yolo v2 训练自己数据集遇到的问题
1.CUDA Error: out of memory darknet: ./src/cuda.c:36: check_error: Assertio `0' failed.
需要修改所使用的模型cfg文件中的subdivision的参数。
由subdivisions=8改成subdivisions=64。
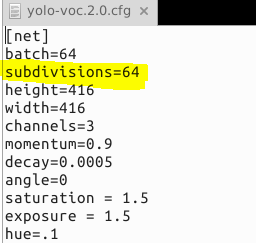
subdivision:这个参数很有意思的,它会让你的每一个batch不是一下子都丢到网络里。而是分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration。这样会降低对显存的占用情况。如果设置这个参数为1的话就是一次性把所有batch的图片都丢到网络里,如果为2的话就是一次丢一半。
http://blog.csdn.net/renhanchi/article/details/71077830?locationNum=11&fps=1
若上述方法不能解决:
导致cuda真正的原因是:
大致意思就是 服务器的GPU大小为M
tensorflow只能申请N(N
也就是tensorflow告诉你 不能申请到GPU的全部资源 然后就不干了
解决方法:
找到代码中Session
在session定义前 增加
config = tf.ConfigProto(allow_soft_placement=True)
#最多占gpu资源的70%
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.7)
#开始不会给tensorflow全部gpu资源 而是按需增加
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
这样就没问题了
其实tensorflow 算是一个比较贪心的工具了
就算用device_id指定gpu 也会占用别的GPU的显存资源 必须在执行程序前
执行 export CUDA_VISIBLE_DEVICES=n(n为可见的服务器编号)
再去执行python 代码.py 才不会占用别的GPU资源
最近刚开始搞tensorflow 之前都是caffe
这周连续3天被实验室的人 举报 占用过多服务器资源 真是心累 只要用上面的方法
也就是执行代码前 执行 export CUDA_VISIBLE_DEVICES=n
只让1个或者个别GPU可见 其他GPU看不见 就行了
http://blog.csdn.net/wangkun1340378/article/details/72782593
解决方法:运行ytiny-yolo-voc.cfg不会遇到此类情况,但是使用yolo-voc.cfg等多层模型会遇到cuda error out of memory错误,由于本人能力在darknet中并没有找到上述资料中所说的修改gpu资源分配的地方。故需运行yolo-voc.cfg时先查看nvidia-smi中查看gpu使用情况,只有完全gpu完全闲置才可以正常运行。(若有人同时在跑其他程序就不行啦)
2.使用detector recall函数前需要先修改examples/detector.c的代码

//改成infrared_val.txt的完整路径
然后记得一定要make一下
http://blog.csdn.net/hysteric314/article/details/54097845
3.