爬虫入门教程 | 使用Python实现简单爬虫
介绍
一段自动抓取互联网信息的程序称为爬虫,主要组成:爬虫调度器、URL管理器、网页下载器、网页解析器
(1)爬虫调度器:程序的入口,主要负责爬虫程序的控制
(2)URL管理器: 1、添加新的URL到代爬取集合2、判断待添加URL是否已存在3、判断是否还有待爬取的URL,将URL从待爬取集合移动到已爬取集合
URL存储方式:Python内存即set()集合,关系数据库、缓存数据库
(3)网页下载器:根据URL获取网页内容,实现由有urllib2和request
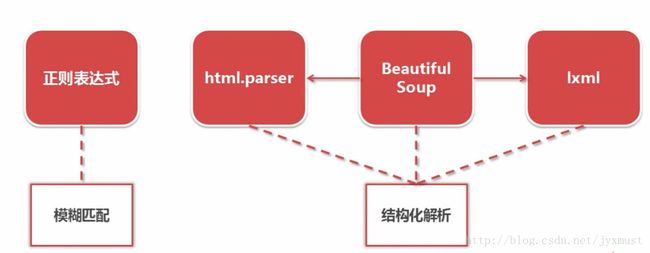
(4)网页解析器:从网页中提取出有价值的数据,实现方法有:正则表达式、html.parser、BeautifulSoup、lxml
网页下载器-urllib2
第一种
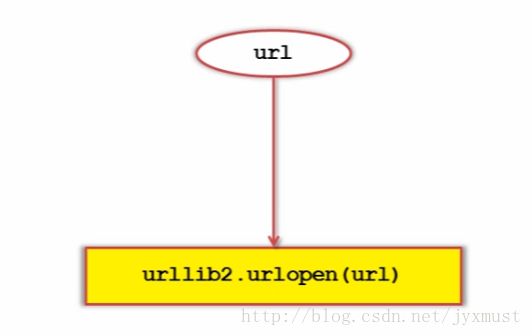
import urllib2
#直接请求
response=urllib2.urlopen('http://www.baidu.com')
#获取状态码,如果是200表示获取成功
print response.getcode()
#读取内容
cont=response.read()第二种:添加data、http header
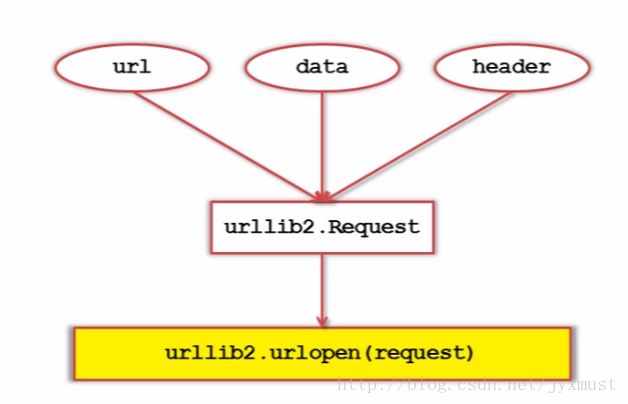
import urllib2
#创建Request对象
request=urllib2.Request(url)
#添加数据
request.add_data('a','1')
#添加http的header
request.add_header('User-Agent','Mozilla/5.0')
#发送请求获取结果
response=urllib2.urlopen(request)第三种:添加特殊情景的处理器
1、需要登录、需要代理、HTTPS加密访问、url自动跳转
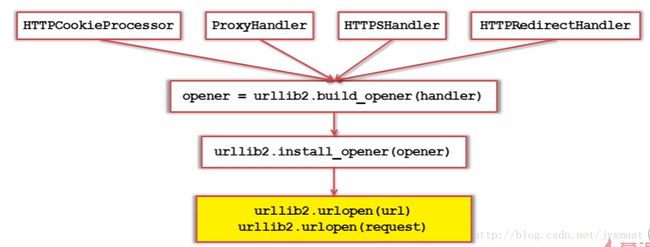
import urllib2,cookielib
#创建cookie容器
cj=cookielib.CookieJar()
#创建1个opener
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
#urllib2安装opener
urllib2.install_opener(opener)
#使用带有cookie的urllib2访问网页
response=urllib2.urlopen("http://www.baidu.com/")import urllib.request
import http.cookiejar
url="http://www.baidu.com"
print("第一种方法")
response1=urllib.request.urlopen(url)
html=response1.read()
code=response1.getcode()
print(code)
print(len(html))
print("第二种方法")
request=urllib.request.Request(url)
request.add_header("user-agent","Mozilla/5.0")
response2=urllib.request.urlopen(request)
print(response2.getcode())
print(len(response2.read()))
print("第三种方法")
cj=http.cookiejar.CookieJar()
opener=urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
urllib.request.install_opener(opener)
response3=urllib.request.urlopen(url)
print(response3.getcode())
print(cj)
print(response3.read())
网页解析器
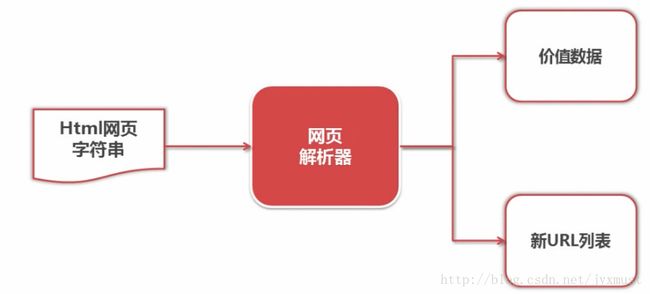
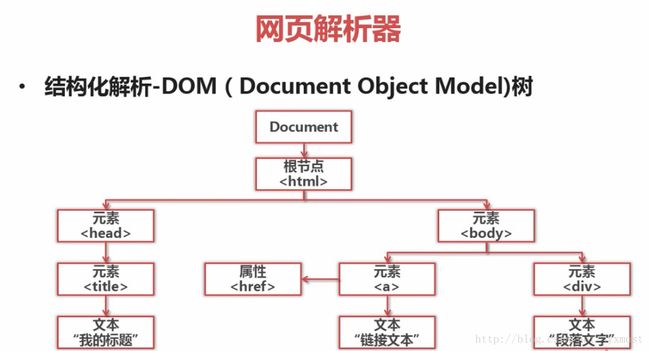
结构化解析-DOM(Document Object Model)树
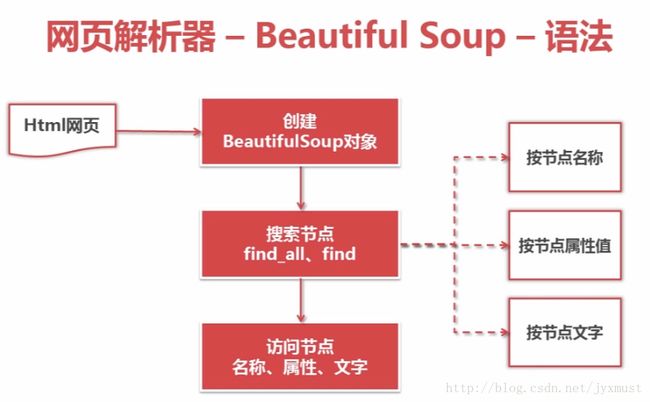
import re
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup=BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8')
print("获取所有的链接")
links=soup.find_all('a')
for link in links:
print(link.name,link['href'],link.get_text())
print("获取lacie的链接")
link_node=soup.find('a',href='http://example.com/lacie')
print(link_node.name,link_node['href'],link_node.get_text())
print("获取正则匹配表达式")
link_node=soup.find('a',href=re.compile(r'ill'))
print(link_node.name,link_node['href'],link_node.get_text())
print("p段落名字")
link_node=soup.find('p',class_='title')
print(link_node.name,link_node.get_text())运行结果
获取所有的链接
a http://example.com/elsie Elsie
a http://example.com/lacie Lacie
a http://example.com/tillie Tillie
获取lacie的链接
a http://example.com/lacie Lacie
获取正则匹配表达式
a http://example.com/tillie Tillie
p段落名字
p The Dormouse’s story
实例爬虫-爬取百度百科1000个页面的数据
确定目标-》分析目标(URL格式、数据格式、网页编码)-》编写代码-》执行爬虫
程序思路:主程序从初始URL开始,先通过URL管理器将初始URL放入待爬集合,再循环从待爬集合中获取URL,使用网页下载器获取URL指向网页,再对网页进行解析获取价值数据和关联URL,关联URL经判断再由URL管理器存入待爬集合,继续进行循环直到复合跳出条件或待爬集合为空。
1、准备工作
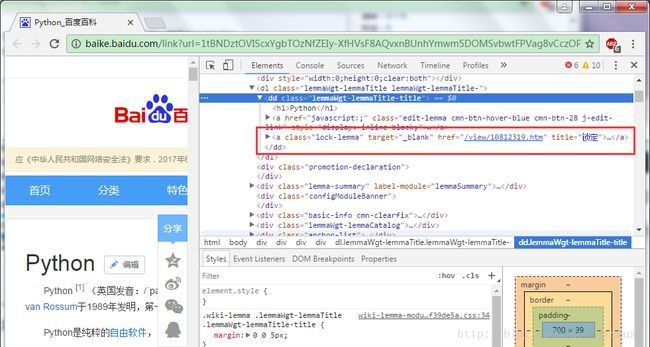
(1)链接分析
href=”/view/10812319.htm” 是一个不完整的url, 在代码中需要拼接成完整的 baike.baidu.com/view/10812319.htm 才能进行后续的访问。
(2)标题分析
标题内容在< dd class> 下的 < h1 > 子标签中。
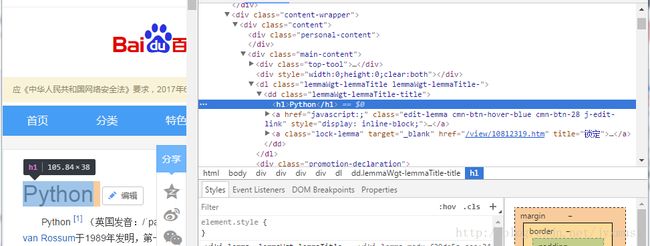
(3)简介分析
可看到简介内容在< class=”lemma-summary” > 下
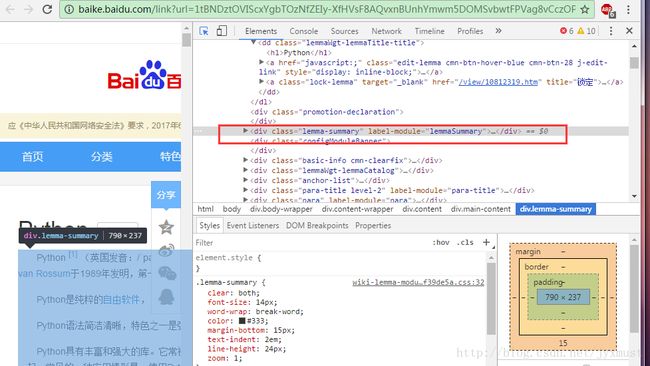
(4)查看编码方式
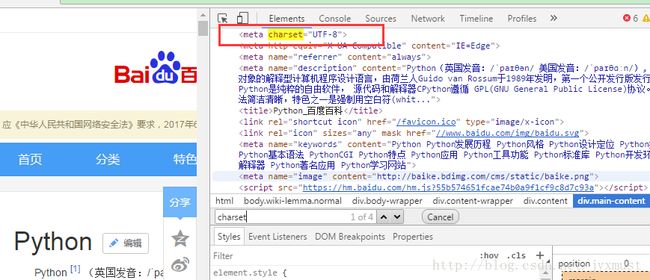
(5)分析目标汇总

2、编写代码
调度程序:spyder_main.py
from baike_spider import html_downloader
from baike_spider import html_outputer
from baike_spider import html_parser
from baike_spider import url_manager
class SpiderMain(object):
# 构造函数,初始化
def __init__(self):
self.urls = url_manager.UrlManager() # url管理器
self.downLoader = html_downloader.HtmlDownloader() # 下载器
self.parser = html_parser.HtmlParser() # 解析器
self.outputer = html_outputer.HtmlOutputer() # 输出器
# root_url入口url
def craw(self, root_url):
count = 1 # 记录当前爬去的第几个url
self.urls.add_new_url(root_url)
while self.urls.has_new_url(): # 判断有没有ur
try:
new_url = self.urls.get_new_url() # 如果有url,就添加到urls
print("craw %s : %s" % (count, new_url))
html_cont = self.downLoader.download(new_url) # 下载的页面数据
new_urls, new_data = self.parser.parse(new_url, html_cont) # 解析
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data) # 收集
if count == 1000:
break
count = count + 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == '__main__':
root_url = 'https://jingyan.baidu.com/article/2c8c281df0afd00008252aa7.html'
obj_spider = SpiderMain()
obj_spider.craw(root_url)
URL管理器:url_manager.py
class UrlManager(object):
# 维护两个列表,待爬取列表,爬取过的列表
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url): # 向管理器添加新的url
if url is None:
return
# 该url即不在待爬取的列表也不在已爬取的列表
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url) # 用来待爬取
def add_new_urls(self, urls): # 向管理器中添加批量url
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self): # 判断管理器是否有新的url
# 如果待爬取的列表不等于0就有
return len(self.new_urls) != 0
def get_new_url(self): # 从管理器获取新的url
new_url = self.new_urls.pop() # 从待爬取url集合中取一个url,并把这个url从集合中移除
self.old_urls.add(new_url) # 把这个url添加到已爬取的url集合中
return new_url
HTML下载器:html_downloader.py
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return
response = urllib.request.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
HTML解析器:html_parser.py
from bs4 import BeautifulSoup
import re
import urllib.parse
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup) # 解析url列表
new_data = self._get_new_data(page_url, soup) # 解析数据
return new_urls, new_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# /view/123.html
links = soup.find_all('a', href=re.compile(r'/view/[a-zA-Z0-9]+\.htm')) # 获取所有的连接
# 得到所有词条的url
for link in links:
new_url = link['href'] # 获取链接
# 把new_url按照和paga_url合并成一个完整的url
new_full_url = urllib.parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
#获取标题与简介
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
# Python
HTML输出器:html_outputer.py
class HtmlOutputer(object):
def __init__(self):
self.datas = [] # 建立列表存放数据
def collect_data(self, data): # 收集数据
if data is None:
return
self.datas.append(data)
def output_html(self): # 用收集好输出到html文件中
fout = open('output.html', 'w', encoding='utf-8')# 写模式
fout.write("")
fout.write("")
fout.write("")
fout.write("") # 输出为表格形式
# ascii
for data in self.datas:
fout.write("")
fout.write("%s " % data['url']) # 输出url
fout.write('%s ' % data['title'])
fout.write('%s ' % data['summary'])
fout.write(" ")
fout.write("
")
fout.write("")
fout.write("") # 闭合标签
fout.close()
