Linux - 进程空间
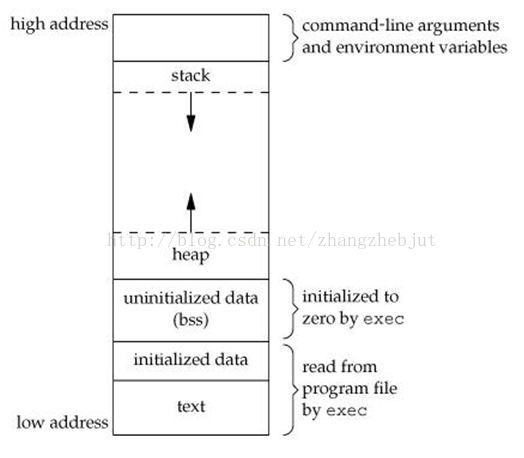
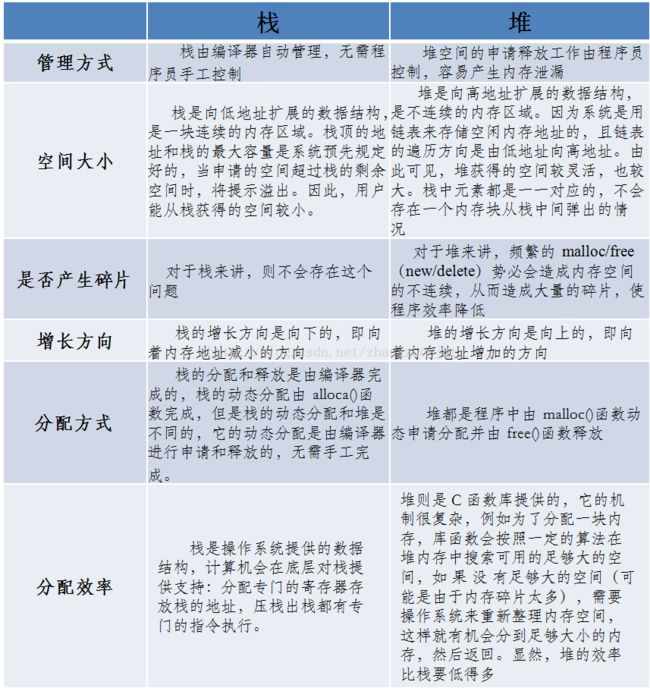
程序段(Text):程序代码在内存中的映射,存放函数体的二进制代码。
初始化过的数据(Data):在程序运行初已经对变量进行初始化的数据。
未初始化过的数据(BSS):在程序运行初未对变量进行初始化的数据。
栈 (Stack):存储局部、临时变量,函数调用时,存储函数的返回指针,用于控制函数的调用和返回。在程序块开始时自动分配内存,结束时自动释放内存,其操作方式类似于数据结构中的栈。
堆 (Heap):存储动态内存分配,需要程序员手工分配,手工释放.注意它与数据结构中的堆是两回事,分配方式类似于链表。
内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。 虽然内核空间占据了每个虚拟空间中的最高1GB字节,但映射到物理内存却总是从最低地址(0x00000000),另外, 使用虚拟地址可以很好的保护 内核空间被用户空间破坏,虚拟地址到物理地址转换过程有操作系统和CPU共同完成(操作系统为CPU设置好页表,CPU通过MMU单元进行地址转换)。
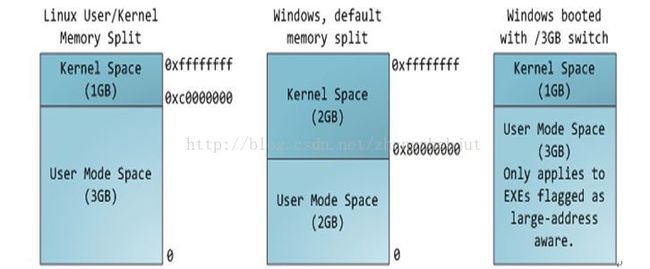
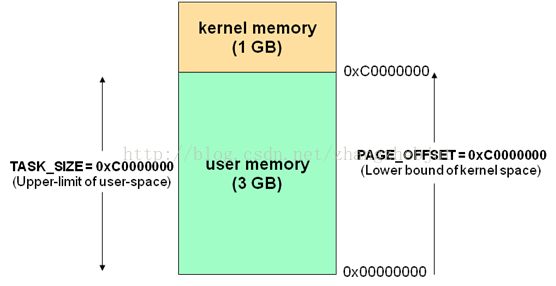
相对地,应用程序则是在“用户空间”中运行。运行在用户空间的应用程序只能看到允许它们使用的部分系统资源,并且不能使用某些特定的系统功能,也不能直接访问内核空间和硬件设备,以及其他一些具体的使用限制。
将用户空间和内核空间置于这种非对称访问机制下有很好的安全性,能有效抵御恶意用户的窥探,也能防止质量低劣的用户程序的侵害,从而使系统运行得更稳定可靠。
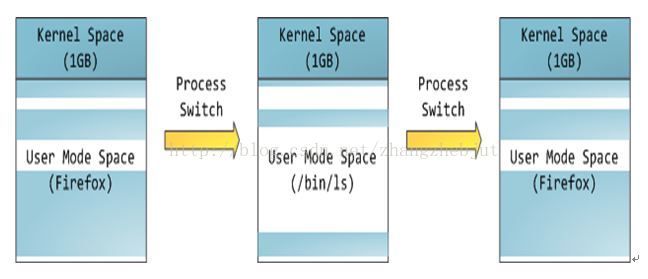
上图中蓝色区域表示映射到物理内存的虚拟地址,而白色区域表示未映射的部分。可以看出,Firefox使用了相当多的虚拟地址空间,因为它占用内存较多。
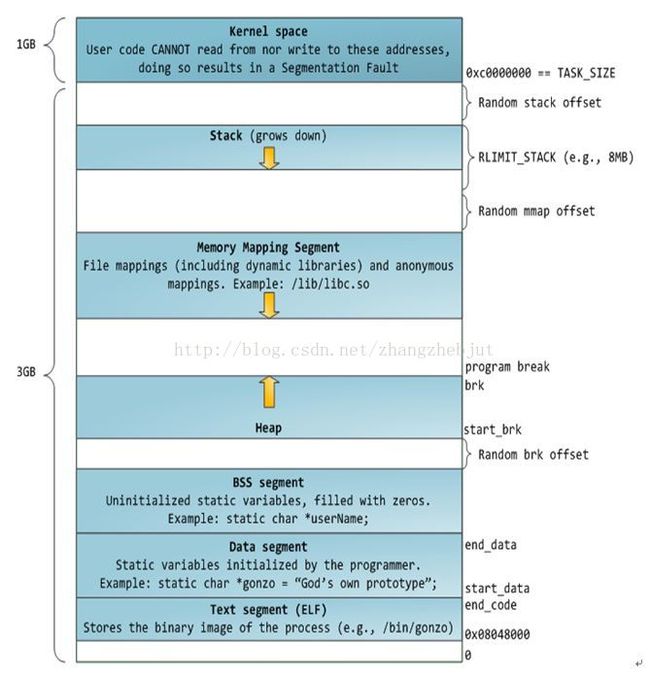

进程地址空间中最顶部的段是栈,大多数编程语言将之用于存储函数参数和局部变量。调用一个方法或函数会将一个新的栈帧(stack frame)压入到栈中,这个栈帧会在函数返回时被清理掉。由于栈中数据严格的遵守FIFO的顺序,这个简单的设计意味着不必使用复杂的数据结构来追踪栈中的内容,只需要一个简单的指针指向栈的顶端即可,因此压栈(pushing)和退栈(popping)过程非常迅速、准确。进程中的每一个线程都有属于自己的栈。
通过不断向栈中压入数据,超出其容量就会耗尽栈所对应的内存区域,这将触发一个页故障(page fault),而被Linux的expand_stack()处理,它会调用acct_stack_growth()来检查是否还有合适的地方用于栈的增长。如果栈的大小低于RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情。这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会栈溢出(stack overflow),程序收到一个段错误(segmentation fault)。

你可以通过阅读文件/proc/pid_of_process/maps来检验一个Linux进程中的内存区域。记住:一个段可能包含许多区域。比如,每个内存映射文件在mmap段中都有属于自己的区域,动态库拥有类似BSS和数据段的额外区域。有时人们提到“数据段”,指的是全部的数据段+BSS+堆。
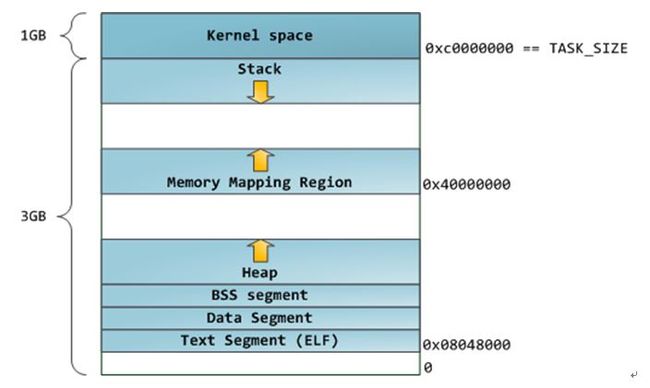
你还可以通过nm和objdump命令来察看二进制镜像,打印其中的符号,它们的地址,段等信息。最后需要指出的是,前文描述的虚拟地址布局在linux中是一种“灵活布局”,而且作为默认方式已经有些年头了,它假设我们有值RLIMT_STACK。但是,当没有该值得限制时,Linux退回到“经典布局”,如下图所示:
C语言程序实例分析如下所示:
附录:
程序段(Text):程序代码在内存中的映射,存放函数体的二进制代码。
初始化过的数据(Data):在程序运行初已经对变量进行初始化的数据。
未初始化过的数据(BSS):在程序运行初未对变量进行初始化的数据。
栈 (Stack):存储局部、临时变量,函数调用时,存储函数的返回指针,用于控制函数的调用和返回。在程序块开始时自动分配内存,结束时自动释放内存,其操作方式类似于数据结构中的栈。
堆 (Heap):存储动态内存分配,需要程序员手工分配,手工释放.注意它与数据结构中的堆是两回事,分配方式类似于链表。
内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。 虽然内核空间占据了每个虚拟空间中的最高1GB字节,但映射到物理内存却总是从最低地址(0x00000000),另外, 使用虚拟地址可以很好的保护 内核空间被用户空间破坏,虚拟地址到物理地址转换过程有操作系统和CPU共同完成(操作系统为CPU设置好页表,CPU通过MMU单元进行地址转换)。
相对地,应用程序则是在“用户空间”中运行。运行在用户空间的应用程序只能看到允许它们使用的部分系统资源,并且不能使用某些特定的系统功能,也不能直接访问内核空间和硬件设备,以及其他一些具体的使用限制。
将用户空间和内核空间置于这种非对称访问机制下有很好的安全性,能有效抵御恶意用户的窥探,也能防止质量低劣的用户程序的侵害,从而使系统运行得更稳定可靠。
上图中蓝色区域表示映射到物理内存的虚拟地址,而白色区域表示未映射的部分。可以看出,Firefox使用了相当多的虚拟地址空间,因为它占用内存较多。
进程地址空间中最顶部的段是栈,大多数编程语言将之用于存储函数参数和局部变量。调用一个方法或函数会将一个新的栈帧(stack frame)压入到栈中,这个栈帧会在函数返回时被清理掉。由于栈中数据严格的遵守FIFO的顺序,这个简单的设计意味着不必使用复杂的数据结构来追踪栈中的内容,只需要一个简单的指针指向栈的顶端即可,因此压栈(pushing)和退栈(popping)过程非常迅速、准确。进程中的每一个线程都有属于自己的栈。
通过不断向栈中压入数据,超出其容量就会耗尽栈所对应的内存区域,这将触发一个页故障(page fault),而被Linux的expand_stack()处理,它会调用acct_stack_growth()来检查是否还有合适的地方用于栈的增长。如果栈的大小低于RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情。这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会栈溢出(stack overflow),程序收到一个段错误(segmentation fault)。
你可以通过阅读文件/proc/pid_of_process/maps来检验一个Linux进程中的内存区域。记住:一个段可能包含许多区域。比如,每个内存映射文件在mmap段中都有属于自己的区域,动态库拥有类似BSS和数据段的额外区域。有时人们提到“数据段”,指的是全部的数据段+BSS+堆。
你还可以通过nm和objdump命令来察看二进制镜像,打印其中的符号,它们的地址,段等信息。最后需要指出的是,前文描述的虚拟地址布局在linux中是一种“灵活布局”,而且作为默认方式已经有些年头了,它假设我们有值RLIMT_STACK。但是,当没有该值得限制时,Linux退回到“经典布局”,如下图所示:
C语言程序实例分析如下所示:
附录: