CycleGAN 论文阅读及代码实现
介绍
CycleGAN是2018年发表于ICCV17的一篇论文,可以让2个图片相互转化,也就是风格迁移,如马变为斑马,斑马变为马。

网络结构
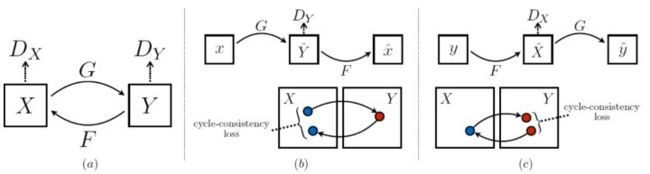 CycleGAN总结构有4个网络,第一个为生成网络G:X—>Y;第二个网络为生成网络F:X—>Y。第三个网络为对抗网络命名为Dx,鉴别输入图像是否为X;第四个网络为对抗网络命名为Dy,鉴别输入图像是不是Y。如图,以马(X)和斑马(Y)为例,G网络将马的图像转化为斑马图像;F网络将斑马的图像转化为马的图像;Dx网络鉴别输入的图像是不是马;Dy网络鉴别输入图像是不是斑马。这4个网络仅有2个网络结构,即G和F都是生成网络,这两者的网络结构相同,Dx和Dy都是对抗性网络,这两者的网络结构相同。
CycleGAN总结构有4个网络,第一个为生成网络G:X—>Y;第二个网络为生成网络F:X—>Y。第三个网络为对抗网络命名为Dx,鉴别输入图像是否为X;第四个网络为对抗网络命名为Dy,鉴别输入图像是不是Y。如图,以马(X)和斑马(Y)为例,G网络将马的图像转化为斑马图像;F网络将斑马的图像转化为马的图像;Dx网络鉴别输入的图像是不是马;Dy网络鉴别输入图像是不是斑马。这4个网络仅有2个网络结构,即G和F都是生成网络,这两者的网络结构相同,Dx和Dy都是对抗性网络,这两者的网络结构相同。
Generator-生成网络
 以上网络主要有3种操作,卷积,反卷积和残差模块;卷积和反卷积后通常还有BN,激活函数等。
以上网络主要有3种操作,卷积,反卷积和残差模块;卷积和反卷积后通常还有BN,激活函数等。
卷积
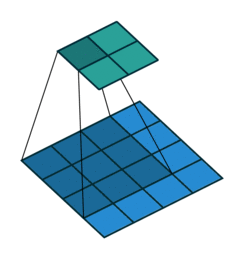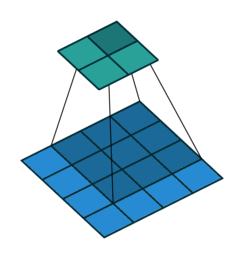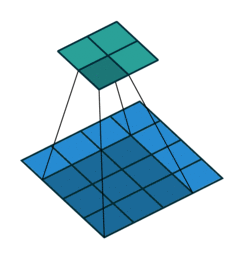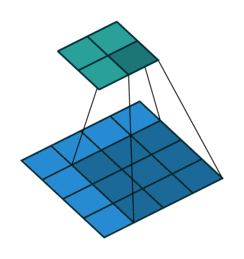
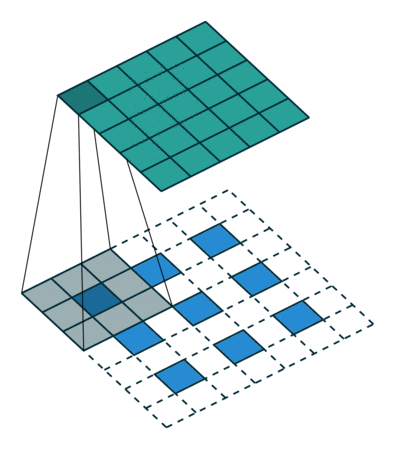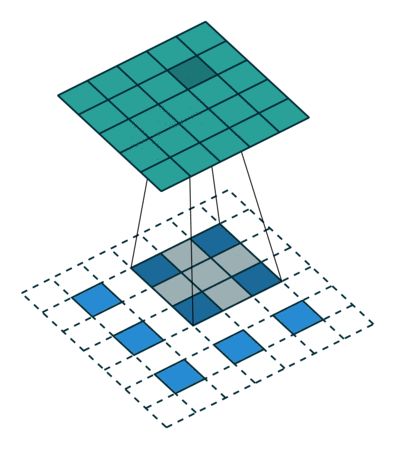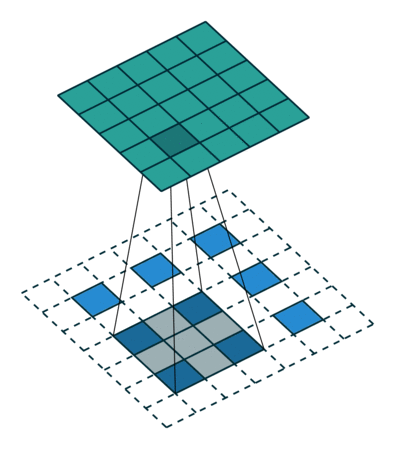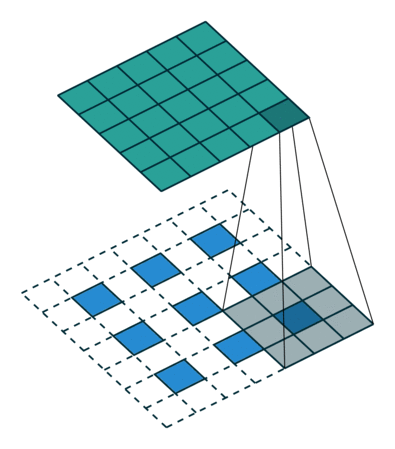
反卷积
残差模块
 残差网络最先是在ResNet中引出的可以有效的避免梯度消失,实现网络深度的提升。
残差网络最先是在ResNet中引出的可以有效的避免梯度消失,实现网络深度的提升。
Discriminator-对抗网络
 卷积后面通道都有BN层和激活函数,另外Discriminator的最终输出并不是0.0-1。0间的值,而是一个1616的矩阵,因此定义了这个1616矩阵的各个元素越接近0.9,则Loss越小,即是真值的概率越大。
卷积后面通道都有BN层和激活函数,另外Discriminator的最终输出并不是0.0-1。0间的值,而是一个1616的矩阵,因此定义了这个1616矩阵的各个元素越接近0.9,则Loss越小,即是真值的概率越大。
Loss
G_loss
网络G的loss函数,由2部分组成,分别是cycle_loss和g_loss。
- cycle_loss:G(x)生成了y’,F(G(x))即是生成的x’,则F(G(x))-x的绝对值的均值定为loss_x;F(y)生成x’,G(F(y))生成y’,则G(F(y))-y的绝对值的均值定为loss_y;cycle_loss=loss_x+loss_y;
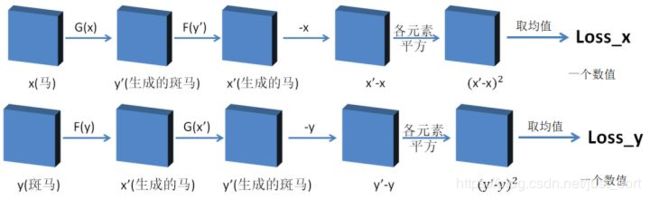 - g_loss:G(x)是y’,则Dy(y’)每个元素减去0.9取平方,然后取平方均值定义为g_loss;
- g_loss:G(x)是y’,则Dy(y’)每个元素减去0.9取平方,然后取平方均值定义为g_loss;
 G_loss=cycle_loss+g_loss;
G_loss=cycle_loss+g_loss;
Dy_loss
网络Dy的loss函数,由2部分组成,分别是loss_real_y和loss_fake_y;
- loss_real_y:Dy(y)是一个16x16矩阵,每个元素减去0.9后取平方,则各平方均值定义为loss_real_y;
- loss_fake_y:G(x)生成一个y’,则Dy(G(x))相当于Dy(y’),也是一个16x16矩阵,矩阵每个元素取平方,则各平方均值定义为loss_fake_y;
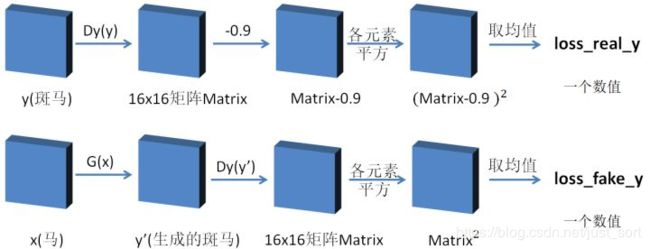 Dy_loss=loss_real_y+loss_fake_y;
Dy_loss=loss_real_y+loss_fake_y;
F_loss
网络F的Loss函数,由2部分组成,分别是cycle_loss和f_loss;
- cycle_loss同G_loss中的定义
- f_loss:F(y)生成一个x’,Dx(x’)即Dx(F(y))是一个16x16的矩阵,每个元素减去0.9后取平方,各平方均值定义为f_loss;
 F_loss=cycle_Loss+f_loss;
F_loss=cycle_Loss+f_loss;
Dx_loss
网络Dx的loss函数,由两部分组成,分别是loss_real_x和loss_fake_x;
- loss_real_x:Dx(x)是一个16x16矩阵,每个元素减去0.9后取平方,则各平方均值定义为loss_real_x;
- loss_fake_x:F(y)生成一个x’,则Dx(F(y))相当于Dx(x’),也是一个16x16矩阵,矩阵每个元素取平方,则各平方均值定义为loss_fake_x;
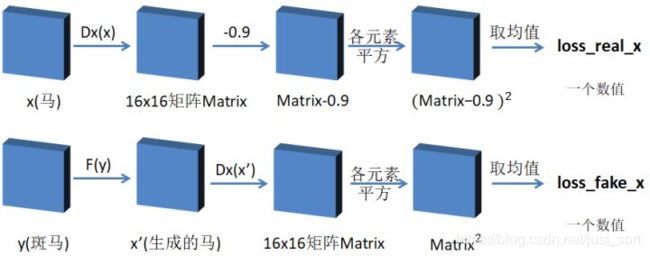 Dx_loss= loss_real_x+ loss_fake_x;
Dx_loss= loss_real_x+ loss_fake_x;
训练
最小化[G_loss,Dy_loss,F_loss,Dx_loss]变量,实现网络优化训练。
代码实现
这里使用的损失函数和上面不是太一样,具体可以看这个工程:https://github.com/hardikbansal/CycleGAN 和这个博客:https://hardikbansal.github.io/CycleGANBlog/ 通过修改to_train和to_test参数控制训练和测试即可。
#coding=utf-8
import tensorflow as tf
import numpy as np
from scipy.misc import imsave #将数组保存到图像中
import matplotlib.pyplot as plt
import os #文件夹操作
import time
import random
#函数功能:实现leakyrelu
def lrelu(x, leak=0.2, name = "lrelu"):
with tf.variable_scope(name):
return tf.maximum(x, leak*x)
#函数功能:实现BN
def instance_norm(x):
with tf.variable_scope("instance_norm"):
epsilon = 1e-5
mean, var = tf.nn.moments(x, [1, 2], keep_dims=True)
scale = tf.get_variable('scale', [x.get_shape()[-1]], initializer=tf.truncated_normal_initializer(mean=1.0, stddev=0.02))
offset = tf.get_variable('offset', [x.get_shape()[-1]], initializer=tf.constant_initializer(0.0))
out = scale*tf.div(x-mean, tf.sqrt(var + epsilon)) + offset
return out
#函数功能:实现卷积
def general_conv2d(input, o_d=64, f_h=7, f_w=7, s_h=1, s_w=1, stddev=0.02, padding="VALID", name="conv2d", do_norm=True, do_relu=True, relufactor=0):
with tf.variable_scope(name):
conv = tf.contrib.layers.conv2d(input, o_d, [f_h, f_w], [s_h, s_w], padding, activation_fn=None, weights_initializer=tf.truncated_normal_initializer(stddev=stddev),
biases_initializer=tf.constant_initializer(0.0))
if do_norm:
conv = instance_norm(conv)
if do_relu:
if relufactor == 0:
conv = tf.nn.relu(conv, "relu")
else:
conv = lrelu(conv, relufactor, "lrelu")
return conv
#函数功能:实现反卷积
def general_deconv2d(input, outshape, o_d=64, f_h=7, f_w=7, s_h=1, s_w=1, stddev=0.02, padding="VALID", name="deconv2d", do_norm=True, do_relu=True, relufactor=0):
with tf.variable_scope(name):
conv = tf.contrib.layers.conv2d_transpose(input, o_d, [f_h, f_w], [s_h, s_w], padding, activation_fn=None, weights_initializer=tf.truncated_normal_initializer(stddev=stddev),
biases_initializer=tf.constant_initializer(0.0))
if do_norm:
conv = instance_norm(conv)
if do_relu:
if relufactor == 0:
conv = tf.nn.relu(conv, "relu")
else:
conv = lrelu(conv, relufactor, "lrelu")
return conv
#Building the generator->1.Encoder 2.Transformer 3.Decoder
ngf = 32 #生成器的第一层的filtes的个数
ndf = 64 #判别器的第一层的filtes的个数
batch_size = 1 #每次处理的图片个数
pool_size = 50 #保存最近的pool_size个图片,并随机用一张计算D_loss
img_width = 256
img_height = 256
img_depth = 3 #RGB
img_size = img_height * img_width
to_train = True
to_test = False
to_restore = True
output_path = "./output"
check_dir = "./output/checkpoints/"
max_epoch = 1000
max_images = 100
save_training_images = True
#函数功能:构造残差模块
def build_resnet_block(input, dim, name="resnet"):
with tf.variable_scope(name):
out_res = tf.pad(input, [[0, 0], [1, 1], [1, 1], [0, 0]], "REFLECT")
out_res = general_conv2d(out_res, dim, 3, 3, 1, 1, 0.02, "VALID", "c1")
out_res = tf.pad(out_res, [[0, 0], [1, 1], [1, 1], [0, 0]], "REFLECT")
out_res = general_conv2d(out_res, dim, 3, 3, 1, 1, 0.02, "VALID", "c2", do_relu=False)
return tf.nn.relu(out_res + input)
#函数功能:构造包含6个参差模块作为转换器的生成网络
def build_generator_resnet_6blocks(input, name="generator"):
with tf.variable_scope(name):
f = 7
ks = 3
pad_input = tf.pad(input, [[0, 0], [ks, ks], [ks, ks], [0, 0]], "REFLECT")
o_c1 = general_conv2d(pad_input, ngf, ks, ks, 1, 1, 0.02, name="c1")
o_c2 = general_conv2d(o_c1, ngf*2, ks, ks, 2, 2, 0.02, "SAME", name="c2")
o_c3 = general_conv2d(o_c2, ngf*4, ks, ks, 2, 2, 0.02, "SAME", name="c3")
o_r1 = build_resnet_block(o_c3, ngf*4, "r1")
o_r2 = build_resnet_block(o_r1, ngf*4, "r2")
o_r3 = build_resnet_block(o_r2, ngf*4, "r3")
o_r4 = build_resnet_block(o_r3, ngf*4, "r4")
o_r5 = build_resnet_block(o_r4, ngf*4, "r5")
o_r6 = build_resnet_block(o_r5, ngf*4, "r6")
o_c4 = general_deconv2d(o_r6, [batch_size, 64, 64, ngf*2], ngf*2, ks, ks, 2, 2, 0.02, "SAME", "c4")
o_c5 = general_deconv2d(o_c4, [batch_size, 128, 128, ngf], ngf, ks, ks, 2, 2, 0.02, "SAME", "c5")
o_c5_pad = tf.pad(o_c5, [[0, 0], [ks, ks], [ks, ks], [0, 0]], "REFLECT")
o_c6 = general_conv2d(o_c5_pad, img_depth, f, f, 1, 1, 0.02, "VALID", "c6", do_relu=False)
#Adding the tanh layer
out_gen = tf.nn.tanh(o_c6, "t1")
return out_gen
#函数功能:构造包含6个参差模块作为转换器的生成网络
def build_generator_resnet_9blocks(input, name="generator"):
with tf.variable_scope(name):
f = 7
ks = 3
pad_input = tf.pad(input, [[0, 0], [ks, ks], [ks, ks], [0, 0]], "REFLECT")
o_c1 = general_conv2d(input, ngf, ks, ks, 1, 1, 0.02, name="c1")
o_c2 = general_conv2d(o_c1, ngf*2, ks, ks, 2, 2, 0.02, "SAME", name="c2")
o_c3 = general_conv2d(o_c2, ngf*4, ks, ks, 2, 2, 0.02, "SAME", name="c3")
o_r1 = build_resnet_block(o_c3, ngf*4, "r1")
o_r2 = build_resnet_block(o_r1, ngf*4, "r2")
o_r3 = build_resnet_block(o_r2, ngf*4, "r3")
o_r4 = build_resnet_block(o_r3, ngf*4, "r4")
o_r5 = build_resnet_block(o_r4, ngf*4, "r5")
o_r6 = build_resnet_block(o_r5, ngf*4, "r6")
o_r7 = build_resnet_block(o_r6, ngf*4, "r7")
o_r8 = build_resnet_block(o_r7, ngf*4, "r8")
o_r9 = build_resnet_block(o_r8, ngf*4, "r9")
o_c4 = general_deconv2d(o_r9, [batch_size, 128, 128, ngf*2], ngf*2, ks, ks, 2, 2, 0.02, "SAME", "c4")
o_c5 = general_deconv2d(o_c4, [batch_size, 256, 256, ngf], ngf, ks, ks, 2, 2, 0.02, "SAME", "c5")
o_c6 = general_conv2d(o_c5, img_depth, f, f, 1, 1, 0.02, "SAME", "c6", do_relu=False)
#Adding the tanh layer
out_gen = tf.nn.tanh(o_c6, "t1")
return out_gen
#函数功能: 构造Discriminator_A->B
def build_gen_discriminator(input, name="discriminator"):
with tf.variable_scope(name):
f = 4
o_c1 = general_conv2d(input, ndf, f, f, 2, 2, 0.02, "SAME", "c1", do_norm=False, relufactor=0.2)
o_c2 = general_conv2d(o_c1, ndf*2, f, f, 2, 2, 0.02, "SAME", "c2", relufactor=0.2) #do_norm=True
o_c3 = general_conv2d(o_c2, ndf*4, f, f, 2, 2, 0.02, "SAME", "c3", relufactor=0.2)
o_c4 = general_conv2d(o_c3, ndf*8, f, f, 1, 1, 0.02, "SAME", "c4", relufactor=0.2)
o_c5 = general_conv2d(o_c4, 1, f, f, 1, 1, 0.02, "SAME", "c5", do_norm=False, do_relu=False)
return o_c5
#函数功能: 部分裁剪的Discriminator
def patch_discriminator(input, name="discriminator"):
with tf.variable_scope(name):
f = 4
patch_input = tf.random_crop(input, [1,70,70,3])
o_c1 = general_conv2d(patch_input, ndf, f, f, 2, 2, 0.02, "SAME", "c1", do_norm=False, relufactor=0.2)
o_c2 = general_conv2d(o_c1, ndf*2, f, f, 2, 2, 0.02, "SAME", "c2", relufactor=0.2) #do_norm=True
o_c3 = general_conv2d(o_c2, ndf*4, f, f, 2, 2, 0.02, "SAME", "c3", relufactor=0.2)
o_c4 = general_conv2d(o_c3, ndf*8, f, f, 1, 1, 0.02, "SAME", "c4", relufactor=0.2)
o_c5 = general_conv2d(o_c4, 1, f, f, 1, 1, 0.02, "SAME", "c5", do_norm=False, do_relu=False)
return o_c5
class CycleGAN():
def input_setup(self):
'''
函数功能能:为输入数据设置变量
filenames_A/filenames_B -> takes the list of all training images
self.images_A/self.images_B -> Input image with each values ranging from [-1,1]
:return:
'''
#获取文件列表
filenames_A = tf.train.match_filenames_once("zxy2lsx/trainA/*.jpg")
print(filenames_A)
self.queue_length_A = tf.size(filenames_A)
print(self.queue_length_A)
filenames_B = tf.train.match_filenames_once("zxy2lsx/trainB/*.jpg")
print(filenames_B)
self.queue_length_B = tf.size(filenames_B)
print(self.queue_length_B)
filename_queue_A = tf.train.string_input_producer(filenames_A) #输出字符串到一个输入管道队列
filename_queue_B = tf.train.string_input_producer(filenames_B)
image_reader = tf.WholeFileReader() #一个阅读器,读取整个文件,返回文件名称key,以及文件中所有的内容value
_, image_file_A = image_reader.read(filename_queue_A)
_, image_file_B = image_reader.read(filename_queue_B)
# 将输入图像resize为[256, 256]
# [N, C, W, H] 在第一个维度减去均值127.5
self.image_A = tf.subtract(tf.div(tf.image.resize_images(tf.image.decode_jpeg(image_file_A), [256, 256]), 127.5), 1)
self.image_B = tf.subtract(tf.div(tf.image.resize_images(tf.image.decode_jpeg(image_file_B), [256, 256]), 127.5), 1)
def input_read(self, sess):
'''
函数功能:从图像文件夹中读取输入信息
:param sess:
:return:
'''
#开启一个协调器
coord = tf.train.Coordinator()
#QueueRunner类用来启动tensor的入队线程,可以用来启动多个工作线程
threads = tf.train.start_queue_runners(coord=coord)
num_files_A = sess.run(self.queue_length_A)
num_files_B = sess.run(self.queue_length_B)
self.fake_images_A = np.zeros((pool_size, 1, img_height, img_width, img_depth))
self.fake_images_B = np.zeros((pool_size, 1, img_height, img_width, img_depth))
self.A_input = np.zeros((max_images, batch_size, img_height, img_width, img_depth))
self.B_input = np.zeros((max_images, batch_size, img_height, img_width, img_depth))
for i in range(max_images):
image_tensor = sess.run(self.image_A)
if(image_tensor.size == img_size*batch_size*img_depth):
self.A_input[i] = image_tensor.reshape((batch_size, img_height, img_width, img_depth))
for i in range(max_images):
image_tensor = sess.run(self.image_B)
if(image_tensor.size == img_size*batch_size*img_depth):
self.B_input[i] = image_tensor.reshape((batch_size, img_height, img_width, img_depth))
#协调器coord发出所有线程终止信号
coord.request_stop()
#把开启的线程加入主线程,等待threads结束
coord.join(threads)
def model_setup(self):
'''
函数功能:为训练建立模型
self.input_A/self.input_B -> Set of training images.
self.fake_A/self.fake_B -> Generated images by corresponding generator of input_A and input_B
self.lr -> Learning rate variable
self.cyc_A / self.cyc_B -> Images generated after feeding self.fake_A/self.fake_B to corresponding generator. This is use to calculate cyclic loss.
:return:
'''
# 输入数据A和B的占位符
self.input_A = tf.placeholder(tf.float32, [batch_size, img_width, img_height, img_depth], name="input_A")
self.input_B = tf.placeholder(tf.float32, [batch_size, img_width, img_height, img_depth], name="input_B")
# 用来计算损失函数
self.fake_pool_A = tf.placeholder(tf.float32, [None, img_width, img_height, img_depth], name="fake_pool_A")
self.fake_pool_B = tf.placeholder(tf.float32, [None, img_width, img_height, img_depth], name="fake_pool_B")
self.global_step = tf.Variable(0, name="global_step", trainable=False)
self.num_fake_inputs = 0
self.lr = tf.placeholder(tf.float32, shape=[], name="lr")
# A为马,B为斑马
with tf.variable_scope("Model") as scope:
self.fake_B = build_generator_resnet_9blocks(self.input_A, name="g_A") #转换成的斑马
self.fake_A = build_generator_resnet_9blocks(self.input_B, name="g_B") #转换成的马
self.rec_A = build_gen_discriminator(self.input_A, "d_A") # 鉴别器输出真实的马为真的概率(越接近1越好)
self.rec_B = build_gen_discriminator(self.input_B, "d_B") # 鉴别器输出真实的斑马为真的概率(越接近1越好)
scope.reuse_variables()
self.fake_rec_A = build_gen_discriminator(self.fake_A, "d_A") # 鉴别器输出马转换为斑马再转换为马为真的概率(越接近0的概率越好)
self.fake_rec_B = build_gen_discriminator(self.fake_B, "d_B") # 鉴别器输出斑马转换为马再转换为斑马为真的概率(越接近0的概率越好)
self.cyc_A = build_generator_resnet_9blocks(self.fake_B, "g_B") # 马转换为斑马再转换为马
self.cyc_B = build_generator_resnet_9blocks(self.fake_A, "g_A") # 斑马转换为马再转换为马
scope.reuse_variables()
self.fake_pool_rec_A = build_gen_discriminator(self.fake_pool_A, "d_A") #
self.fake_pool_rec_B = build_gen_discriminator(self.fake_pool_B, "d_B")
def loss_calc(self):
'''
函数功能:损失函数计算
d_loss_A/d_loss_B -> loss of discriminator A/B
g_loss_A/g_loss_B -> loss of generator A/B
:return:
'''
# Cycle损失,需要最小化输入图像向量和经过一个Cycle后转回来图像向量
cyc_loss = tf.reduce_mean(tf.abs(self.input_A - self.cyc_A)) + tf.reduce_mean(tf.abs(self.input_B - self.cyc_B))
# 鉴别器损失,需要将经过一个Cycle操作出来图像认为越真越好
disc_loss_A = tf.reduce_mean(tf.squared_difference(self.fake_rec_A, 1))
disc_loss_B = tf.reduce_mean(tf.squared_difference(self.fake_rec_B, 1))
g_loss_A = cyc_loss * 10 + disc_loss_B
g_loss_B = cyc_loss * 10 + disc_loss_A
d_loss_A = (tf.reduce_mean(tf.square(self.fake_pool_rec_A)) + tf.reduce_mean(tf.squared_difference(self.rec_A, 1))) / 2.0
d_loss_B = (tf.reduce_mean(tf.square(self.fake_pool_rec_B)) + tf.reduce_mean(tf.squared_difference(self.rec_B, 1))) / 2.0
optimizer = tf.train.AdamOptimizer(self.lr, beta1=0.5)
self.model_vars = tf.trainable_variables()
d_A_vars = [var for var in self.model_vars if 'd_A' in var.name]
g_A_vars = [var for var in self.model_vars if 'g_A' in var.name]
d_B_vars = [var for var in self.model_vars if 'd_B' in var.name]
g_B_vars = [var for var in self.model_vars if 'g_B' in var.name]
self.d_A_trainer = optimizer.minimize(d_loss_A, var_list=d_A_vars)
self.d_B_trainer = optimizer.minimize(d_loss_B, var_list=d_B_vars)
self.g_A_trainer = optimizer.minimize(g_loss_A, var_list=g_A_vars)
self.g_B_trainer = optimizer.minimize(g_loss_B, var_list=g_B_vars)
for var in self.model_vars:
print(var.name)
#为tensorboard汇总变量
#tf.summary.scalar用来显示标量信息,在画loss和accuracy曲线时需要
self.g_A_loss_summ = tf.summary.scalar("g_A_loss", g_loss_A)
self.g_B_loss_summ = tf.summary.scalar("g_B_loss", g_loss_B)
self.d_A_loss_summ = tf.summary.scalar("d_A_loss", d_loss_A)
self.d_B_loss_summ = tf.summary.scalar("d_B_loss", d_loss_B)
def save_training_images(self, sess, epoch):
if not os.path.exists("./output/imgs"):
os.makedirs("./output/imgs")
for i in range(0, 10):
fake_A_temp, fake_B_temp, cyc_A_temp, cyc_B_temp = sess.run([self.fake_A, self.fake_B, self.cyc_A, self.cyc_B],
feed_dict={self.input_A:self.A_input[i], self.input_B:self.B_input[i]})
imsave("./output/imgs/fakeB_" + str(epoch) + "_" + str(i) + ".jpg", ((fake_A_temp[0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/fakeA_" + str(epoch) + "_" + str(i) + ".jpg", ((fake_B_temp[0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/cycA_" + str(epoch) + "_" + str(i) + ".jpg", ((cyc_A_temp[0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/cycB_" + str(epoch) + "_" + str(i) + ".jpg", ((cyc_B_temp[0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/inputA_" + str(epoch) + "_" + str(i) + ".jpg", ((self.A_input[i][0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/inputB_" + str(epoch) + "_" + str(i) + ".jpg", ((self.B_input[i][0] + 1) * 127.5).astype(np.uint8))
def fake_image_pool(self, num_fakes, fake, fake_pool):
'''
函数功能:计算每一张产生的图片的discriminator loss总和代价是十分昂贵的,为了加速
训练使用了fake_pool保存之前生成的固定个数的fake_image并且随机使用其中一个计算loss
'''
if num_fakes < pool_size:
fake_pool[num_fakes] = fake
return fake
else:
p = random.random()
if p > 0.5:
random_id = random.randint(0, pool_size-1)
temp = fake_pool[random_id]
fake_pool[random_id] = fake
return temp
else:
return fake
def train(self):
'''
函数功能:训练
:return:
'''
# 加载数据
self.input_setup()
# 建立网络
self.model_setup()
# 计算损失函数
self.loss_calc()
# 初始化变量
init = tf.global_variables_initializer()
init2 = tf.local_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
sess.run(init2)
#将input读入到numpy数组
self.input_read(sess)
#从最近的一次checkpoint继续训练
if to_restore:
chkpt_frame = tf.train.latest_checkpoint(check_dir)
saver.restore(sess, chkpt_frame)
writer = tf.summary.FileWriter("./output/2") #记录tensorflow的默认图
if not os.path.exists(check_dir):
os.makedirs(check_dir)
#训练循环
start_time = time.time()
for epoch in range(sess.run(self.global_step), max_epoch):
print("In the epoch ", epoch)
saver.save(sess, os.path.join(check_dir, "cyclegan"), global_step=epoch)
#调整学习率
if epoch < 100:
curr_lr = 0.0002
else:
curr_lr = 0.0002 - 0.0002 *(epoch - 100) / 100
if save_training_images:
self.save_training_images(sess, epoch)
for ptr in range(0, max_images):
print("In the iteration ", ptr)
#Optimizing the G_A network
_, fake_B_temp, summary_str = sess.run([self.g_A_trainer, self.fake_B, self.g_A_loss_summ],
feed_dict={self.input_A:self.A_input[ptr], self.input_B:self.B_input[ptr], self.lr:curr_lr})
writer.add_summary(summary_str, epoch*max_images + ptr)
fake_B_temp1 = self.fake_image_pool(self.num_fake_inputs, fake_B_temp, self.fake_images_B)
#Optimizing the D_B network
_, summary_str = sess.run([self.d_B_trainer, self.d_B_loss_summ], feed_dict={self.input_A:self.A_input[ptr], self.input_B:self.B_input[ptr],
self.lr:curr_lr, self.fake_pool_B:fake_B_temp1})
writer.add_summary(summary_str, epoch*max_images + ptr)
#Optimizing the G_B network
_, fake_A_temp, summary_str = sess.run([self.g_B_trainer, self.fake_A, self.g_B_loss_summ],
feed_dict={self.input_A:self.A_input[ptr], self.input_B:self.B_input[ptr], self.lr:curr_lr})
writer.add_summary(summary_str, epoch*max_images + ptr)
fake_A_temp1 = self.fake_image_pool(self.num_fake_inputs, fake_A_temp, self.fake_images_A)
print(fake_A_temp1.shape)
#Optimizing the D_A network
_, summary_str = sess.run([self.d_A_trainer, self.d_A_loss_summ], feed_dict={self.input_A:self.A_input[ptr], self.input_B:self.B_input[ptr],
self.lr:curr_lr, self.fake_pool_A:fake_A_temp1})
writer.add_summary(summary_str, epoch*max_images + ptr)
hour = int((time.time() - start_time) / 3600)
min = int(((time.time() - start_time) - 3600 * hour) / 60)
sec = int((time.time() - start_time) - 3600 * hour - 60 * min)
print("Time: ", hour, "h: ", min, "min", sec, "sec")
self.num_fake_inputs += 1
sess.run(tf.assign(self.global_step, epoch + 1))
writer.add_graph(sess.graph)
def test(self):
'''
函数功能:测试
:return:
'''
print("Testing the results")
self.input_setup()
self.model_setup()
saver = tf.train.Saver()
init = tf.global_variables_initializer()
init2 = tf.local_variables_initializer()
with tf.Session() as sess:
sess.run(init)
sess.run(init2)
self.input_read(sess)
chkpt_frame = tf.train.latest_checkpoint(check_dir)
saver.restore(sess, chkpt_frame)
if not os.path.exists("./output/imgs/test/"):
os.makedirs("./output/imgs/test/")
for i in range(0, 100):
fake_A_temp, fake_B_temp = sess.run([self.fake_A, self.fake_B], feed_dict={self.input_A:self.A_input[i], self.input_B:self.B_input[i]})
imsave("./output/imgs/test/fakeB_" + str(i) + ".jpg", ((fake_A_temp[0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/test/fakeA_" + str(i) + ".jpg", ((fake_B_temp[0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/test/inputA_" + "_" + str(i) + ".jpg", ((self.A_input[i][0] + 1) * 127.5).astype(np.uint8))
imsave("./output/imgs/test/inputB_" + "_" + str(i) + ".jpg", ((self.B_input[i][0] + 1) * 127.5).astype(np.uint8))
if __name__ == '__main__':
model = CycleGAN()
if to_train:
model.train()
elif to_test:
model.test()
效果图
- 马和斑马的转换