max_steps = 1000 # 最大迭代次数
learning_rate = 0.001 # 学习率
dropout = 0.9 # dropout时随机保留神经元的比例
data_dir = './MNIST_DATA' # 样本数据存储的路径
log_dir = './MNIST_LOG' # 输出日志保存的路径
# 获取数据集,并采用采用one_hot热编码
mnist = input_data.read_data_sets(data_dir, one_hot=True)
sess = tf.InteractiveSession(config=config)
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
# 保存图像信息
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
# 初始化权重参数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 初始化偏执参数
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 绘制参数变化
def variable_summaries(var):
with tf.name_scope('summaries'):
# 计算参数的均值,并使用tf.summary.scaler记录
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
# 计算参数的标准差
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
# 使用tf.summary.scaler记录记录下标准差,最大值,最小值
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
# 用直方图记录参数的分布
tf.summary.histogram('histogram', var)
# 构建神经网络
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
# 设置命名空间
with tf.name_scope(layer_name):
# 调用之前的方法初始化权重w,并且调用参数信息的记录方法,记录w的信息
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
# 调用之前的方法初始化权重b,并且调用参数信息的记录方法,记录b的信息
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
# 执行wx+b的线性计算,并且用直方图记录下来
with tf.name_scope('linear_compute'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('linear', preactivate)
# 将线性输出经过激励函数,并将输出也用直方图记录下来
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
# 返回激励层的最终输出
return activations
hidden1 = nn_layer(x, 784, 500, 'layer1')
# 创建dropout层
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
# 创建损失函数
with tf.name_scope('loss'):
# 计算交叉熵损失(每个样本都会有一个损失)
diff = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)
with tf.name_scope('total'):
# 计算所有样本交叉熵损失的均值
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('loss', cross_entropy)
# 使用AdamOptimizer优化器训练模型,最小化交叉熵损失
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
# 计算准确率
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
# 分别将预测和真实的标签中取出最大值的索引,弱相同则返回1(true),不同则返回0(false)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
# 求均值即为准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# summaries合并
merged = tf.summary.merge_all()
# 写到指定的磁盘路径中
train_writer = tf.summary.FileWriter(log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(log_dir + '/test')
# 运行初始化所有变量
tf.global_variables_initializer().run()
def feed_dict(train):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if train:
xs, ys = mnist.train.next_batch(100)
k = dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}
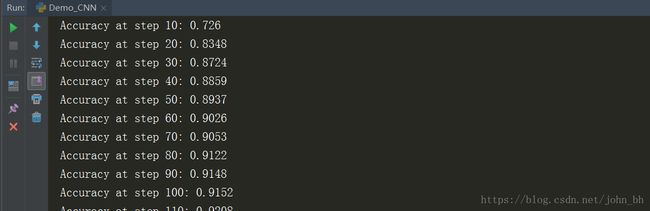
for i in range(max_steps):
if i % 10 == 0: # 记录测试集的summary与accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # 记录训练集的summary
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
train_writer.close()
test_writer.close()在pycharm中执行这段代码,效果如下:
同时,在训练的时候打开命令行,输入下面命令,启动TesnorBoard:
tensorboard --logdir=./MNIST_LOG/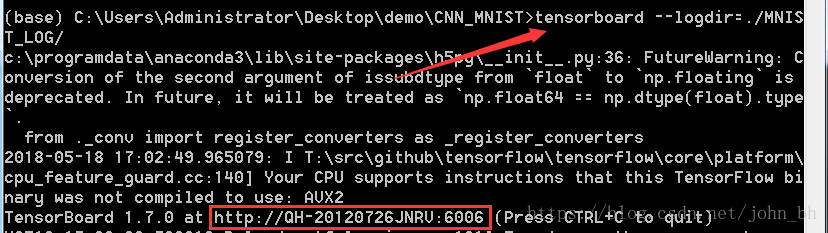
这里生成一个链接地址,复制到游览器中查看各个模块的内容。
总的来说步骤如下:
- 创建writer,写日志文件:tf.summary.FileWriter(log_dir + ‘/train’, sess.graph)
- 保存日志文件:writer.close()
- 运行可视化命令,启动服务:tensorboard –logdir /path/
- 打开可视化界面,通过浏览器打开服务器访问端口http://xxx.xxx.xxx.xxx:6006
二、SCALARS面板
SCALARS 面板,统计tensorflow中的标量(如:学习率、模型的总损失)随着迭代轮数的变化情况。SCALARS 面板的左边是一些选项,包括Split on undercores(用下划线分开显示)、Data downloadlinks(数据下载链接)、Smoothing(图像的曲线平滑程度)以及Horizontal Axis(水平轴)的表示,其中水平轴的表示分3 种(STEP 代表迭代次数,RELATIVE 代表按照训练集和测试集的相对值,WALL 代表按照时间)。图中右边给出了准确率变化曲线。
如下图二所示,SCALARS栏目显示通过函数tf.summary.scalar()记录的数据的变化趋势。如下所示代码可添加到程序中,用于记录学习率的变化情况。
tf.summary.scalar('accuracy', accuracy)
SCALARS 面板中还绘制了每一层的偏置(biases)和权重(weights)的变化曲线,包括每
次迭代中的最大值、最小值、平均值和标准差,如下图,layer1层:

layer2层:

构建损失曲线:
tf.summary.scalar('loss', cross_entropy)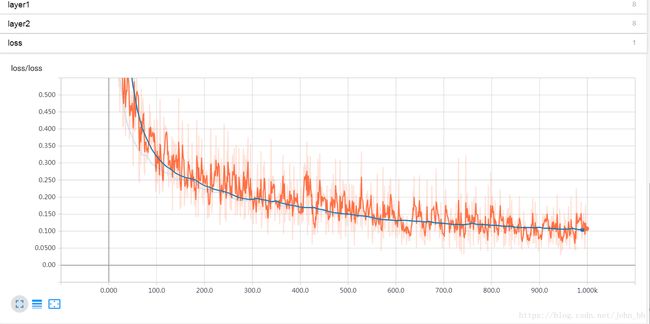
三、IMAGES面板
图像仪表盘,可以显示通过tf.summary.image()函数来保存的png图片文件。
1. # 指定图片的数据源为输入数据x,展示的相对位置为[-1,28,28,1]
2. image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
3. # 将input命名空间下的图片放到summary中,一次展示10张
4. tf.summary.image('input', image_shaped_input , 10) 如上面代码,将输入数据中的png图片放到summary中,准备后面写入日志文件。运行程序,生成日志文件,然后在tensorboard的IMAGES栏目下就会出现如下图一所示的内容(实验用的是mnist数据集)。仪表盘设置为每行对应不同的标签,每列对应一个运行。图像仪表盘仅支持png图片格式,可以使用它将自定义生成的可视化图像(例如matplotlib散点图)嵌入到tensorboard中。该仪表盘始终显示每个标签的最新图像。
IMAGES面板展示训练过程中及记录的图像,下图展示了数据集合测试数据经过处理后图片的样子:

四、AUDIO
AUDIO 面板是展示训练过程中处理的音频数据。可嵌入音频的小部件,用于播放通过tf.summary.audio()函数保存的音频。一个音频summary要存成 的二维字符张量。其中,k为summary中记录的音频被剪辑的次数,每排张量是一对[encoded_audio, label],其中,encoded_audio 是在summary中指定其编码的二进制字符串,label是一个描述音频片段的UTF-8编码的字符串。
仪表盘设置为每行对应不同的标签,每列对应一个运行。该仪表盘始终嵌入每个标签的最新音频。
五、GRAPHS
GRAPHS 面板是对理解神经网络结构最有帮助的一个面板,它直观地展示了数据流图。下图所示界面中节点之间的连线即为数据流,连线越粗,说明在两个节点之间流动的张量(tensor)越多。
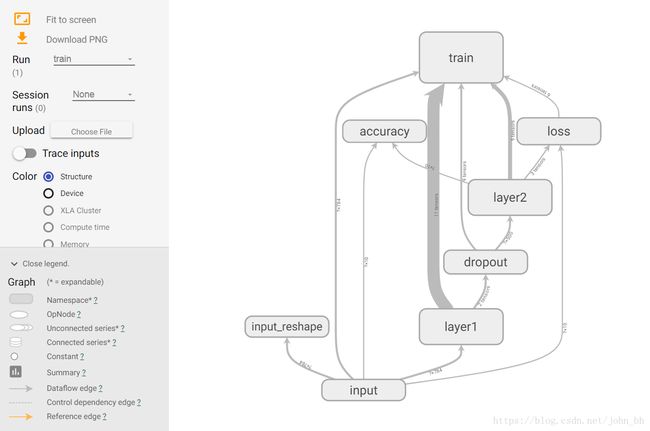
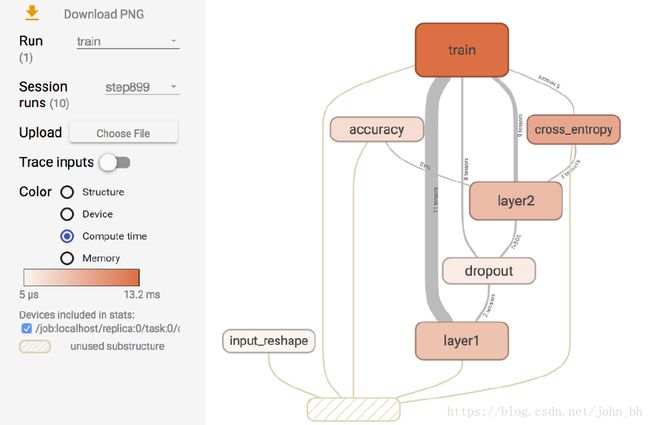
在GRAPHS 面板的左侧,可以选择迭代步骤。可以用不同Color(颜色)来表示不同的Structure(整个数据流图的结构),或者用不同Color 来表示不同Device(设备)。例如,当使用多个GPU 时,各个节点分别使用的GPU 不同。当我们选择特定的某次迭代时,可以显示出各个节点的Compute time(计算时间)以及Memory(内存消耗)。
六、DISTRIBUTIONS
DISTRIBUTIONS 面板和接下来要讲的HISTOGRAMS 面板类似,只不过是用平面来表示来自特定层的激活前后、权重和偏置的分布,它显示了一些分发的高级统计信息。

七、HISTOGRAMS
HISTOGRAMS面板,统计tensorflow中的张量随着迭代轮数的变化情况。它用于展示通过tf.summary.histogram记录的数据的变化趋势。如下代码所示:
# 用直方图记录参数的分布
tf.summary.histogram('histogram', var)
# 执行wx+b的线性计算,并且用直方图记录下来
tf.summary.histogram('linear', preactivate)
# 将线性输出经过激励函数,并将输出也用直方图记录下来
tf.summary.histogram('activations', activations)
上述代码将神经网络中某一层的参数分布、线性计算结果、经过激励函数的计算结果信息加入到日志文件中,运行程序生成日志后,启动tensorboard就可以在HISTOGRAMS栏目下看到对应的展开图像。
HISTOGRAMS 主要是立体地展现来自特定层的激活前后、权重和偏置的分布。

八、EMBEDDINGS
EMBEDDINGS 面板展示的是词嵌入投影仪。(后续做词嵌入的时候更新上…….)