tensorflow+inceptionv3图像分类网络结构的解析与代码实现【附下载】
论文链接:论文地址
ResNet传送门:Resnet-cifar10
DenseNet传送门:DenseNet
SegNet传送门:Segnet-segmentation
深度学习的火热,使得越来越多的科研人员投入到其中。而作为各种应用类型的网络基础,图像分类的网络结构有许多,从AlexNet开始,到VGG-Net,到GoogleNet,到ResNet,denseNet等。网络结构在不断地改进,也在不断地趋于稳定。新的单纯地图像分类结构越来越少(可能是分类效果已经达到了一定的需求)。本文主要讲解GoogleNet改进后的Inceptionv3网络结构。其网络结构如下所示:
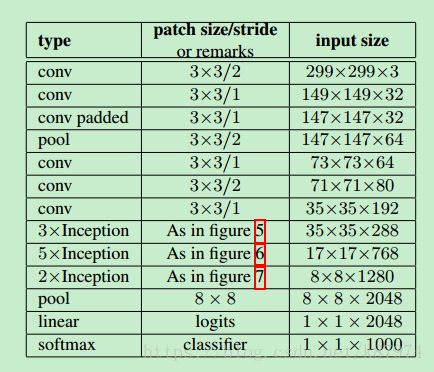
该网络在ILSVRC 2012的分类挑战上能获得5.6%的top-5 error。在参数量方面远小于VGG-Net,所以能有更块地训练速度以及不错的分类精度。文章中提到了4个通用的网络设计原则。
简单来讲就是:1、不要在网络的一开始使用过大的filter size,这会导致图像信息的丢失;2、高维数据的表示更容易在网络内进行局部处理,添加激活函数可以获得更多的disentangled features (不知道怎么翻译,有知道的大佬可否在评论底下说说?);3、空间聚合可以通过低维嵌入来完成,其表示能力没有太多或任何损失。(这里讲的就是网络中inception模块的分成4个branch最后聚合在一起所使用的原则);4、平衡网络的宽度和深度。
卷积核的分解
文章的核心部分在于其inception modules。而inception modules中又用到了factorization(将的filter size 分解成多个小的filter size),其原理可以用如下的图表示:
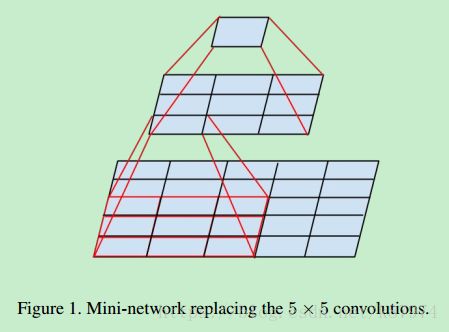
假设有一个5x5的feature map,我们可以直接用一个5x5的filter对其做卷积得到1个值,也可以通过两个3x3的filter对其做卷积得到1个值,但相较于前者,后者有更少地参数:3x3x2=18。前者为5x5=25。可以减少的参数量为:(25-18)/25=28%。
在此基础上,论文又提出可以使用使用非对称的卷积核来替代较大的卷积核。如下图所示:
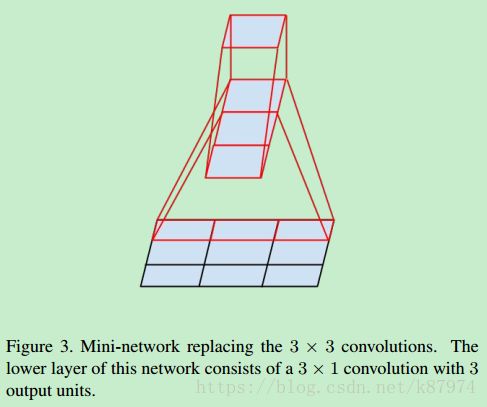
对于一个3x3的卷积核,可以使用一个1x3和一个3x1的组合来替代。一般化地话,可以使用1xn和nx1替代nxn的卷积核。
辅助分类器
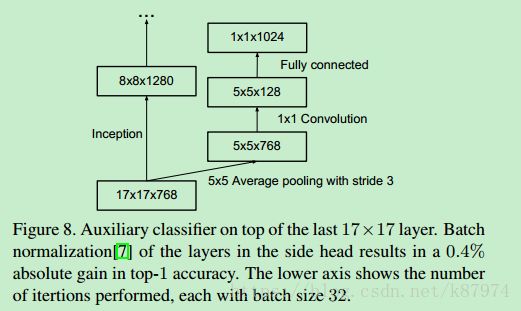
辅助分类器即除了主分类器之外,还在网络结构中的某一层,论文中为17x17x768的那一层,添加了一个分支用来做辅助分类。其思想来源于GoogleNet(Going deeper with convolutions) 。
网络尺寸的有效减少
在论文中给出的网络结构中,3xInception和5xInception以及5xInception和2xInception有一个尺寸的减少,其具体实现方法为如下所示:
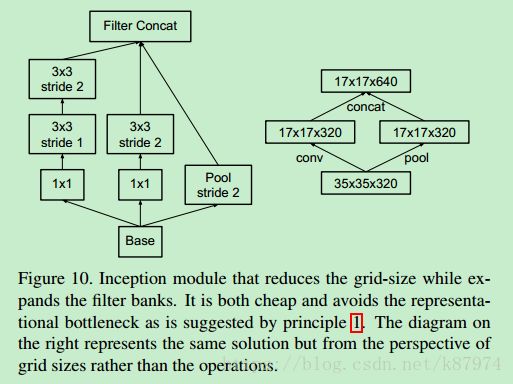
这里一并给出相关的代码实现:
def inception_grid_reduction_1(input,name=None):
with tf.variable_scope(name) as scope:
with tf.variable_scope("Branch_0"):
branch_0=conv_inception(input,shape = [1,1,288,384],name = '0a_1x1')
branch_0=conv_inception(branch_0,shape = [3,3,384,384],stride = [1,2,2,1],padding = 'VALID',name = '0b_3x3')
with tf.variable_scope('Branch_1'):
branch_1=conv_inception(input,shape = [1,1,288,64],name = '0b_1x1')
branch_1=conv_inception(branch_1,shape = [3,3,64,96],name = '0b_3x3')
branch_1=conv_inception(branch_1,shape = [3,3,96,96],stride = [1,2,2,1],padding = 'VALID',name = '0c_3x3')
with tf.variable_scope('Branch_2'):
branch_2=tf.nn.max_pool(input,ksize = (1,3,3,1),strides = [1,2,2,1],padding = 'VALID',name = 'maxpool_0a_3x3')
inception_out=tf.concat([branch_0,branch_1,branch_2],3)
c=1 # for debug
return inception_out其中conv_inception函数定义如下:
def conv_inception(input, shape, stride= [1,1,1,1], activation = True, padding = 'SAME', name = None):
in_channel = shape[2]
out_channel = shape[3]
k_size = shape[0]
with tf.variable_scope(name) as scope:
kernel = _variable('conv_weights', shape = shape)
conv = tf.nn.conv2d(input = input, filter = kernel, strides = stride, padding = padding)
biases = _variable('biases', [out_channel])
bias = tf.nn.bias_add(conv, biases)
if activation is True:
conv_out = tf.nn.relu(bias, name = 'relu')
else:
conv_out = bias
return conv_out_variable定义如下:
def _variable(name, shape):
"""Helper to create a Variable stored on CPU memory.
Args:
name: name of the variable
shape: list of ints
Returns:
Variable Tensor
"""
with tf.device('/gpu:0'):
var = tf.get_variable(name, shape)
return var下面给出网络中每一部分的解释以及实现:
文章中的卷积部分就不讲了,基本操作。主要讲讲inception部分怎么做。论文中共用到了三种Inception modules,即传统的inception(如GoogleNet所示),以及使用了非对称分解卷积核的inception,以及加入了filter expanded的inception。先说说传统的,如图所示:

这里Base的input size在网络中对应为35x35x288,有4个分支,其中pool为平均池化-avgpool,最后将4个分支串到一起,其代码实现如下:
def inception_block_tradition(input, name=None):
with tf.variable_scope(name) as scope:
with tf.variable_scope("Branch_0"):
branch_0=conv_inception(input,shape = [1,1,288,64],name = '0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1=conv_inception(input,shape = [1,1,288,48],name = '0a_1x1')
branch_1=conv_inception(branch_1,shape = [5,5,48,64],name = '0b_5x5')
with tf.variable_scope("Branch_2"):
branch_2=conv_inception(input,shape = [1,1,288,64],name = '0a_1x1')
branch_2=conv_inception(branch_2,shape = [3,3,64,96],name = '0b_3x3')
with tf.variable_scope('Branch_3'):
branch_3=tf.nn.avg_pool(input,ksize = (1,3,3,1),strides = [1,1,1,1],padding = 'SAME',name = 'Avgpool_0a_3x3')
branch_3=conv_inception(branch_3,shape = [1,1,288,64],name = '0b_1x1')
inception_out=tf.concat([branch_0,branch_1,branch_2,branch_3],3)
b=1 # for debug
return inception_out接下来是使用了非对称分解的Inception moduels,如下图所示:
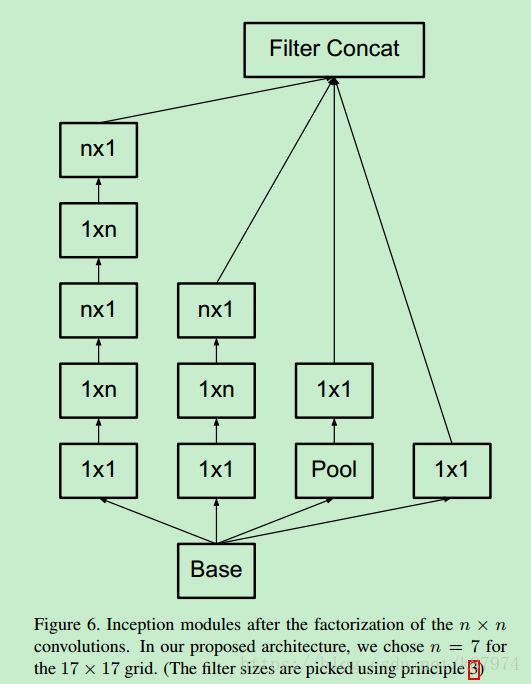
这里n=7,Base为17x17x768;pool为 3x3 stride为1的avgpool(同上);其代码实现如下:
def inception_block_factorization(input,name=None):
with tf.variable_scope(name) as scope:
with tf.variable_scope('Branch_0'):
branch_0=conv_inception(input,shape = [1,1,768,192],name = '0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1=conv_inception(input,shape = [1,1,768,128],name = '0a_1x1')
branch_1=conv_inception(branch_1,shape = [1,7,128,128],name = '0b_1x7')
branch_1=conv_inception(branch_1,shape = [7,1,128,128],name = '0c_7x1')
branch_1=conv_inception(branch_1,shape = [1,7,128,128],name = '0d_1x7')
branch_1=conv_inception(branch_1,shape = [7,1,128,192],name = '0e_7x1')
with tf.variable_scope('Branch_2'):
branch_2=conv_inception(input,shape = [1,1,768,128],name = '0a_1x1')
branch_2=conv_inception(branch_2,shape = [1,7,128,128],name = '0b_1x7')
branch_2=conv_inception(branch_2,shape = [7,1,128,192],name = '0c_7x1')
with tf.variable_scope('Branch_3'):
branch_3=tf.nn.avg_pool(input,ksize = (1,3,3,1),strides = [1,1,1,1],padding = 'SAME',name = 'Avgpool_0a_3x3')
branch_3=conv_inception(branch_3,shape = [1,1,768,192],name = '0b_1x1')
inception_out=tf.concat([branch_0,branch_1,branch_2,branch_3],3)
d=1 # for debug
return inception_out接下来使用了filter expanded的inception,如图所示:
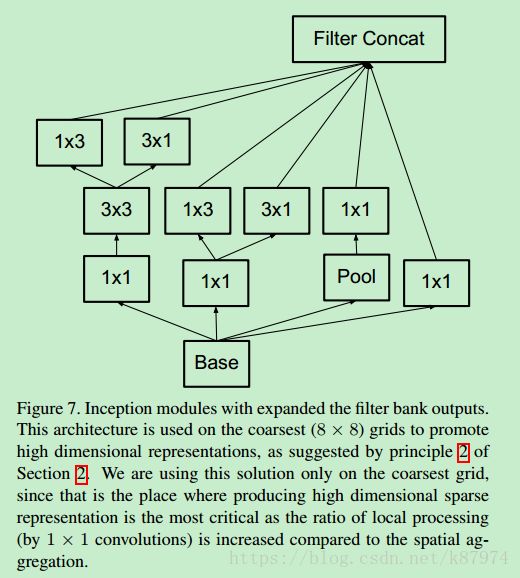
也是4个分支,pool同上。其代码实现如下:
def inception_block_expanded(input,name=None):
with tf.variable_scope(name) as scope:
with tf.variable_scope('Branch_0'):
branch_0=conv_inception(input,shape = [1,1,2048,320],name = '0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1=conv_inception(input,shape = [1,1,2048,448],name = '0a_1x1')
branch_1=conv_inception(branch_1,shape = [3,3,448,384],name = '0b_3x3')
branch_1=tf.concat([conv_inception(branch_1,shape = [1,3,384,384],name = '0c_1x3'),
conv_inception(branch_1,shape = [3,1,384,384],name = '0d_3x1')],3)
with tf.variable_scope('Branch_2'):
branch_2=conv_inception(input,shape = [1,1,2048,384],name = '0a_1x1')
branch_2=tf.concat([conv_inception(branch_2,shape = [1,3,384,384],name = '0b_1x3'),
conv_inception(branch_2,shape = [3,1,384,384],name = '0c_3x1')],3)
with tf.variable_scope('Branch_3'):
branch_3=tf.nn.avg_pool(input,ksize = (1,3,3,1),strides = [1,1,1,1],padding = 'SAME',name = 'Avgpool_0a_3x3')
branch_3=conv_inception(branch_3,shape = [1,1,2048,192],name = '0b_1x1')
inception_out=tf.concat([branch_0,branch_1,branch_2,branch_3],3)
e=1 # for debug
return inception_out经过上述操作可得到8x8x2048的feature maps,根据论文中的结构,对其做池化操作并加入1x1的卷积得到我们最终需要的1x1xnum_class即可,其实现如下(不唯一):
with tf.variable_scope('Logits'):
net=tf.nn.avg_pool(net,ksize = [8,8,2048,2048],strides = [1,1,1,1],padding = 'VALID',name = 'Avgpool_1a_8x8')
# 1x1x2048
net=tf.nn.dropout(net,keep_prob = dropout_keep_prob,name = 'Dropout_1b')
end_points['PreLogits']=net
# 2048
logits=conv_inception(net,shape = [1,1,2048,num_classes],activation = False,name = 'conv_1c_1x1')
end_points['Logits']=logits
end_points['Predictions']=tf.nn.softmax(logits,name = 'Predictions')
return logits,end_points论文中提及到的优化方法有SGD和RMSProp。可以随便选择,论文中得到的最佳模型为使用了RMSProp的方法。
附上代码下载地址:
tensorflow+inceptionv3
PS:数据集需要自行提供。
如果你觉得有用,帮忙扫个红包支持一下吧: