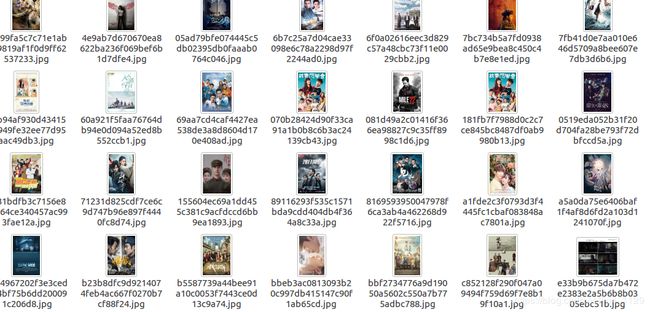
scrapy批量抓取图片
抓取电影天堂 2018新片精品下所有电影海报
1. Item
import scrapy
class TestttItem(scrapy.Item):
image_urls=scrapy.Field()
images = scrapy.Field()
2.Spider 继承CrawlSpider 用于翻页
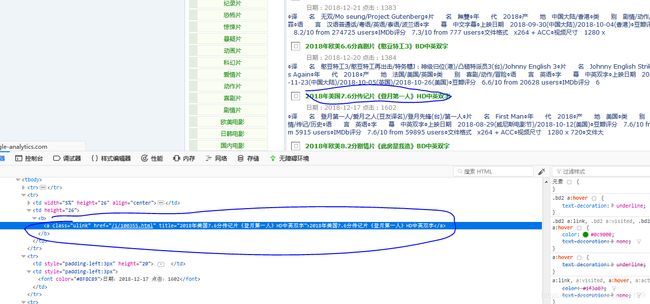
先获取电影链接 然后从链接中获取图片链接
import scrapy
from testtt.items import TestttItem
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class BaiduSpider(CrawlSpider):
name = 'pic'
start_urls = ['https://www.dy2018.com/html/gndy/dyzz/index.html']
page_1x = LinkExtractor(allow=('index.*'))
rules = [
Rule(page_1x, callback='parse_content', follow=True)
]
base_url='https://www.dy2018.com'
def parse_content(self, response):
urls = response.css('b a[class="ulink"]::attr(href)').extract()
for url in urls:
new_url=self.base_url+url
print(new_url)
yield scrapy.Request(url=new_url,callback=self.parse_check)
def parse_check(self,response):
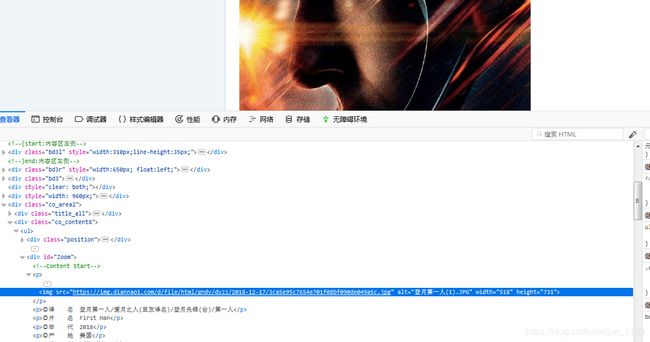
img_urls=response.css('p img::attr(src)').extract()
print(img_urls)
if len(img_urls)==0:
return
item = TestttItem()
item['image_urls'] = img_urls
yield item
3. pipeline 注意:PicPipeline继承自ImagesPipeline 利用from scrapy.pipelines.images import ImagesPipeline导入
mport scrapy
import pymongo
from scrapy.http import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class PicPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
print(item['image_urls'])
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
print(image_paths)
if not image_paths:
raise DropItem("Item contains no images")
return item
4.setting
ITEM_PIPELINES = {
# 'testtt.pipelines.TestttPipeline': 300,
#'testtt.pipelines.MogoPipeline': 300,
'testtt.pipelines.PicPipeline': 1,
}
IMAGES_STORE = "./"