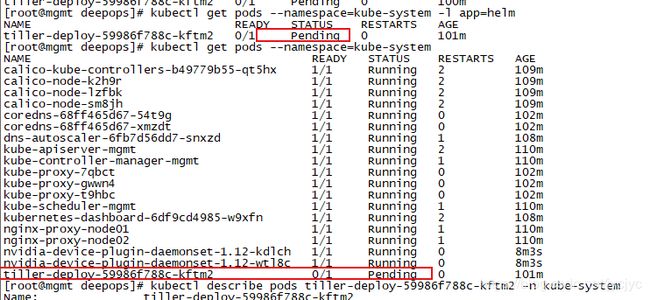
1 node(s) had taints that the pod didn't tolerate, 2 node(s) didn't match node selector.
[root@mgmt deepops]# kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-b49779b55-qt5hx 1/1 Running 2 104m
calico-node-k2h9r 1/1 Running 2 105m
calico-node-lzfbk 1/1 Running 2 105m
calico-node-sm8jh 1/1 Running 2 105m
coredns-68ff465d67-54t9g 1/1 Running 0 97m
coredns-68ff465d67-xmzdt 1/1 Running 0 97m
dns-autoscaler-6fb7d56dd7-snxzd 1/1 Running 1 104m
kube-apiserver-mgmt 1/1 Running 2 105m
kube-controller-manager-mgmt 1/1 Running 1 105m
kube-proxy-7qbct 1/1 Running 0 98m
kube-proxy-gwwn4 1/1 Running 0 98m
kube-proxy-t9hbc 1/1 Running 0 98m
kube-scheduler-mgmt 1/1 Running 1 105m
kubernetes-dashboard-6df9cd4985-w9xfn 1/1 Running 2 104m
nginx-proxy-node01 1/1 Running 1 105m
nginx-proxy-node02 1/1 Running 1 105m
nvidia-device-plugin-daemonset-1.12-kdlch 1/1 Running 0 3m38s
nvidia-device-plugin-daemonset-1.12-wtl8c 1/1 Running 0 3m38s
tiller-deploy-59986f788c-kftm2 0/1 Pending 0 97m
[root@mgmt deepops]# kubectl get pods --namespace=kube-system -l app=helm
NAME READY STATUS RESTARTS AGE
tiller-deploy-59986f788c-kftm2 0/1 Pending 0 100m
[root@mgmt deepops]# kubectl get pods --namespace=kube-system -l app=helm
NAME READY STATUS RESTARTS AGE
tiller-deploy-59986f788c-kftm2 0/1 Pending 0 101m
[root@mgmt deepops]# kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-b49779b55-qt5hx 1/1 Running 2 109m
calico-node-k2h9r 1/1 Running 2 109m
calico-node-lzfbk 1/1 Running 2 109m
calico-node-sm8jh 1/1 Running 2 109m
coredns-68ff465d67-54t9g 1/1 Running 0 102m
coredns-68ff465d67-xmzdt 1/1 Running 0 102m
dns-autoscaler-6fb7d56dd7-snxzd 1/1 Running 1 108m
kube-apiserver-mgmt 1/1 Running 2 110m
kube-controller-manager-mgmt 1/1 Running 1 110m
kube-proxy-7qbct 1/1 Running 0 102m
kube-proxy-gwwn4 1/1 Running 0 102m
kube-proxy-t9hbc 1/1 Running 0 102m
kube-scheduler-mgmt 1/1 Running 1 110m
kubernetes-dashboard-6df9cd4985-w9xfn 1/1 Running 2 108m
nginx-proxy-node01 1/1 Running 1 110m
nginx-proxy-node02 1/1 Running 1 110m
nvidia-device-plugin-daemonset-1.12-kdlch 1/1 Running 0 8m3s
nvidia-device-plugin-daemonset-1.12-wtl8c 1/1 Running 0 8m3s
tiller-deploy-59986f788c-kftm2 0/1 Pending 0 101m
[root@mgmt deepops]# kubectl describe pods tiller-deploy-59986f788c-kftm2 -n kube-system
Name: tiller-deploy-59986f788c-kftm2
Namespace: kube-system
Priority: 2000000000
PriorityClassName: system-cluster-critical
Node:
Labels: app=helm
name=tiller
pod-template-hash=59986f788c
Annotations:
Status: Pending
IP:
Controlled By: ReplicaSet/tiller-deploy-59986f788c
Containers:
tiller:
Image: 192.168.202.122:5001/kubernetes-helm/tiller:v2.11.0
Ports: 44134/TCP, 44135/TCP
Host Ports: 0/TCP, 0/TCP
Liveness: http-get http://:44135/liveness delay=1s timeout=1s period=10s #success=1 #failure=3
Readiness: http-get http://:44135/readiness delay=1s timeout=1s period=10s #success=1 #failure=3
Environment:
TILLER_NAMESPACE: kube-system
TILLER_HISTORY_MAX: 0
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from tiller-token-dtfn5 (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
tiller-token-dtfn5:
Type: Secret (a volume populated by a Secret)
SecretName: tiller-token-dtfn5
Optional: false
QoS Class: BestEffort
Node-Selectors: node-role.kubernetes.io/master=
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 13m (x7 over 102m) default-scheduler 0/3 nodes are available: 1 node(s) had taints that the pod didn't tolerate, 2 node(s) didn't match node selector.
[root@mgmt deepops]# vi get.py
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import requests
import json
import traceback
repo_ip = '192.168.202.122'
repo_port = 5001
def getImagesNames(repo_ip,repo_port):
docker_images = []
try:
url = "http://" + repo_ip + ":" +str(repo_port) + "/v2/_catalog"
res =requests.get(url).content.strip()
res_dic = json.loads(res)
images_type = res_dic['repositories']
for i in images_type:
url2 = "http://" + repo_ip + ":" +str(repo_port) +"/v2/" + str(i) + "/tags/list"
res2 =requests.get(url2).content.strip()
res_dic2 = json.loads(res2)
name = res_dic2['name']
tags = res_dic2['tags']
for tag in tags:
docker_name = str(repo_ip) + ":" + str(repo_port) + "/" + name + ":" + tag
docker_images.append(docker_name)
print docker_name
except:
traceback.print_exc()
return docker_images
a=getImagesNames(repo_ip, repo_port)
~
"get.py" [New] 33L, 1067C written
[root@mgmt deepops]# python get.py
192.168.202.122:5001/calico/cni:v3.1.3
192.168.202.122:5001/calico/ctl:v3.1.3
192.168.202.122:5001/calico/kube-controllers:v3.1.3
192.168.202.122:5001/calico/node:v3.1.3
192.168.202.122:5001/coredns/coredns:1.2.6
192.168.202.122:5001/coreos/etcd:v3.2.24
192.168.202.122:5001/deepops/apt-online:latest
192.168.202.122:5001/external_storage/local-volume-provisioner:v2.1.0
192.168.202.122:5001/google-containers/coredns:1.2.2
192.168.202.122:5001/google-containers/kube-apiserver:v1.12.5
192.168.202.122:5001/google-containers/kube-controller-manager:v1.12.5
192.168.202.122:5001/google-containers/kube-proxy:v1.12.5
192.168.202.122:5001/google-containers/kube-scheduler:v1.12.5
192.168.202.122:5001/google_containers/cluster-proportional-autoscaler-amd64:1.3.0
192.168.202.122:5001/google_containers/kubernetes-dashboard-amd64:v1.10.0
192.168.202.122:5001/google_containers/pause:3.1
192.168.202.122:5001/google_containers/pause-amd64:3.1
192.168.202.122:5001/kubernetes-helm/tiller:v2.11.0
192.168.202.122:5001/lachlanevenson/k8s-helm:v2.11.0
192.168.202.122:5001/nginx:1.13
192.168.202.122:5001/nvidia/k8s-device-plugin:1.11
[root@mgmt deepops]# docker images|grep tiller
192.168.202.122:5001/kubernetes-helm/tiller v2.11.0 ac5f7ee9ae7e 7 months ago 71.8MB
[root@mgmt deepops]# kubectl taint nodes --all
error: at least one taint update is required
[root@mgmt deepops]# kubectl taint nodes --all node-role.kubernetes.io/master-
node/mgmt untainted
taint "node-role.kubernetes.io/master:" not found
taint "node-role.kubernetes.io/master:" not found
[root@mgmt deepops]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
mgmt Ready master 117m v1.12.5
node01 Ready node 116m v1.12.5
node02 Ready node 116m v1.12.5
[root@mgmt deepops]# kubectl describe pods tiller-deploy-59986f788c-kftm2 -n kube-system
Name: tiller-deploy-59986f788c-kftm2
Namespace: kube-system
Priority: 2000000000
PriorityClassName: system-cluster-critical
Node: mgmt/192.168.52.128
Start Time: Wed, 08 May 2019 17:01:28 +0800
Labels: app=helm
name=tiller
pod-template-hash=59986f788c
Annotations:
Status: Running
IP: 10.233.94.133
Controlled By: ReplicaSet/tiller-deploy-59986f788c
Containers:
tiller:
Container ID: docker://6d5c1a3a070c65a7cdf8c1e117b4fc1941dfc545b9736521176f525ab7eebbcd
Image: 192.168.202.122:5001/kubernetes-helm/tiller:v2.11.0
Image ID: docker-pullable://192.168.202.122:5001/kubernetes-helm/tiller@sha256:f6d8f4ab9ba993b5f5b60a6edafe86352eabe474ffeb84cb6c79b8866dce45d1
Ports: 44134/TCP, 44135/TCP
Host Ports: 0/TCP, 0/TCP
State: Running
Started: Wed, 08 May 2019 17:01:29 +0800
Ready: True
Restart Count: 0
Liveness: http-get http://:44135/liveness delay=1s timeout=1s period=10s #success=1 #failure=3
Readiness: http-get http://:44135/readiness delay=1s timeout=1s period=10s #success=1 #failure=3
Environment:
TILLER_NAMESPACE: kube-system
TILLER_HISTORY_MAX: 0
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from tiller-token-dtfn5 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
tiller-token-dtfn5:
Type: Secret (a volume populated by a Secret)
SecretName: tiller-token-dtfn5
Optional: false
QoS Class: BestEffort
Node-Selectors: node-role.kubernetes.io/master=
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 20m (x7 over 109m) default-scheduler 0/3 nodes are available: 1 node(s) had taints that the pod didn't tolerate, 2 node(s) didn't match node selector.
Normal Scheduled 42s default-scheduler Successfully assigned kube-system/tiller-deploy-59986f788c-kftm2 to mgmt
Normal Pulled 41s kubelet, mgmt Container image "192.168.202.122:5001/kubernetes-helm/tiller:v2.11.0" already present on machine
Normal Created 41s kubelet, mgmt Created container
Normal Started 41s kubelet, mgmt Started container
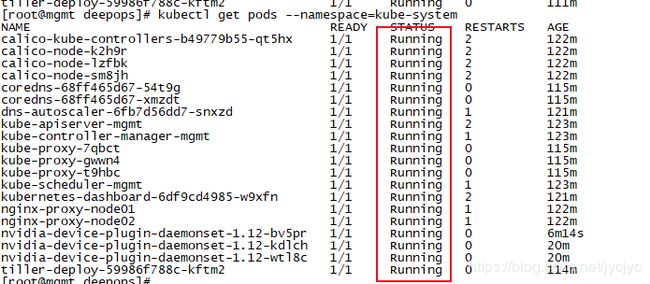
[root@mgmt deepops]# kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-b49779b55-qt5hx 1/1 Running 2 116m
calico-node-k2h9r 1/1 Running 2 116m
calico-node-lzfbk 1/1 Running 2 116m
calico-node-sm8jh 1/1 Running 2 116m
coredns-68ff465d67-54t9g 1/1 Running 0 109m
coredns-68ff465d67-xmzdt 1/1 Running 0 109m
dns-autoscaler-6fb7d56dd7-snxzd 1/1 Running 1 116m
kube-apiserver-mgmt 1/1 Running 2 117m
kube-controller-manager-mgmt 1/1 Running 1 117m
kube-proxy-7qbct 1/1 Running 0 110m
kube-proxy-gwwn4 1/1 Running 0 110m
kube-proxy-t9hbc 1/1 Running 0 110m
kube-scheduler-mgmt 1/1 Running 1 117m
kubernetes-dashboard-6df9cd4985-w9xfn 1/1 Running 2 116m
nginx-proxy-node01 1/1 Running 1 117m
nginx-proxy-node02 1/1 Running 1 117m
nvidia-device-plugin-daemonset-1.12-bv5pr 1/1 Running 0 58s
nvidia-device-plugin-daemonset-1.12-kdlch 1/1 Running 0 15m
nvidia-device-plugin-daemonset-1.12-wtl8c 1/1 Running 0 15m
tiller-deploy-59986f788c-kftm2 1/1 Running 0 109m
[root@mgmt deepops]# kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-b49779b55-qt5hx 1/1 Running 2 119m
calico-node-k2h9r 1/1 Running 2 119m
calico-node-lzfbk 1/1 Running 2 119m
calico-node-sm8jh 1/1 Running 2 119m
coredns-68ff465d67-54t9g 1/1 Running 0 112m
coredns-68ff465d67-xmzdt 1/1 Running 0 111m
dns-autoscaler-6fb7d56dd7-snxzd 1/1 Running 1 118m
kube-apiserver-mgmt 1/1 Running 2 120m
kube-controller-manager-mgmt 1/1 Running 1 120m
kube-proxy-7qbct 1/1 Running 0 112m
kube-proxy-gwwn4 1/1 Running 0 112m
kube-proxy-t9hbc 1/1 Running 0 112m
kube-scheduler-mgmt 1/1 Running 1 120m
kubernetes-dashboard-6df9cd4985-w9xfn 1/1 Running 2 118m
nginx-proxy-node01 1/1 Running 1 119m
nginx-proxy-node02 1/1 Running 1 119m
nvidia-device-plugin-daemonset-1.12-bv5pr 1/1 Running 0 3m5s
nvidia-device-plugin-daemonset-1.12-kdlch 1/1 Running 0 17m
nvidia-device-plugin-daemonset-1.12-wtl8c 1/1 Running 0 17m
tiller-deploy-59986f788c-kftm2 1/1 Running 0 111m
[root@mgmt deepops]#
https://segmentfault.com/a/1190000017010166?utm_source=tag-newest
https://my.oschina.net/eima/blog/1860598
master node参与工作负载 (只在主节点执行)
使用kubeadm初始化的集群,出于安全考虑Pod不会被调度到Master Node上,也就是说Master Node不参与工作负载。
这里搭建的是测试环境可以使用下面的命令使Master Node参与工作负载:
k8s是master节点的hostname
允许master节点部署pod,使用命令如下:
kubectl taint nodes --all node-role.kubernetes.io/master-
输出如下:
node "k8s" untainted
输出error: taint “node-role.kubernetes.io/master:” not found错误忽略。
禁止master部署pod
kubectl taint nodes k8s node-role.kubernetes.io/master=true:NoSchedule