Caffe阅读代码并修改
这个教程是最好理解的了
http://city.shaform.com/blog/2016/02/26/caffe.html
主要分成四個部份來講。首先是整個 Caffe 的大架構,以及一些重要的元件。 其次,我也研究了如何自己新增一個 layer。 接下來,再重新回到 Caffe 做更深入的解析。
架構
那麼,就從大架構開始講起。 Caffe 的 command line 工具有幾個功能,他可以讓你 train 一個 model, 也可以讓你用 train 好的 model 來進行效能的檢驗。當他在做 training 時, 他會建立一個 Solver 物件,他的主要功能就是協調類神經網路的運作來進行訓練。
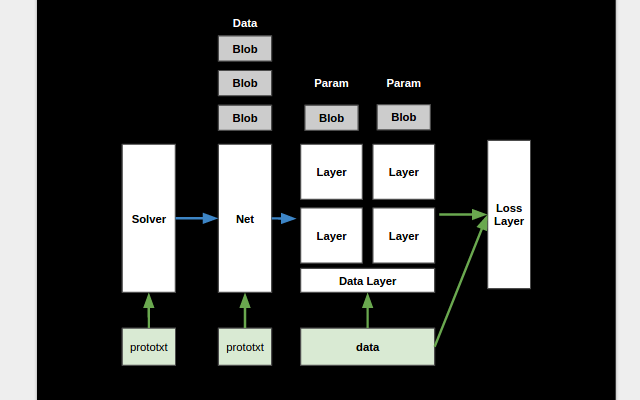
我們可以用一個設定檔來指定 Solver 的參數,像是 learning rate 或者是 Solver 的種類, 例如 SGD Solver 等等。在設定檔中,可以指定一個 training net 的參數, testing nets 則有可能有多個。例如如果要用不同的 data set 同時驗證 model 的效能時就可以用到。 雖然也可以直接把網路定義寫在 Solver 的設定檔裡,不過範例程式碼通常把他寫在獨立的設定檔中。
Solver 會根據這些設定檔,建立相對應的 training 和 testing 的 Net 物件。而 Net, 就會根據整個網路的定義,建立每個 Layer,同時也會建立很多的 Blobs 來放置 Layer 跟 Layer 間的輸出入資料,並把他們都接起來。其中,一個 layer 的輸入被稱為 bottom blobs,輸出則為 top blobs。 Blob 基本上是一個多維陣列,不過他除了用來放 Data 外, 也同時包含一組對應的 Diff,可以用來放 Gradient 的計算結果。這些 Blobs 提供了簡易的界面, 可以讓 Layer 透過 GPU 或 CPU 來存取裡頭的資料。
而這些 Layers 除了有計算的功能以外,也有一些特別的 data layers 可以把資料從檔案中讀進來, 或者把輸出的結果寫到特定的檔案。此外,也有一些 loss layer 是用來計算最後預測結果的分數, 並藉此資訊讓 solver 得以最佳化所有的參數。每個 layer 會建立額外的 blobs 來放置這些可訓練的參數, 而 Net 在建立 layer 時,會把這些 blobs 也收集起來,方便 Solver 根據 learning rate 來計算每個參數的更新值。 當 Solver 呼叫了 Net 的 Forward 和 Backward 之後,資料就會沿著一層一層的 layer 進行計算。
新增 Layer
講完大略的架構後。我們就可以把焦點放在新增 layers 上。
要新增一個 layer,官方其實有提供簡單的指引。 但除了單純的看文件之外,我們其實也可以參考看看以前的人是怎麼做的。
沒有錯,理論上應該有不同的人、在不同的時間點。分別新增了不同的 layers。 只要找出這些 commits 並且觀察裡頭的內容,應該就可以推測出要如何新增了。
所以,我選了兩個 pull requests: #1940, #303,並且對照他們修改的檔案。
很快的,就可以看出其中的規律。他們都修改了一個叫做 caffe.proto 的檔案, 用來定義 layer 可以設定的參數。 HingeLoss 的修改還改動了 layer factory,不過看起來是因為以前在新增 layer 時, 要修改一個選擇 layer 的函數。 現在的 layer 都被放進一個 dictionary 裡,透過名稱取出,所以就不需要這種修改了。 只有一些有 cuDNN 實作的 layers 會在這裡放一個特別的函數來選擇實作的引擎。
接下來 src/caffe/layers/*, include/caffe/* 等檔案,則是 layer 實際的宣告以及實作。 以前 layer 的宣告依照分類被放置在不同的地方。 比如說 neuron_layers.hpp 通常是放進行 element-wise operations 的 layers。vision_layers.hpp 則是放跟影像比較相關的 layers。 不過後來不同的 layers 就被搬到獨立的檔案了。
最後 src/caffe/test/* 則是一些測試。
於是我就實際的修改看看,我要加入一個很簡單的 layer, 他會把所有的輸入乘上一個事先指定的參數。 我在 caffe.proto 修改了三個地方,包含下個可用的 ID、放置參數的變數, 和實際的 layer 參數,也就是要乘上的那個常數。
// src/caffe/proto/caffe.proto
// LayerParameter next available layer-specific ID: 144 (last added: zzz_param)
message LayerParameter {
// ...
optional ZZZParameter zzz_param = 143;
}
// Message that stores parameters used by ZZZLayer
message ZZZParameter {
// Whether or not slope paramters are shared across channels.
optional int32 mul = 1 [default = 2];
}
然後,我複製了一些簡單的宣告。其中主要的修改只有新增了一個 mul 參數,用來存放要乘的常數。
// include/caffe/layers/zzz_layer.hpp
template <typename Dtype>
class ZZZLayer : public NeuronLayer<Dtype> {
public:
explicit ZZZLayer(const LayerParameter& param)
: NeuronLayer<Dtype>(param) {}
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline const char* type() const { return "ZZZ"; }
protected:
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
Dtype mul_;
};
實作的部份因為初始化很簡單,只有讀取將來要乘的常數,所以主要的實作只有 Forward 和 Backward。 不過一些複雜的 layers 可能就會需要實作一些複雜的初始化,和計算輸出維度大小的函數。 Neuron layer 因為是 element-wise ,所以輸出的維度大小就跟輸入一樣。
Forward的部份,是先把 bottom_data 複製到 top,然後再將整個 top scale 指定的常數。
// src/caffe/layers/zzz_layer.cpp
template <typename Dtype>
void ZZZLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype> *> &bottom,
const vector<Blob<Dtype> *> &top) {
const int count = bottom[0]->count();
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
caffe_copy(count, bottom_data, top_data);
if (mul_ != Dtype(1)) {
caffe_scal(count, mul_, top_data);
}
}
Backward 也很類似,確定需要計算後,先把 top_diff 複製到 bottom_diff 再 scale 指定的常數。
// src/caffe/layers/zzz_layer.cpp
template <typename Dtype>
void ZZZLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype> *> &top,
const vector<bool> &propagate_down,
const vector<Blob<Dtype> *> &bottom) {
if (propagate_down[0]) {
const int count = top[0]->count();
const Dtype *top_diff = top[0]->cpu_diff();
Dtype *bottom_diff = bottom[0]->mutable_cpu_diff();
caffe_copy(count, top_diff, bottom_diff);
caffe_scal(count, mul_, bottom_diff);
}
}
CUDA 的版本也很類似,只是從 blob 要取出 gpu data ,然後 scale 時要選 GPU 的版本。
// src/caffe/layers/zzz_layer.cu
template <typename Dtype>
void ZZZLayer<Dtype>::Forward_gpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
const int count = bottom[0]->count();
const Dtype* bottom_data = bottom[0]->gpu_data();
Dtype* top_data = top[0]->mutable_gpu_data();
caffe_copy(count, bottom_data, top_data);
if (mul_ != Dtype(1)) {
caffe_gpu_scal(count, mul_, top_data);
}
}
template <typename Dtype>
void ZZZLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
if (propagate_down[0]) {
const int count = top[0]->count();
const Dtype *top_diff = top[0]->gpu_diff();
Dtype *bottom_diff = bottom[0]->mutable_gpu_diff();
caffe_copy(count, top_diff, bottom_diff);
caffe_gpu_scal(count, mul_, bottom_diff);
}
}
最後我們再加一些 test,檢查 forward 確實成功乘上參數。
// src/caffe/test/test_zzz_layer.cpp
TYPED_TEST(NeuronLayerTest, TestZZZForward) {
typedef typename TypeParam::Dtype Dtype;
LayerParameter layer_param;
ZZZLayer<Dtype> layer(layer_param);
layer.SetUp(this->blob_bottom_vec_, this->blob_top_vec_);
layer.Forward(this->blob_bottom_vec_, this->blob_top_vec_);
const Dtype* bottom_data = this->blob_bottom_->cpu_data();
const Dtype* top_data = this->blob_top_->cpu_data();
const int count = this->blob_bottom_->count();
const int mul = layer_param.zzz_param().mul();
for (int i = 0; i < count; ++i) {
EXPECT_FLOAT_EQ(top_data[i], bottom_data[i]*mul);
}
}
同時也檢查用數值方法計算出來的 gradient 跟我們算的是否一樣。
// src/caffe/test/test_zzz_layer.cpp
TYPED_TEST(NeuronLayerTest, TestZZZBackward) {
typedef typename TypeParam::Dtype Dtype;
LayerParameter layer_param;
ZZZLayer<Dtype> layer(layer_param);
GradientChecker<Dtype> checker(1e-2, 1e-3, 1701, 0., 0.01);
checker.CheckGradientEltwise(&layer, this->blob_bottom_vec_,
this->blob_top_vec_);
}
最後就可以實際測試看看。並看到測試的結果了。以上就是新增 layer 的部份。
[----------] 2 tests from ZZZLayerTest/1, where TypeParam = caffe::CPUDevice
[ RUN ] ZZZLayerTest/1.TestZZZBackward
[ OK ] ZZZLayerTest/1.TestZZZBackward (2 ms)
[ RUN ] ZZZLayerTest/1.TestZZZForward
[ OK ] ZZZLayerTest/1.TestZZZForward (0 ms)
[----------] 2 tests from ZZZLayerTest/1 (2 ms total)
Dive into Caffe
好,講完新增 layer 之後,這次可以更深入的研究 Caffe 的內部架構。
一開始我先到網路上搜尋了一下教學文件,包含官方的內容、課程的教學、或者是網友在問要怎麼讀 Caffe,以及各種網友的分享。最後再直接開始讀程式碼。
- Caffe
- DIY Deep Learning for Vision
- CS231n Caffe Tutorial
- 深度学习caffe的代码怎么读?
- Caffe学习笔记
- caffe笔记之例程学习
- How do we read the source code of Caffe?
- Caffe代码导读
剛剛已經講過 Caffe 的大致架構,不過實際上每個部件是怎麼互動的呢? 我們先從程式流程講起,之後再特別介紹 layers 的功能。
Training
以 training 的部份來說,程式實際上做的事大致如下:首先,載入參數,設定 GPU 等初始化。 接著,利用這些參數初始化一個 Solver 物件。接下來,如果是要載入 train 好的 weights 來 fine-tune 的話,就會直接把這些 weights 讀進 solver 裡頭的 Net 物件裡。 如果是要繼續進行到一半的 training 的話,則會把 snapshot 檔案當作參數傳給 Solver 的 solve。 否則就直接呼叫 Solve 開始 training 了。
而根據 Solver 種類的不同,會初始化一些不同的參數。但他們都會根據設定檔建立 training nets 以及 testing nets 等物件。
Initialize Net
每個 Net 被建立時會經過下列流程:
首先根據一些條件過濾掉參數中指定的 layers,比如說你可以把 testing 和 training 的 net 寫在一起,然後 input layer 分成兩個,一個只有在 training 時才有效, 另一個則在 testing 才有效,這樣在建立 Net 物件時依據不同階段,就會過濾掉不要的 input layer,達成載入不同的 data set 的目的。
接下來則是在參數中插入 split layers。 也就是在一些 output blob 被接到多個 layer 作為 input 的時候, 在中間多加入一個 split layer ,把 blob 複製成多份作為其他層的輸入。
這麼做大概有兩個目的,首先是收集從多個方向計算的 gradient , 其次則是因為有些 layer 會做 in-place 的計算,也就是他 input 和 output 使用同一個 blob, 所以在這裡把 blob 分成多個,可以避免這種情形下的計算錯誤。
把 net 的參數經過之前的處理後,就會實際初始化 Net 物件。首先是建好網路最底層 input blobs。 再來則是按照順序一層一層的建立,並初始化每個 layers。
實際的流程是先建立 layer 物件後,先從之前的底層 input blobs 或者其他 layer 的 top blobs 中找到該 layer 的 bottom blob,也就是他的 input,然後呢,再視情況建立他的 top blob,也就是 output。
最後再用這些 input / output blobs 作為參數,完成 layer 的初始化。每個不同的 layer 會根據自己的需要分別實作不同的初始化程式。然後 net 再把該 layer 可以訓練的參數紀錄下來。
像這樣一層一層的初始化每個 layer 時,同時也找出哪些 layer 實際上需要 backward 的計算。這樣訓練時就可以節省不必要的計算。最後則是收集最後剩下來的 output blobs ,當作整個類神經網路的 output。同時也收集所有設定的 learning rate 和 weight decay。
像這樣初始化完畢後,就進到真正的 trainning 了。
Solver->Solve()
在 training 時所作的,其實就是先做一次 forward 和 backward 的計算,再更新網路中的 weight,重複循環。計算 forward 的方法就是按照 layer 的順序,呼叫每個 layer 的 forward 函數。而 backward 就是用相反的順序呼叫每個 layer 的 backward 函數。每計算完一次就會得到更新的 gradients,然後就可以更新參數。
詳細流程是這樣的,收集完這些 gradients 後 Solver 會依照 learning rates 和 weight decay 算出每個參數應該更新的實際數字。然後再把有共用參數的 layer 的更新值加在一起,最後再一次更新所有的數值。
Testing
testing 時跟 training 也很類似,不過這次不需要建立 Solver ,而是直接建立 test net,並且讀取訓練好的 weight,最後執行 forward,就可以得到最後的輸出值了。
Layers 簡介
整個程式其實最重要的計算還是在 Layers 的部份。因此,我現在就來簡單介紹到底有哪些 layers 可供使用。
Data Layers
- DataLayer: 可以載入 leveldb 和 lmdb 的檔案。
- DummyDataLayer: 用來產生一些亂數或其他預先定義的資料。
- HDF5DataLayer: 可以讀取 HDF5 的檔案格式。
- HDF5OutputLayer: 可以寫入 HDF5 的檔案格式。
- ImageDataLayer: 直接載入圖片。
- MemoryDataLayer: 可以透過程式,直接將記憶體中的資料放進 layer 中。
- WindowDataLayer: 可以指定從一些圖片中擷取一些 windows 來當作輸入,比如說同一張圖裡幾個 windows 可能標記成貓。其他地方則有狗和沒有東西的標記。
Common Layers
在 common layers 的分類中則有:
- ArgMaxLayer: 找出輸入中最大的 k 個值的 indices 或者 value。
- ConcatLayer: 連接多個 bottom blobs。
- EltwiseLayer: 他可以把多個 blobs 彼此 element-wise 進行加總,相乘,取最大等運算。
- FlattenLayer: 把輸入的 blob 變成單維陣列。
- InnerProductLayer: 其實就是輸出入全部接滿的 layers。
- MVNLayer: 指的是 mean variance normalization,可以針對輸入做整體的 normalization。
- SilenceLayer: 有點像垃圾桶,沒有輸出,只有輸入,被接到這裡的東西就會被丟掉,不會成為最後的輸出。
- SplitLayer: 把輸出複製成多份。
- SliceLayer: 把輸入切割成多分輸出。
- SoftmaxLayer: 把一組輸出,轉換成機率輸出,也就是讓他們的和 normalize 成 1。
Neuron Layers
neuron layers 主要是直接對每個元素運算。
- AbsValLayer: 取絕對值。
- DropoutLayer: 隨機丟掉某些 input。
- ExpLayer
- PowerLayer
- TanHLayer
- ThresholdLayer: 若輸入大於門檻則為 1,否則為0。
- BNLLLayer: 將輸入轉換成 binomial normal log likelihood。
- ReLULayerReLu: 則是強制輸出不能小於零。
- PReLULayerPReLU: 則多加了一個可以訓練的參數。接在後面。
- SigmoidLayer: Sigmoid 可以把輸出限制在 0~1 之間,不過現在大家好像比較常用 ReLU 就是。
Vision Layers
再來是 visions layers,其實這些 layers 都跟 CNN 有關。
- ConvolutionLayer: convolution 做的運算基本上是用數個 filter,或者說 feature detector,在原始輸入的局部小範圍中,進行一個內積運算,得到一個結果。平移這個小範圍做同樣的運算後,每個 filter 都可以得到一個個數比輸入稍微少一些的輸出。一般每個 feature detector 是用來偵測圖片中某些特定的特徵是否出現。
- DeconvolutionLayer: 反過來,把一個輸入乘上一個矩陣。比如說右邊的 4 ,乘上一個 3x3 的矩陣,然後把他加回去左邊的輸出。
- LRNLayer: LRN 則是一種 normalization 的方法,據論文上寫的,他似乎主要是用來 normalize 不同 filter 輸出的結果,讓訊號間彼此競爭,只留下一些勝利者。
- PoolingLayer: 至於最後的 pooling ,則是選一塊輸入的範圍,進行取最大值或者平均的運算。得出個數較少的輸出。
結語
感覺光是對一些運算做操作性的了解,似乎還是不能真正理解 Caffe 是如何被使用的。 未來應該要針對深度學習的理論上做更多研究才行。