乘法器
在C语言,做乘法就是简单的一个*号。其实CPU是不认这个*号的,那么CPU是如何实现这个乘法?
把*号翻译成汇编,就是一条乘法指令,如:MUL A B,这样就把A和B相乘了。
在经典的51单片机,一条MUL指令,需要4个机器周期才能得到结果。所以,乘法不是一瞬间就完成的。
请先阅读《定点与浮点》。
一、定点乘法。
定点乘法分为原码乘法和补码乘法两种。
1、原码乘法。

原码乘法较为简单,直接利用手工计算的过程即可。主要使用了加法器和移位寄存器。
可以看出,随着乘数位宽的增加,所以需要的时钟周期也增多。
上图的方法为左移相加,消耗的寄存器较多,可以改进为右移相加。
上图方法为无符数乘法,如果是有符号数,则单独处理符号位(异位运算),其余的,按照无符号数处理。
2、补码乘法。
补码乘法主要有booth乘法。
由于booth乘法的推导过程较为复杂,而且也可以不了解其过程,所以下面给出booth乘法的运算规则。

该算法对应的逻辑原理图(简图),如下图所示。

二、乘法器结构的改进。
1、高基乘法。
上面1、2两点所说的乘法器均为一位乘法(每次计算只移动一bit)。
高基乘法可以一次性移动2位或以上,这样,可以节省计算时间,但是消耗的面积也会更多,遵循速度面积平衡互换原则。
高基乘法的计算过程,如下图所示。

2、阵列乘法。
阵列乘法计算速度快,但是占用的面积很大,适合ASIC下实现。如下图所示。

3、Wallace树。
前面说到的乘法都要把部分积累加,如:原码一位乘法,所使用的加法器占用面积较多,这时可以使用Wallace树。

三、浮点乘法器。
浮点乘法器可以使用IEEE754标准,其计算过程可以分为以下四步。如下图所示。

其实1、2两点不用说了,第3步其实就是前面定点乘法的计算步骤。
规格化可以增加有效位的位数,提高运算精度。规格化的过程,可以参考下图所示。


因为尾数相乘之后,需要进行舍入处理,才能保存为相同的浮点格式。舍入方法可以参考下图所示。

可以看出,浮点数乘法要比定位数乘法要复杂的多。
四、复数乘法。
复数乘法器是FFT算法的基本单元。而复数乘法可以转化为实数乘法(就是前面一、二两点所说的乘法)。
先看看复数乘法的公式。
![]() 。
。
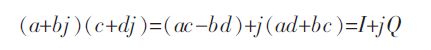
![]()
可以看出直接公式计算,需要消耗4个乘法器和2个加法器,占用资源较多。
可以对I和Q做以下分解:

可以看出(a-b)这个结果可以重复使用,只要计算一次即可。这样一来,复数乘法只需要3个乘法器和5个加法器。
乘法器位宽越长,利用IQ分解的方法比直接计算的方法要更节省资源。
五、FPGA中的乘法器。
在FPGA中也能实现上述的乘法器,虽然用逻辑写一个并不复杂,但是毕竟是用LE实现,跑不了多高的速度。
所以,一般使用硬核乘法器,但是硬核乘法器也只支持原码乘法。而补码乘法、浮点乘法、复数乘法,你得使用IP或者自己写一个了。
不推荐使用*号来实现乘法。
1、输入、输出的位宽没有明确给出,容易出错。
2、不容易从代码中观察到一共使用多少个乘法器,需要综合后才知道。
3、设计不满足需求时,不便于更换算法,如:把定点乘法换成浮点乘法。
4、完全由综合器随意实现,不容易得知乘法器的技术指标。
推荐使用硬核乘法器来代替*号,并用例化语句调用它。